Downloaded 18 times













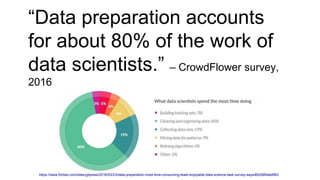



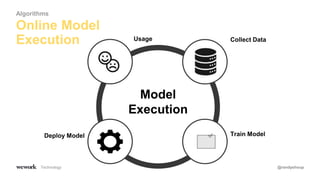
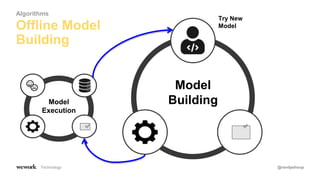

















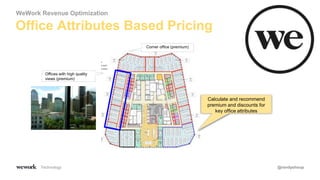
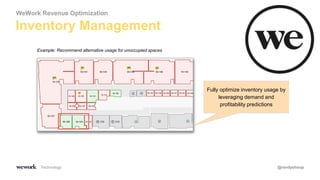
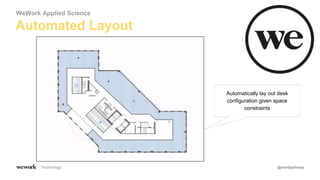





The document discusses an agile approach to machine learning, emphasizing the importance of defining a clear optimization metric aligned with business value. It highlights the significance of quality data and the iterative nature of experiments in developing and refining models, advocating for a data-driven culture in decision-making. The takeaways include starting with a business problem, ensuring data cleanliness, and applying A/B testing rigorously to enhance model accuracy and relevance.












































































