Downloaded 119 times





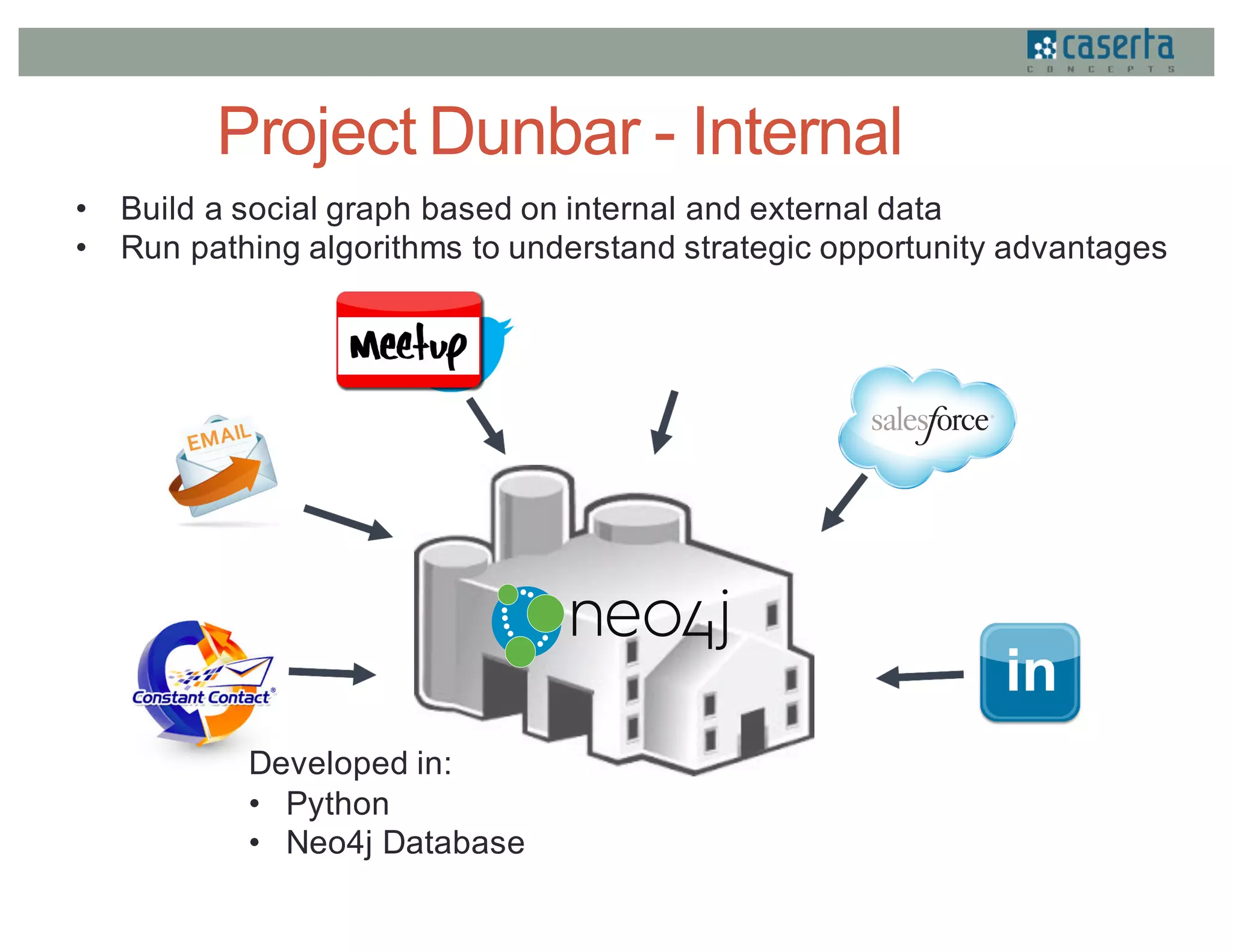



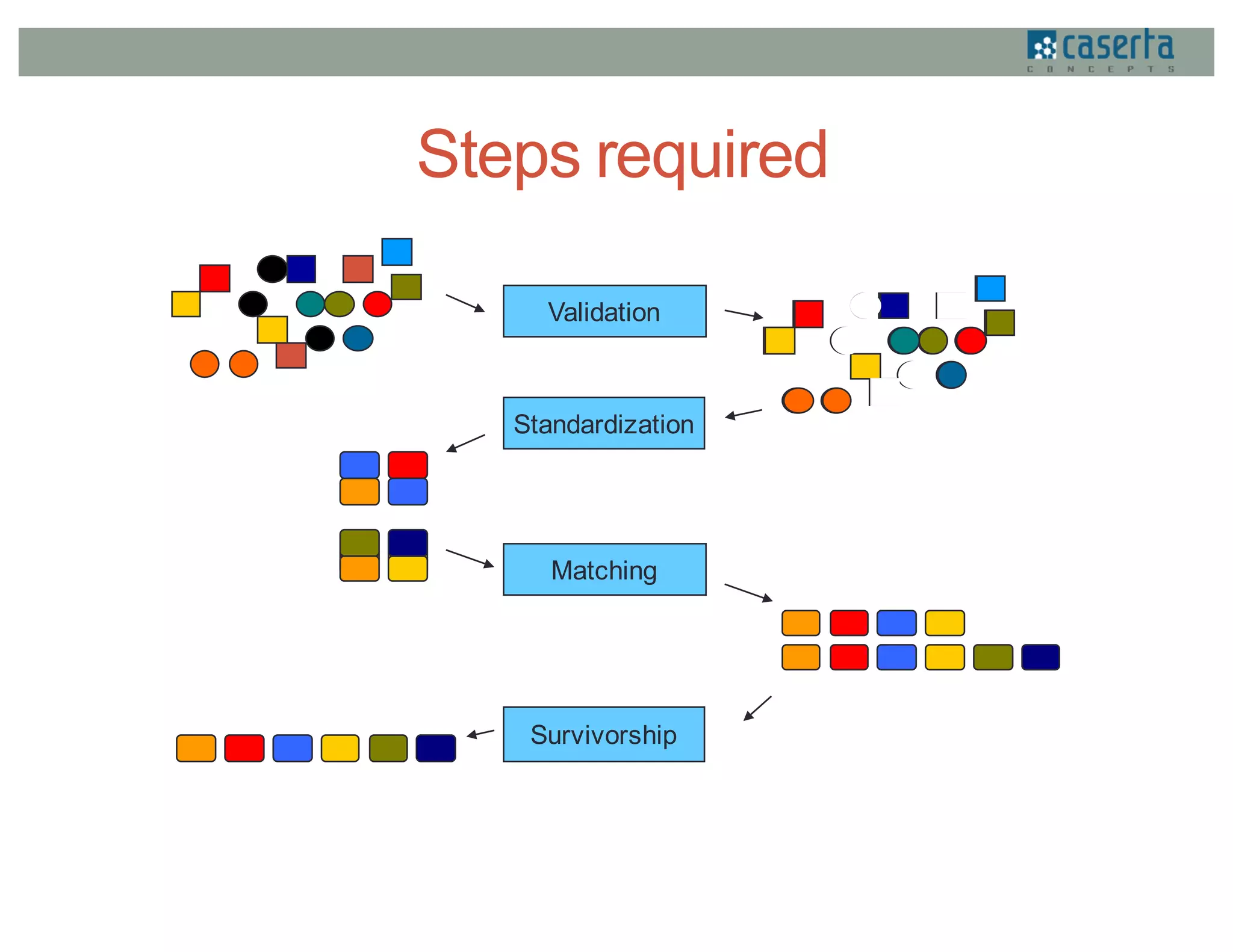


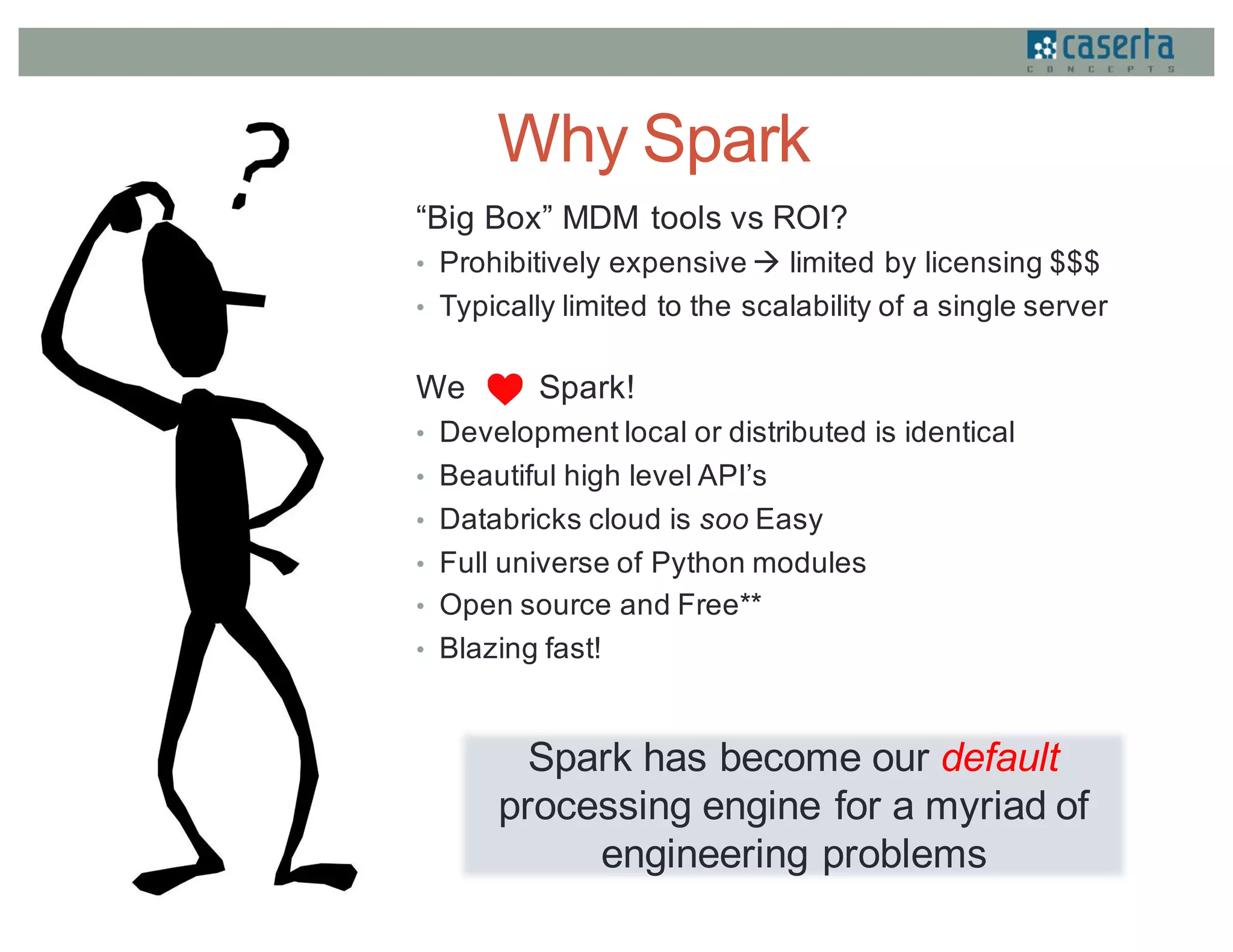

