Downloaded 12 times







![Origin: Functional Programming
● Map - Returns a list constructed by applying a function (the first argument) to all
items in a list passed as the second argument
○ map f [a, b, c] = [f(a), f(b), f(c)]
○ map sq [1, 2, 3] = [sq(1), sq(2), sq(3)] = [1,4,9]
● Reduce - Returns a list constructed by applying a function (the first argument) on
the list passed as the second argument. Can be identity (do nothing).
○ reduce f [a, b, c] = f(a, b, c)
○ reduce sum [1, 4, 9] = sum(1, sum(4,sum(9,sum(NULL)))) = 14](https://image.slidesharecdn.com/introductiontomapreduce-170120062557/85/Introduction-to-map-reduce-8-320.jpg)
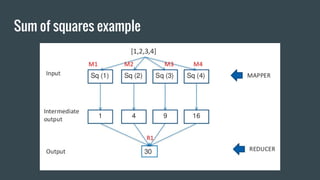
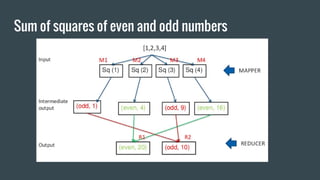

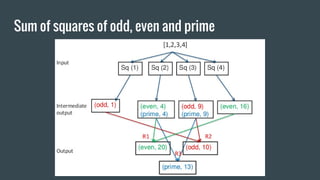
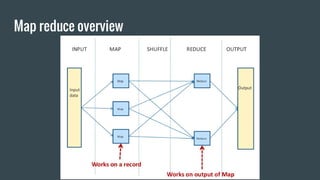
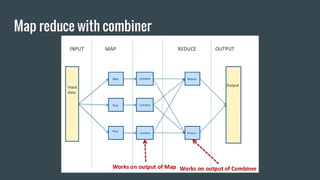
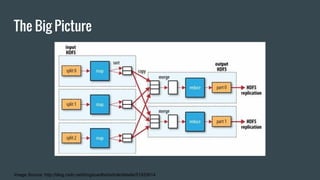
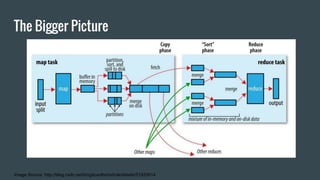











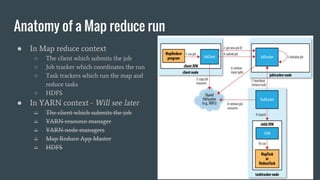
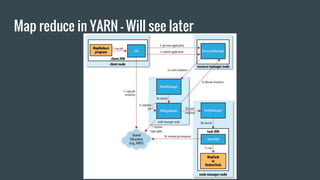


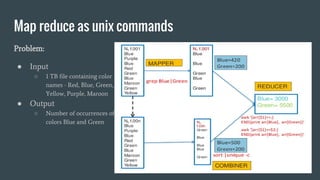

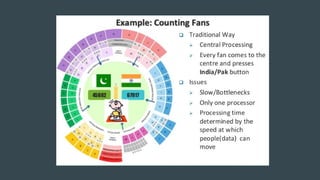
MapReduce provides a programming model for processing large datasets in a distributed, parallel manner. It involves two main steps - the map step where the input data is converted into intermediate key-value pairs, and the reduce step where the intermediate outputs are aggregated based on keys to produce the final results. Hadoop is an open-source software framework that allows distributed processing of large datasets across clusters of computers using MapReduce.




![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)










