Downloaded 24 times



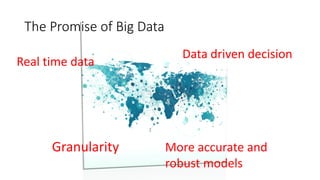
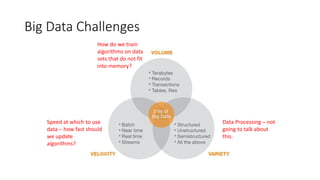

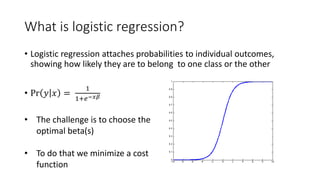




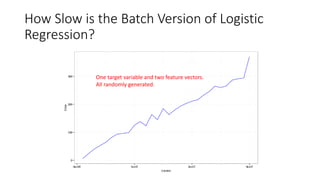
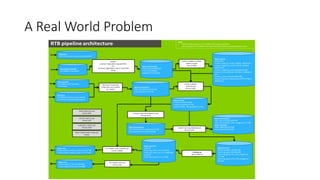




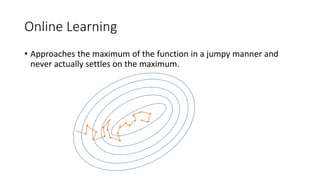
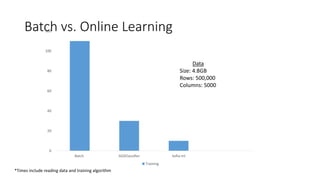




- Logistic regression is a classic machine learning algorithm used for classification tasks like predicting customer churn or click behavior. However, training logistic regression on large datasets ("big data") using the traditional batch approach is very slow. - Online learning is an alternative approach that trains logistic regression on one data point at a time, allowing for faster real-time updates. Popular libraries for online learning include Sofia-ml, Vowpal Wabbit, and scikit-learn which can train models on data in batches. - Expedia uses logistic regression for tasks like predicting hotel bookings and detecting credit card fraud, where billions of predictions are made daily. Online learning allows training these models faster to keep up with this scale































































































