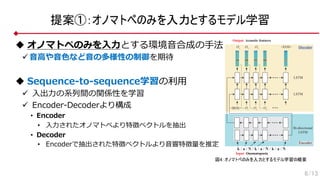
提案①:オノマトペのみを入力とするモデル学習
u オノマトペのみを⼊⼒とする環境⾳合成の⼿法
ü ⾳⾼や⾳⾊など⾳の多様性の制御を期待
uSequence-to-sequence学習の利⽤
ü ⼊出⼒の系列間の関係性を学習
ü Encoder-Decoderより構成
• Encoder
• ⼊⼒されたオノマトペより特徴ベクトルを抽出
• Decoder
• Encoderで抽出された特徴ベクトルより⾳響特徴量を推定
6/13
Input: Onomatopoeia
LSTM
Bi-directional
LSTM
<BOS> O1
O2
O3
Output: Acoustic features
O1
O2
O3
<EOS>
LSTM
k / a / N / k / a / N / k / a / N
Encoder
Decoder
図4:オノマトペのみを入力とするモデル学習の概要
7.
提案②:オノマトペ + 音響イベントラベル
を入力とするモデル学習
uオノマトペだけでは音響イベントの種類を制御困難
ü 同一オノマトペが複数の音響イベントに対応することもある
• e.g.) ⾵船が割れる⾳「パン」
ピストルの⾳ 「パン」
uオノマトペに加え⾳響イベントラベルも使⽤
ü Encoderの出⼒に⾳響イベントの情報を付加
• ⾳響イベントラベルをOne-hot表現して利⽤
7/13
図5:オノマトペ + 音響イベントラベル を入
力とするモデル学習
オノマトペのみを⼊⼒とする
とどちらの⾳響イベントの⾳
か制御困難
Input: Onomatopoeia
LSTM
Bi-directional
LSTM
<BOS>
Output: Acoustic features
LSTM
Fully
connected
Concat
c
Sound
Event
label
Event label Conditioning
Fully
connected
Concat
k / a / N / k / a / N / k / a / N
Encoder
Decoder
l1
l2
l3
l4
l5
lT
o1
o2
o3
oT'
o1
o2
oT'-1
音響イベントの種類の制御を期待
8.
合成音の品質に関する評価実験
u 主観評価実験を実施
ü 実験Ⅰ︓環境⾳の品質に関する評価
ü実験Ⅱ︓オノマトペに対する環境⾳の評価
ü 実験Ⅲ︓⾳響イベントラベルを加えることによる⽣成⾳の変化の検証
u 各実験における1⼿法あたりの評価数
ü 実験Ⅰ︓1,500サンプル(50⾳×30⼈)
ü 実験Ⅱ︓3,000サンプル(100⾳×30⼈)
ü 実験Ⅲ︓1,300サンプル(26⾳×50⼈)
u モデル学習に使⽤したデータセット
ü ⾳データ︓RWCP 実環境⾳声・⾳響データベース[Nakamura+, 1999]
• 合計950⾳ (10種類×95⾳)
ü オノマトペ︓RWCP-SSD-Onomatopoeia [Okamoto+, 2020]
• 合計14,250個のオノマトペを使⽤ (950⾳×15オノマトペ)
8/13
表2:実験条件
表1:使用した音響イベント
9.
K
a
n
a
W
a
v
e
S
e
q
2
S
e
q
W
a
v
e
N
e
t
S
e
q
2
S
e
q
+
e
v
e
n
t
l
a
b
e
l
s
N
a
t
u
r
a
l
s
o
u
n
d
s
1
2
3
4
5
MOS
score
on
naturalness
非常に自然である
非常に不自然である
○
オノマトペ
音響イベント
ラベル
○ ○
- -○
○
-
システムへの入力
実験Ⅰ:環境音の品質に関する評価
9/13
WaveNetによる合成音と同程度の品質を獲得
図6:環境音の全体的な印象に関する平均スコアと標準偏差 図7:環境音の自然性に関する平均スコアと標準偏差
u 内容︓⾳を被験者に提⽰し,各指標5段階で評価
Natural sounds:
・データセットに含まれる⾳
WaveNet:
・⾳響イベントラベルのみを⼊⼒とする⼿法
KanaWave:
・オノマトペから環境⾳を⽣成する従来法
・オノマトペと環境⾳が1対1で対応づいており,
波形接続のような⽅式で⾳を⽣成
Seq2Seq:
・オノマトペのみを⼊⼒とした提案⼿法
Seq2Seq + Event Conditioning︓
・オノマトペと⾳響イベントラベルを⼊⼒とし
た提案⼿法
K
a
n
a
W
a
v
e
S
e
q
2
S
e
q
W
a
v
e
N
e
t
S
e
q
2
S
e
q
+
e
v
e
n
t
l
a
b
e
l
s
N
a
t
u
r
a
l
s
o
u
n
d
s
1
2
3
4
5
MOS
score
on
overall
impression
非常に良い
非常に悪い
Natural Sound
Conventional
Proposed
○
オノマトペ
音響イベント
ラベル
○ ○
- - ○
○
-
システムへの入力
10.
K
a
n
a
W
a
v
e
S
e
q
2
S
e
q
S
e
q
2
S
e
q
+
e
v
e
n
t
l
a
b
e
l
s
N
a
t
u
r
a
l
s
o
u
n
d
s
1
2
3
4
5
Expressiveness
score
非常に表現できている
非常に表現できていない
○
オノマトペ
音響イベント
ラベル
○ ○
- -○
システムへの入力
実験Ⅱ:オノマトペに対する環境音の評価
10/13
u 内容︓オノマトペと⾳を被験者に提⽰し,各指標5段階で評価
Natural sounds:
・データセットに含まれる⾳
KanaWave:
・オノマトペから環境⾳を⽣成する従来法
Seq2seq:
・オノマトペのみを⼊⼒とした提案⼿法
Seq2seq + Event Conditioning︓
・オノマトペと⾳響イベントラベルを⼊⼒
とした提案⼿法
従来法 (KanaWave)よりも許容度,表現性ともに高いスコアを獲得
図9:オノマトペに対する環境音の表現性の平均スコアと標準偏差
図8:オノマトペに対する環境音の許容度の平均と標準偏差
⼊⼒オノマトペ︓「ティリリリリリンッ」
⾳響イベント︓「⽬覚まし時計の⾳」
K
a
n
a
W
a
v
e
S
e
q
2
S
e
q
S
e
q
2
S
e
q
+
e
v
e
n
t
l
a
b
e
l
s
N
a
t
u
r
a
l
s
o
u
n
d
s
1
2
3
4
5
Acceptance
score
Natural Sound
Conventional
Proposed
○
オノマトペ
音響イベント
ラベル
○ ○
- - ○
システムへの入力
非常に許容できる
非常に許容できない
まとめ
u オノマトペからの環境⾳合成⼿法を提案
ü ⼿法①︓オノマトペのみを⼊⼒とする合成⼿法
üオノマトペを表現した⾳の⽣成を実現
ü ⼿法②︓オノマトペと⾳響イベントラベルを⼊⼒とする⼿法
ü オノマトペでの制御に加え,⾳響イベントの制御も可能に︕︕
u 環境⾳に対する品質評価にて,従来法よりも⾼い合成品質を獲得
u オノマトペに対する環境⾳の評価にて,従来法より⾼いスコアを獲得
⾳響イベントごとに⽣成⾳の詳細な分析を⾏う
13/13
今後の予定
https://y-okamoto1221.github.io/IJCNN_Demonstration_jp/
生成音のデモ


