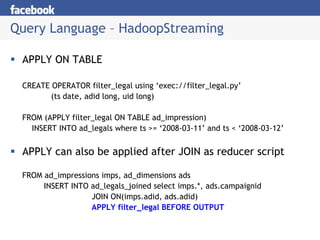
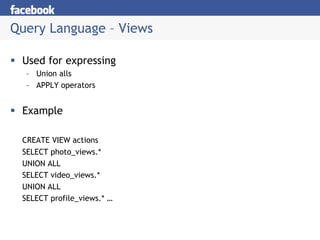
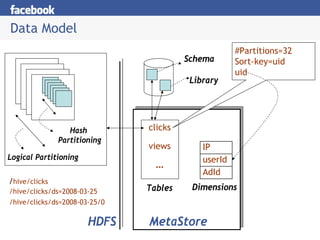
Hive provides a mechanism for easy data warehousing of structured data stored in Hadoop. It uses a SQL-like query language that allows business analysts to query this data more easily. It stores metadata about tables and partitions in a metastore. The query language supports operations like projections, joins, grouping, and applying streaming operators to the results. Hive is used at Facebook for data summarization, ad hoc analysis, and assembling training data.

![Dealing with Structured Data
Type system
– Primitive types
– Recursively build up using Composition/Maps/Lists
Generic (De)Serialization Interface (SerDe)
– To recursively list schema
– To recursively access fields within a row object
Serialization families implement interface
– Thrift (Binary and Delimited Text), RecordIO, JSON/PADS(?)
XPath like field expressions
– profiles.network[@is_primary=1].id
Inbuilt DDL
– Define schema over delimited text files
– Leverages Thrift DDL](https://image.slidesharecdn.com/facebook-hadoop-summit-111031122346-phpapp02/85/Facebook-hadoop-summit-4-320.jpg)

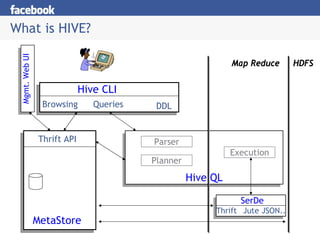
![Hive CLI
Implemented in Python
– uses MetaStore Thrift API
DDL:
– create table/drop table/rename table
– alter table add column etc.
Browsing:
– show tables
– describe table
– cat table
Loading Data
– load data inpath <path1, …> into table <tablename/partition-spec>]
[bucketed <N> ways by <dimension>]
Queries
– Issue queries in Hive QL.](https://image.slidesharecdn.com/facebook-hadoop-summit-111031122346-phpapp02/85/Facebook-hadoop-summit-7-320.jpg)