Download as PDF, PPTX


















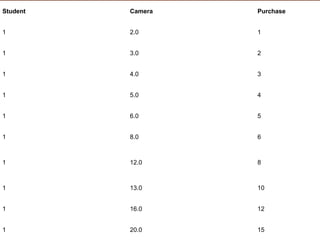
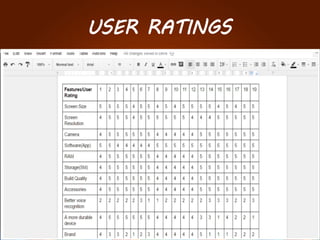
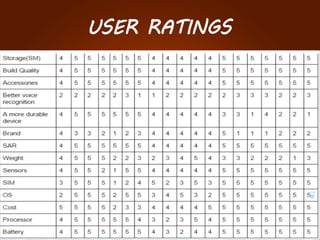
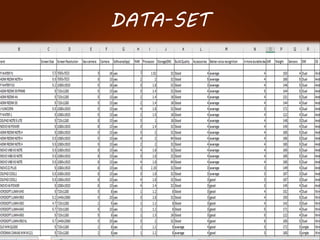


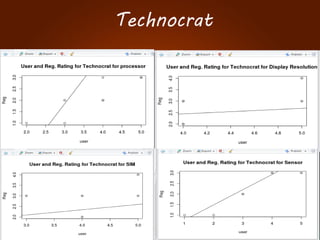
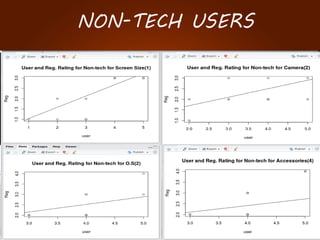
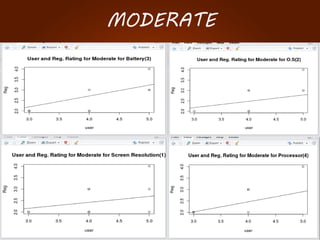
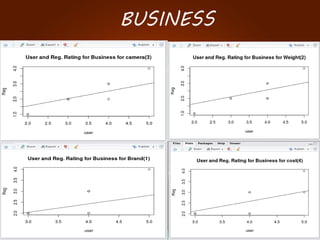
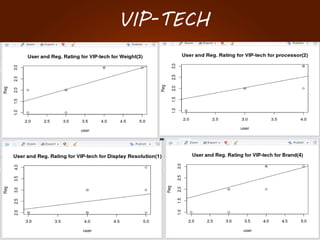


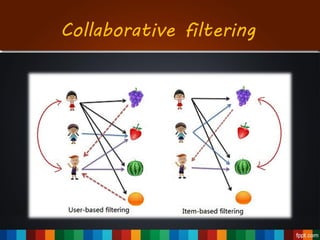

















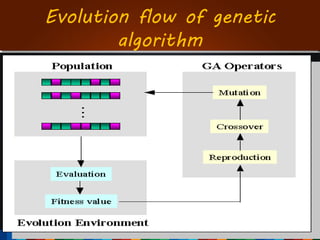
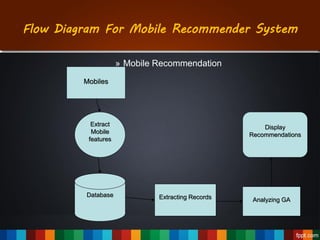







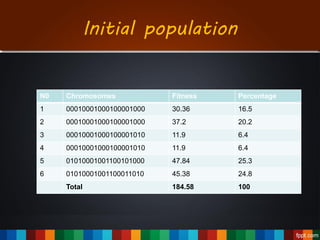
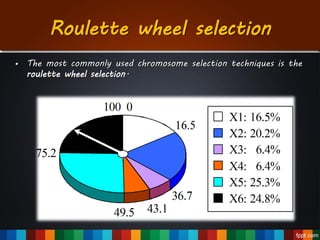

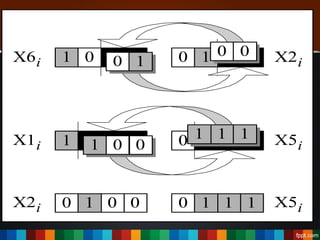

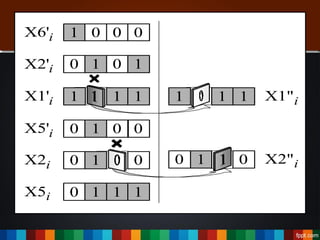
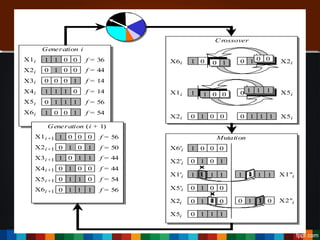

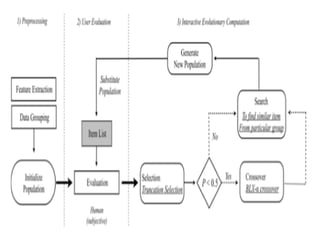
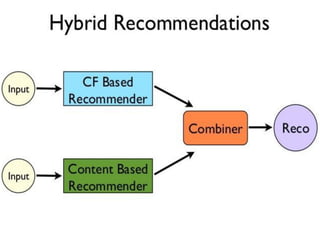
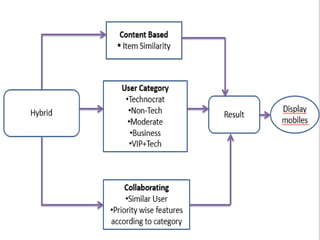

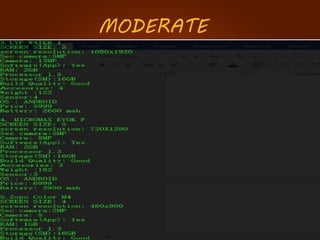
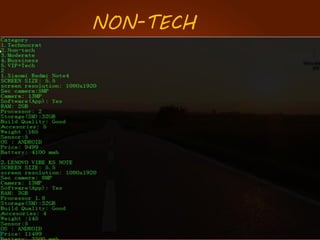
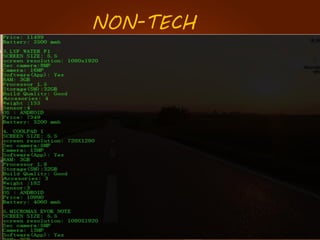


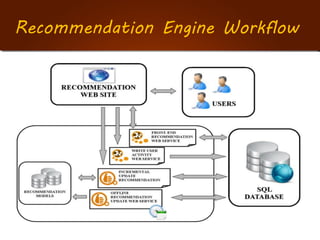
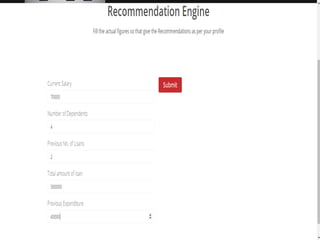




The document discusses the development of a recommendation engine using genetic algorithms, highlighting the challenges in traditional recommendation systems and proposing improvements in accuracy for consumers and marketers. It outlines various algorithms, features, and methodologies, including collaborative and content-based filtering, as well as genetic algorithm components like selection, crossover, and mutation. Future enhancements will focus on optimizing the algorithm and combining techniques to provide better user recommendations and increase revenue for companies.










![[Pk] pertemuan 12 Decision Tree](https://cdn.slidesharecdn.com/ss_thumbnails/pkpertemuan10-decisiontree-190514092121-thumbnail.jpg?width=640&height=640&fit=bounds)



































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










