Downloaded 104 times













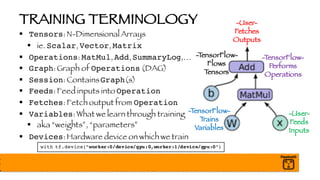
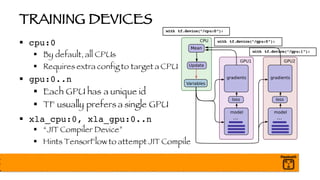
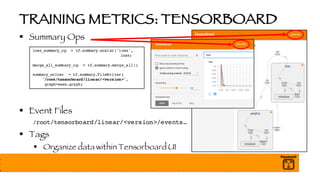




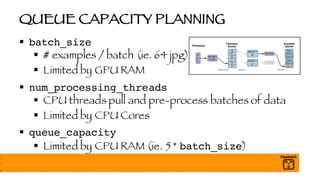


![BATCH NORMALIZATION
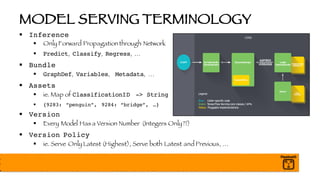
§ Each Mini-Batch May Have Wildly Different Distributions
§ Normalize per batch (and layer)
§ Speeds up Training!!
§ Weights are Learned Quicker
§ Final Model is More Accurate
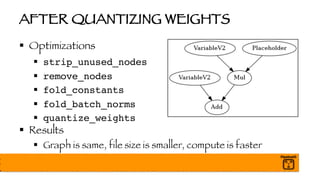
§ Final mean and variance will be folded into Graph later
-- Always Use Batch Normalization! --
z = tf.matmul(a_prev, W)
a = tf.nn.relu(z)
a_mean, a_var = tf.nn.moments(a, [0])
scale = tf.Variable(tf.ones([depth/channels]))
beta = tf.Variable(tf.zeros ([depth/channels]))
bn = tf.nn.batch_normalizaton(a, a_mean, a_var,
beta, scale, 0.001)](https://image.slidesharecdn.com/tensorflowchicagomeetup06222017-170623161829/85/High-Performance-Distributed-TensorFlow-with-GPUs-TensorFlow-Chicago-Meetup-June-22-2017-29-320.jpg)

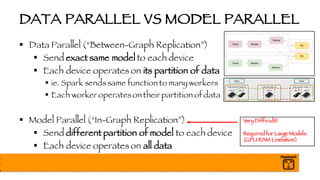

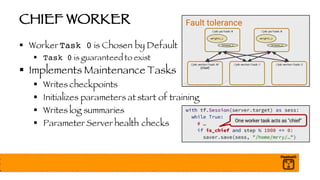

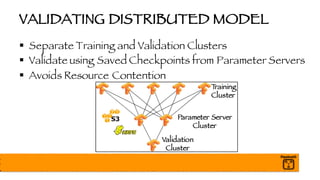






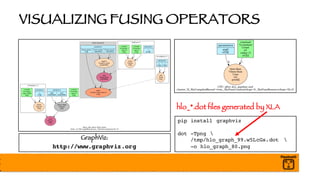





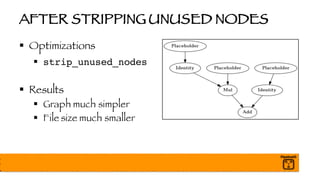
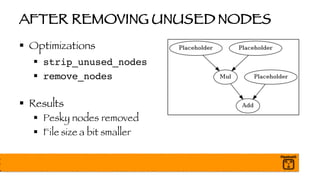
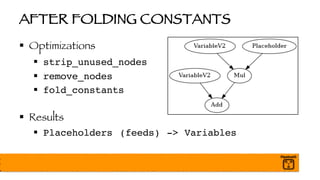
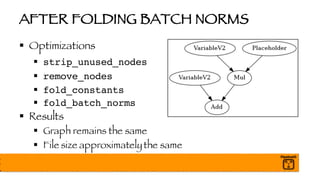


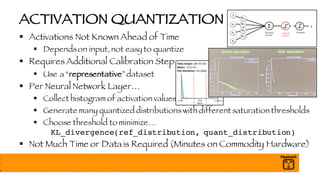
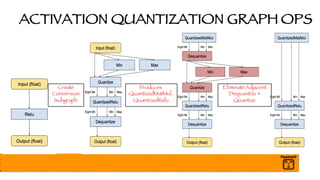
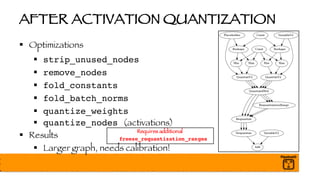











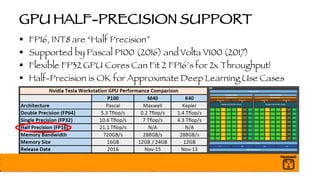
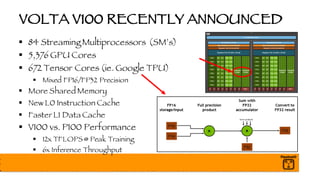
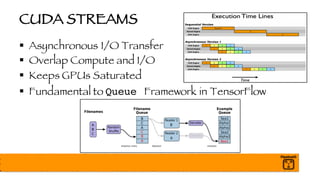
The document outlines a presentation on optimizing and deploying TensorFlow models in production using GPUs, aimed at software engineers and data scientists. It covers training and deployment best practices, introduces various TensorFlow optimizations, and demonstrates the effective use of GPUs to enhance performance. Additionally, it emphasizes advanced topics like multi-GPU training, XLA (Accelerated Linear Algebra), and TensorFlow Serving for efficient inference.






































![[系列活動] 資料探勘速遊](https://cdn.slidesharecdn.com/ss_thumbnails/0114ycchendmquicktour-170110050658-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC 2016] 系列活動:李泳泉 / 星火燎原 - Spark 機器學習初探](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmllib-161026052038-thumbnail.jpg?width=640&height=640&fit=bounds)


![[系列活動] 文字探勘者的入門心法](https://cdn.slidesharecdn.com/ss_thumbnails/textmininghandout-170320140215-170327095320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 智慧城市中的時空大數據應用](https://cdn.slidesharecdn.com/ss_thumbnails/dscstbigdata1060211-170211004152-thumbnail.jpg?width=640&height=640&fit=bounds)






















































