
Downloaded 21 times









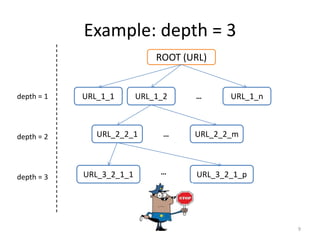









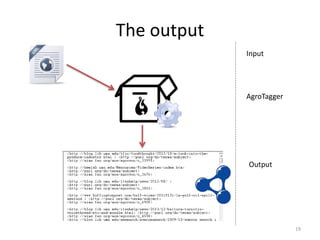









This webinar outlines the Semagrow project, which utilizes a web crawler and agrotagger to discover and tag agricultural resources online. The web crawler uses Apache Nutch to identify URLs and the agrotagger extracts keywords using the Agrovoc thesaurus, generating RDF triples. Future steps include refining data combinations and evaluating the outcomes of the previously discovered resources.






















































































