Downloaded 15 times



![Motivation
Bale highlands are known for their
mono-cropping production system:
wheat and barley dominated.
Mono-cropping:
• Growing one crop year after year on
the same plot of land
• Non-diverse rotations – Only a
single crop is grown at a time within
a field.
• Associated with two problems:
• Soil degradation
• Increased vulnerability to risk
• Implies lower efficiency [broadly
defined] compared to poly-cropping
systems.](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-4-320.jpg)
![The key questions
• Our questions
• How efficient are improved faba bean and field pea growers compared
to non-growers?
• If there is a considerable difference in efficiency, can we attribute this
to the inclusion of improved faba bean and field pea varieties?
• Does crop productivity [crop output per unit of the most limiting
input] vary between improved faba bean and field pea growers and
non-growers?
• Our objective
• To empirically show whether the adoption of improved food legume
varieties increases the technical efficiency of crop production.](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-5-320.jpg)


![SF Model (2)
• Two step estimation
1- estimates of the model parameters ĥ are obtained by
maximizing the LL-function l(ĥ)
2 – point estimates of inefficiency can be obtained thru the
mean (or the mode) of the conditional distribution
where
• Post-estimation procedures to compute efficiency
parameters:
– Jondrow et al (1982): TEi = 1-E[ui|εi]
– Battese and Coelli (1988): TEi = E[exp(-ui|εi)]
)ˆ|u(f ii
ˆxˆyˆ iii ](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-8-320.jpg)

![Analytical framework
2. Impact analysis
Where δi is impact [technical efficiency] on individual ‘i’;
A
iY Is potential outcome of adoption for individual ‘i’.
Is potential outcome of non-adoption for individual ‘i’.
N
iY
Let D denotes adoption decision (assumed to be binary) and
takes the value 1 for adopters (A) and 0 for non adopters (N).
N
i
A
ii YY ](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-10-320.jpg)
![2. Impact analysis
0DifY
1DifY
Y
i
N
i
i
A
i
i
)(*)(*][][ 01 DPATUDPATETYYEEATE N
i
A
ii
]1|[]1|[]1|[ i
N
ii
A
iii DYEDYEDEATET
]0D|Y[E]0D|Y[E]0D|[EATU i
N
ii
A
iii
ATET is identified only if E[YN|D=1]-E[YN|D=0]=0: That is the TEs of HHs
from the adopter and non-adopter groups would not differ in the
absence of the improved food legume varieties.
][ iD YEPOM ](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-11-320.jpg)
![2. Impact analysis
• In population terms, the average trt effect (ATE) is
• ATE = E[TEadopt – TEnonadopt] = E[TEadopt] – [TEnonadopt]
• Missing data problem – we only observe one of the potential outcomes:
– We observe TEadopt for adopting farm HHs.
– We observe TEnonadopt for non-adopting farm HHs.
• When the adoption level/treatment [0/1] is randomly assigned to farm HHs,
the potential outcomes are independent of the adoption level [0/1] .
– Assuming that adoption level [0/1] is randomly assigned is hardly convincing.
• Rather, we assume that adoption level is as good as randomly assigned after
conditioning on covariates. This is called conditional independence.
• In fact, we need only conditional mean independence [CMI] – that is after
conditioning on covariates, the adoption level does not affect the means of the
potential outcomes.
– CMI restricts the dependence b/n adoption model and the potential outcomes](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-12-320.jpg)


![Treatment-effects estimators employed
• Adjustment and weighting
– Regression adjustment [see: Lane and Nelder (1982); Cameron and Trivedi (2005, chap. 25);
Wooldridge (2010, chap. 21); and Vittinghoff, Glidden, Shiboski, and McCulloch (2012, chap. 9).]
– Inverse probability weighting [see: Imbens (2000); Hirano, Imbens, and Ridder (2003); Tan
(2010); Wooldridge (2010, chap. 19); van der Laan and Robins (2003); and Tsiatis (2006, chap. 6).]
– Inverse probability weighting with regression adjustment (IPWRA) [see:
Wooldridge, 2007; Wooldridge, 2010]
– Augmented inverse probability weighting (AIPW) [see:Robins, Rotnitzky, and
Zhao (1995); Bang and Robins (2005); Tsiatis (2006) and Tan (2010).]
• Matching estimators
– Nearest neighbor matching [see: Abadie et al. (2004); Abadie and Imbens (2006,
2011)].
– Propensity score (treatment probability) matching [See: Rosenbaum and
Rubin (1983); Abadie and Imbens (2012)].](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-15-320.jpg)




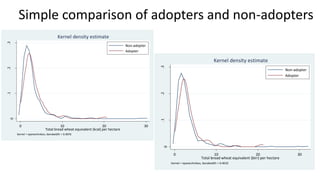
![Simple comparison of adopters and non-adopters02468
0 .2 .4 .6 .8 1
Technical efficiency via E[exp(-u)|e] (BC approach)
Non-adopter
Adopter
kernel = epanechnikov, bandwidth = 0.0221
Kernel density estimate
0246
Density
0 .2 .4 .6 .8 1
Technical efficiency via exp[-E(u|e)] (JLMS - approach)
Non-adopter
Adopter
kernel = epanechnikov, bandwidth = 0.0241
Kernel density estimate](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-20-320.jpg)

![Conclusions and further questions
• Very low adoption of improved legume varieties – particularly faba
bean and field pea.
• No relationship with efficiency no matter how the latter was
measured.
• No relationship with productivity per unit of limiting factor no
matter what conversion [energy or price] was used.
•We observed that complementary inputs are not being
used as per the recommendations.](https://image.slidesharecdn.com/icardaarbalesep2016-161011064813/85/Can-improved-food-legume-varieties-increase-technical-efficiency-in-crop-production-23-320.jpg)



The study investigates whether improved food legume varieties, particularly faba bean and field pea, enhance technical efficiency in crop production among smallholder farmers in the Bale Highlands of Ethiopia. Despite the importance of legumes in soil regeneration and food security, the findings reveal very low adoption rates of these improved varieties with no significant relationship to efficiency or productivity. The research highlights challenges in mono-cropping systems and raises further questions about agricultural practices in the region.

















![11.[1 13]adoption of modern agricultural production technologies by farm hous...](https://cdn.slidesharecdn.com/ss_thumbnails/11-1-13adoptionofmodernagriculturalproductiontechnologiesbyfarmhouseholdsinghana-120512235429-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































































