Downloaded 118 times
















![Example
● CREATE FOREIGN TABLE web_sessions(
key text,
values text[])
SERVER localredis
OPTIONS (tabletype hash,
tablekeyprefix 'web:');
SELECT * from web_sessions;](https://image.slidesharecdn.com/pgcon-redis-130928100131-phpapp02/75/PostgreSQL-and-Redis-talk-at-pgcon-2013-17-2048.jpg)










![redis_command and
redis_command_argv
● Thin layers over similarly named functions in
client library
● redis_command has max 4 arguments after
command string – for more use
redis_command_argv
● Might switch from VARIADIC text[] to
VARIADIC “any”](https://image.slidesharecdn.com/pgcon-redis-130928100131-phpapp02/75/PostgreSQL-and-Redis-talk-at-pgcon-2013-29-2048.jpg)

![Higher level functions
● redis_push_record
● con_num integer
● data record
● push_keys boolean
● key_set text
● key_prefix text
● key_fields text[]](https://image.slidesharecdn.com/pgcon-redis-130928100131-phpapp02/75/PostgreSQL-and-Redis-talk-at-pgcon-2013-31-2048.jpg)




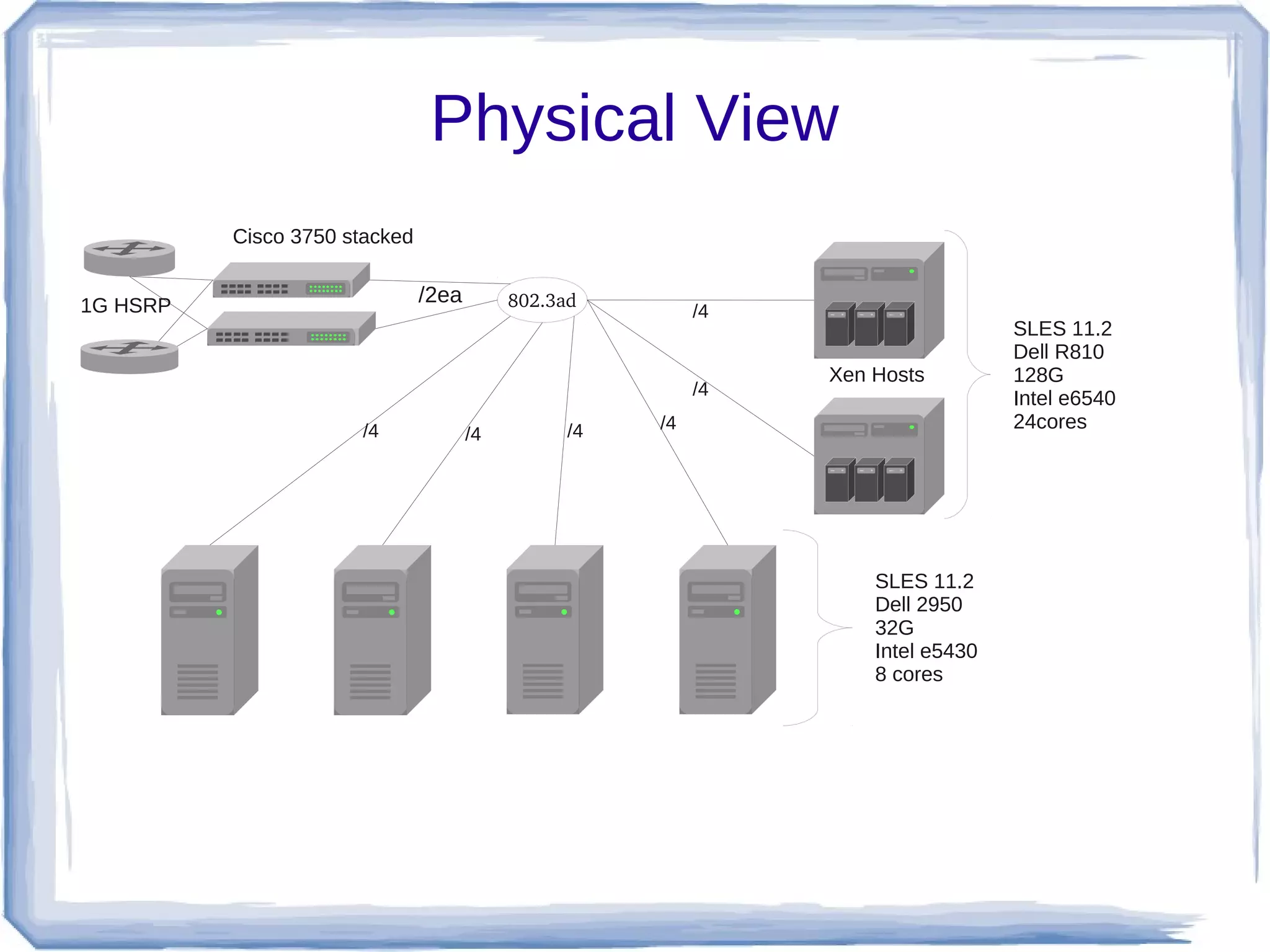
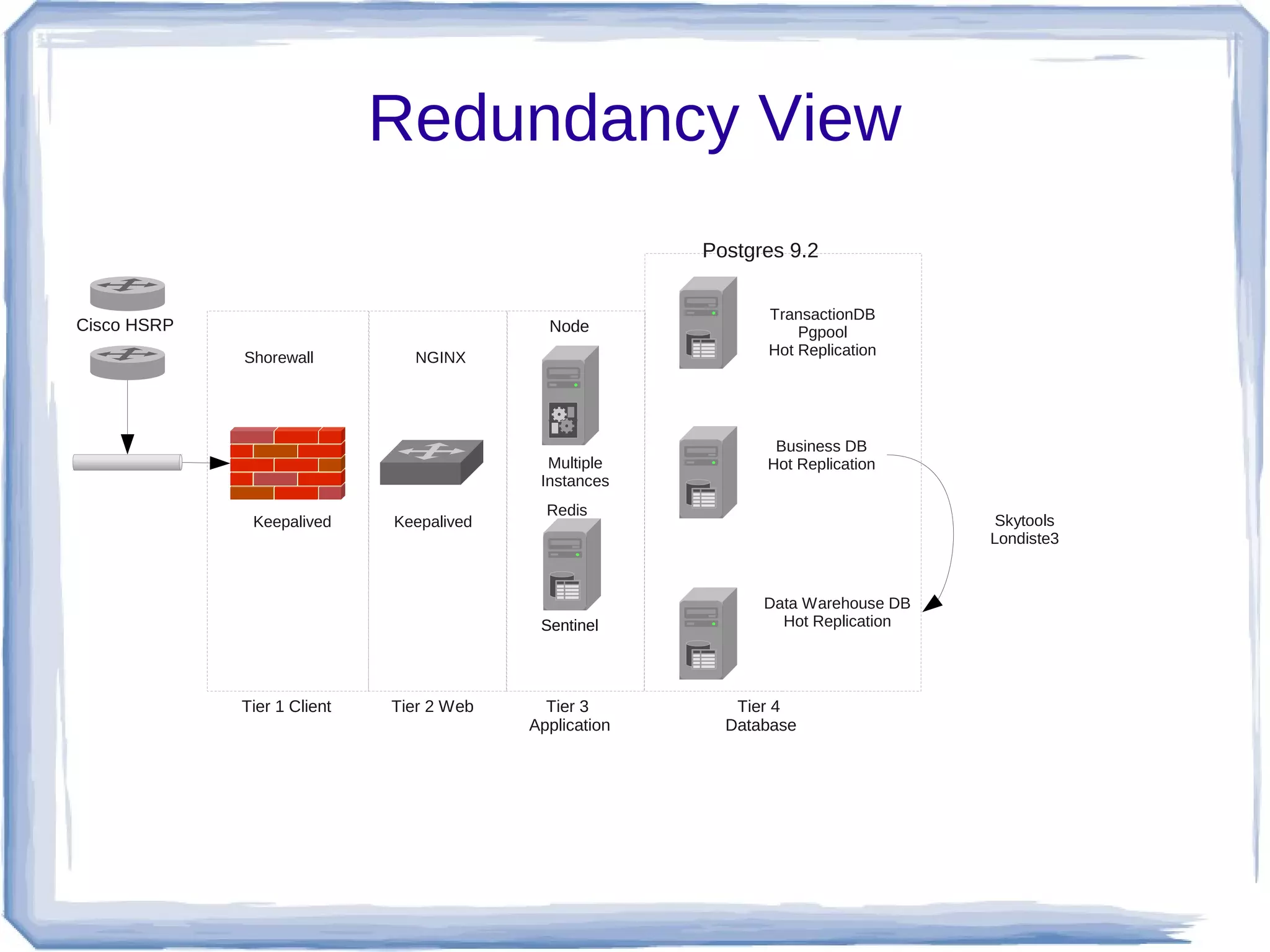














This document discusses using PostgreSQL and Redis together for a high performance ad serving system. Redis is used as a fast in-memory database to store frequently accessed data like ad impressions and clicks. A Redis foreign data wrapper allows PostgreSQL to efficiently retrieve this data from Redis and load it into the recording database. The PostgreSQL databases store longer term data and handle reporting. Materialized views are used to optimize ad filtering queries. Together PostgreSQL and Redis allow the system to serve over 10,000 ads per second while recording analytics data for reporting.



























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