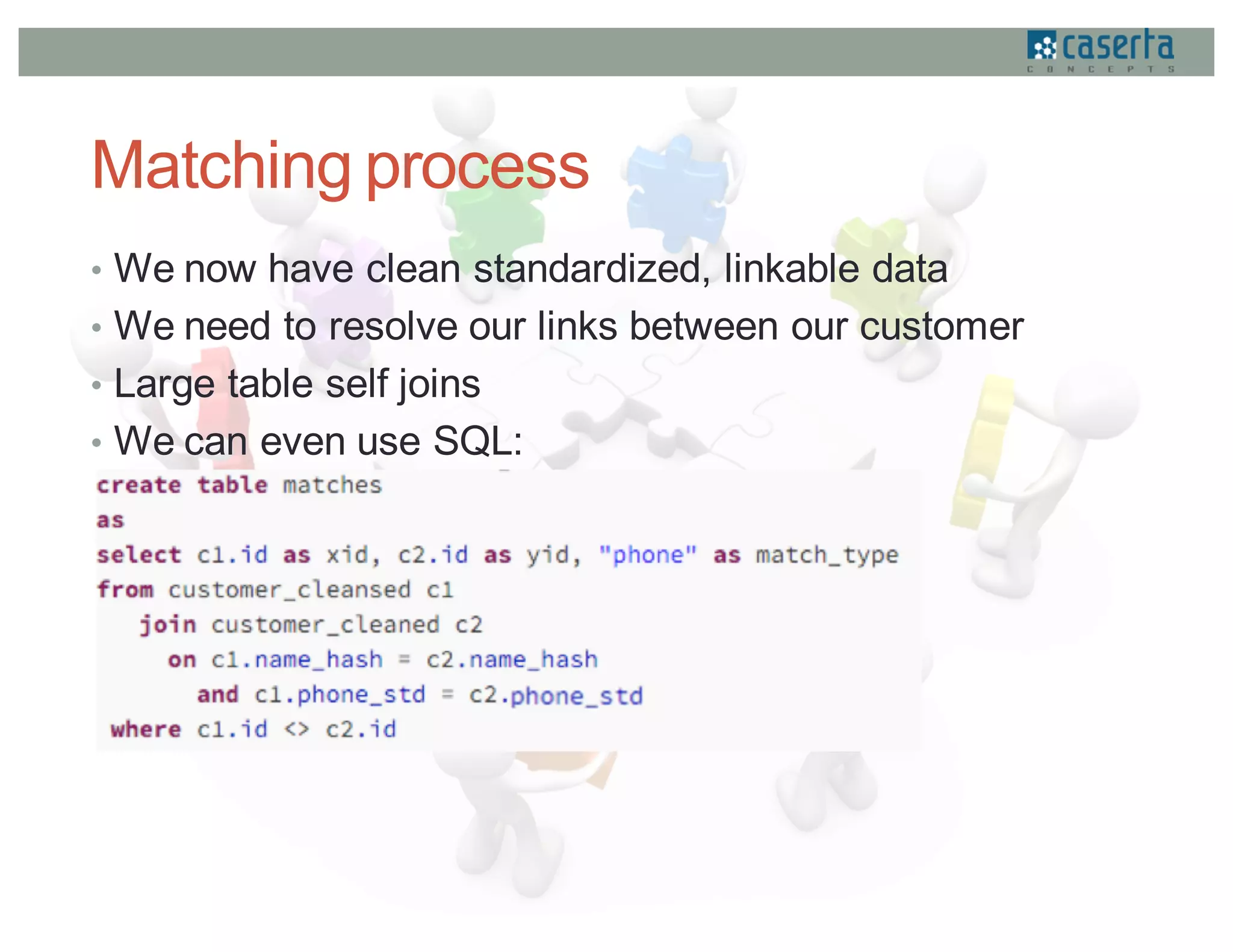

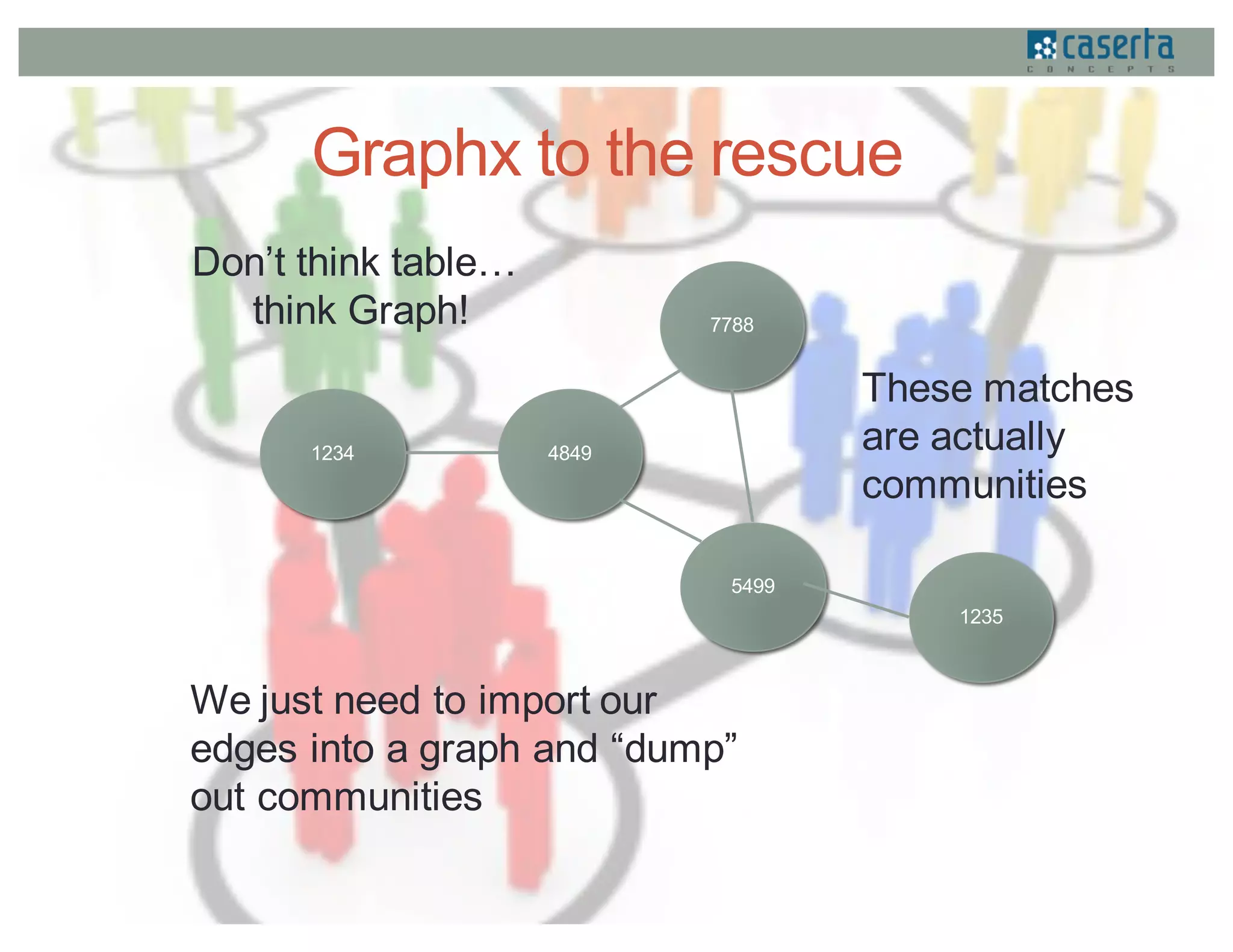
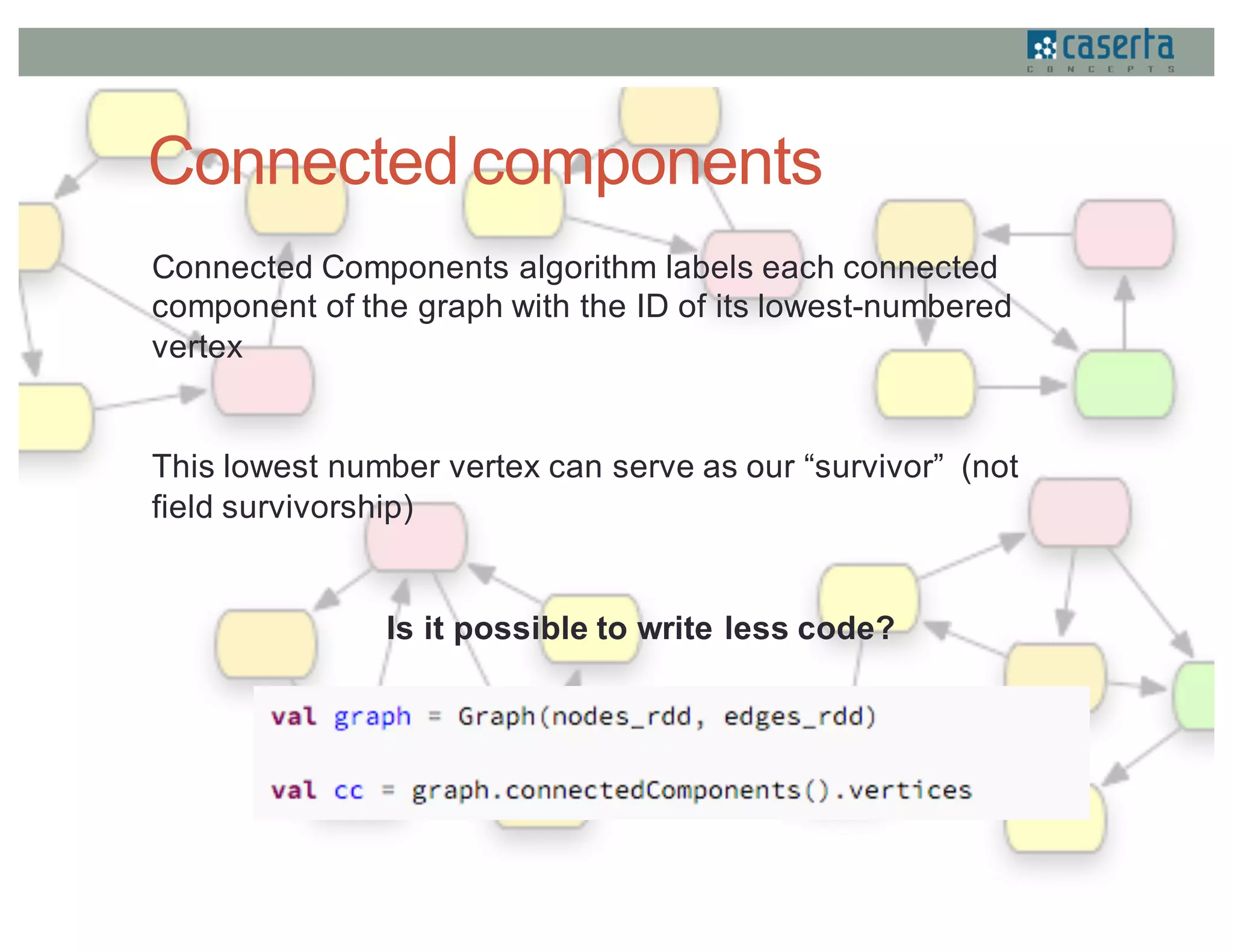


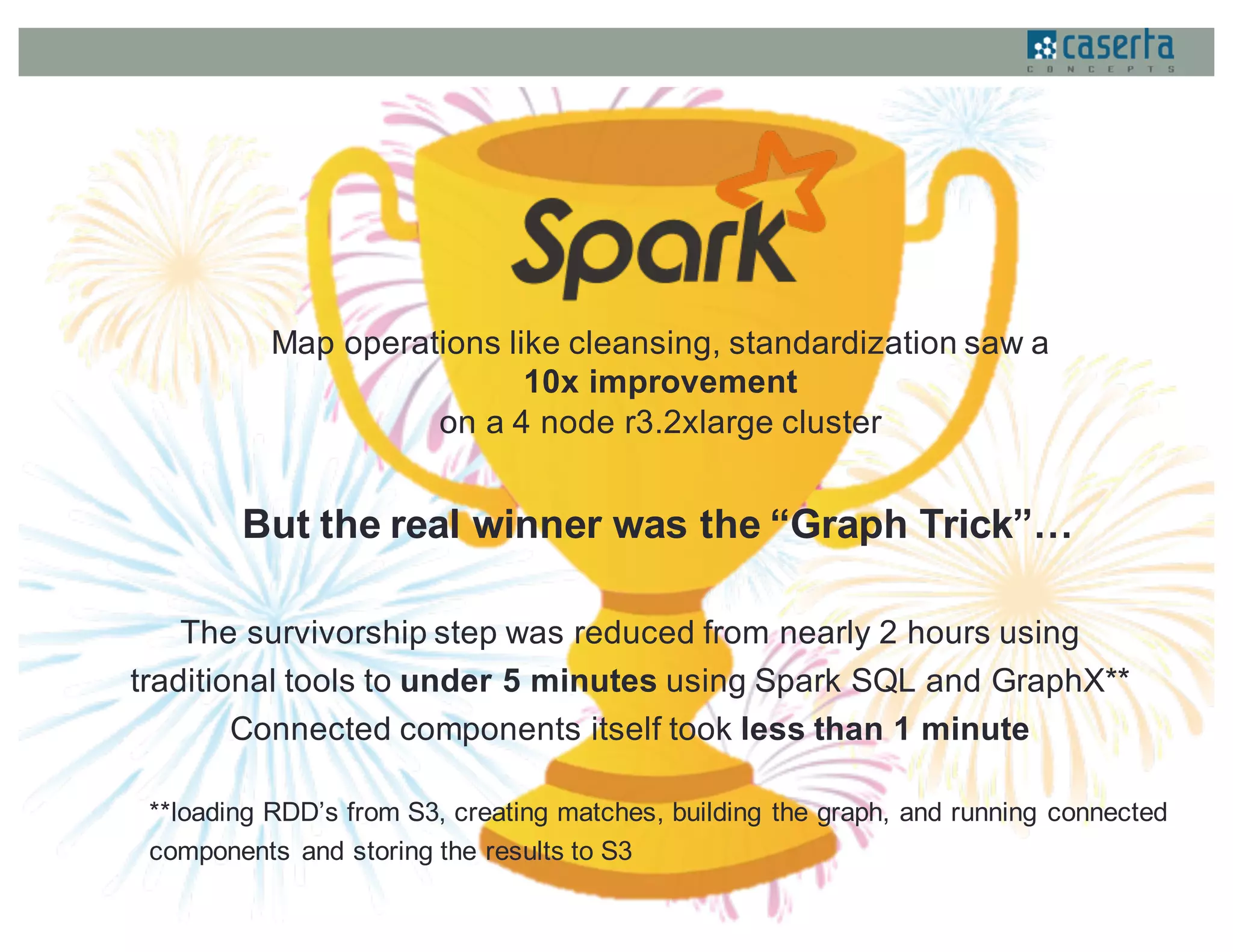


This document discusses how Caserta Concepts used Apache Spark to help a customer master their customer data by cleaning, standardizing, matching, and linking over 6 million customer records and hundreds of millions of data points. Traditional customer data integration approaches were prohibitively expensive and slow for this volume of data. Spark enabled the data to be processed 10x faster by parallelizing data cleansing and transformation. GraphX was also used to model the data as a graph and identify linked customer records, reducing survivorship processing from 2 hours to under 5 minutes.





























































![[Webinar] Drawing insights from social media](https://cdn.slidesharecdn.com/ss_thumbnails/scupgooddatawebinar-130131082550-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













































