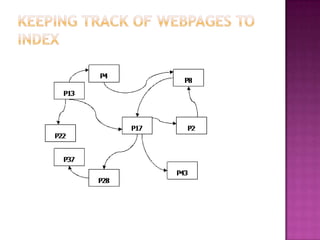
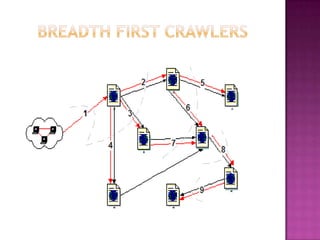
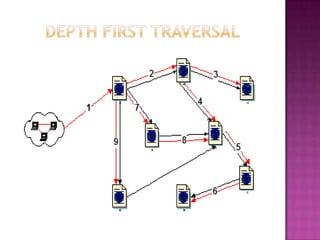
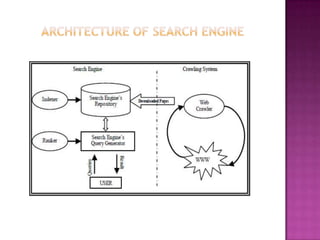
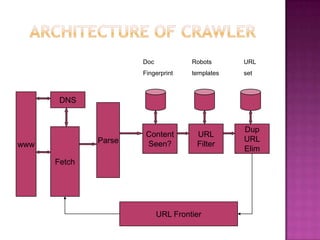
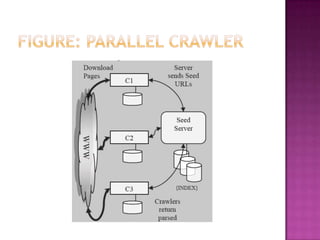
The document discusses web crawlers, which are programs that download web pages to help search engines index websites. It explains that crawlers use strategies like breadth-first search and depth-first search to systematically crawl the web. The architecture of crawlers includes components like the URL frontier, DNS lookup, and parsing pages to extract links. Crawling policies determine which pages to download and when to revisit pages. Distributed crawling improves efficiency by using multiple coordinated crawlers.












































































![[LvDuit//Lab] Crawling the web](https://cdn.slidesharecdn.com/ss_thumbnails/crawlingtheweb-140901103920-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