![深層学習を用いた従来の環境音合成
u ⾳響イベントラベルを⼊⼒とする環境⾳合成 [Okamoto+, 2019]
「⾵の⾳」,「⾬⾳」といった⾳の種類を表すラベル
3/13
ベルの音
ひげ剃りの動作音
太鼓の音
笛の音
目覚まし時計の音
紙を引き裂く音
Input: Sound event label Output: synthesized sound
WaveNet
生成する音の種類(音響イベント)が制御可能
生成する音の多様性(音高,音色など)が制御困難
→ 環境音は同じ音響イベントでも音の特徴は多様
柔軟に生成音を制御できる手法が必要!](https://image.slidesharecdn.com/asj2021sokamotoslideshare-210311074316/85/Onoma-to-wave-3-320.jpg)



![合成音の品質に関する評価実験
u 主観評価実験を実施
ü 実験Ⅰ︓環境⾳の品質に関する評価
ü 実験Ⅱ︓オノマトペに対する環境⾳の評価
ü 実験Ⅲ︓⾳響イベントラベルを加えることによる⽣成⾳の変化の検証
u 各実験における1⼿法あたりの評価数
ü 実験Ⅰ︓1,500サンプル(50⾳×30⼈)
ü 実験Ⅱ︓3,000サンプル(100⾳×30⼈)
ü 実験Ⅲ︓1,300サンプル(26⾳×50⼈)
u モデル学習に使⽤したデータセット
ü ⾳データ︓RWCP 実環境⾳声・⾳響データベース[Nakamura+, 1999]
• 合計950⾳ (10種類×95⾳)
ü オノマトペ︓RWCP-SSD-Onomatopoeia [Okamoto+, 2020]
• 合計14,250個のオノマトペを使⽤ (950⾳×15オノマトペ)
8/13
表2:実験条件
表1:使用した音響イベント](https://image.slidesharecdn.com/asj2021sokamotoslideshare-210311074316/85/Onoma-to-wave-8-320.jpg)












![[DL輪読会]DNN-based Source Enhancement to Increase Objective Sound Quality Asses...](https://cdn.slidesharecdn.com/ss_thumbnails/20180831dldnnbasedsourceenhancementtoincreaseobjectivesoundqualityassessmentscoresubmission-180831001410-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)









![音声分析合成[7].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/random-220616065523-18dffa84-thumbnail.jpg?width=640&height=640&fit=bounds)














