Download as PDF, PPTX











![POST-TRAINING OPTIMIZATIONS
§ Prepare Model for Serving
§ Simplify Network
§ Reduce Model Size
§ Quantize for Fast Matrix Math
§ Some Tools
§ Graph Transform Tool (GTT)
§ tfcompile
After Training
After
Optimizing!
pipeline optimize --optimization-list=[quantize_weights, tfcompile]
--model-type=tensorflow
--model-name=mnist
--model-tag=A
--model-path=./tensorflow/mnist/model
--output-path=./tensorflow/mnist/optimized_model
Linear
Regression](https://image.slidesharecdn.com/pipelineaioverview-171212020249/75/PipelineAI-AWS-SageMaker-Distributed-TensorFlow-AI-Model-Training-and-Serving-December-2017-NIPS-Conference-LA-Big-Data-and-Python-Meetups-14-2048.jpg)






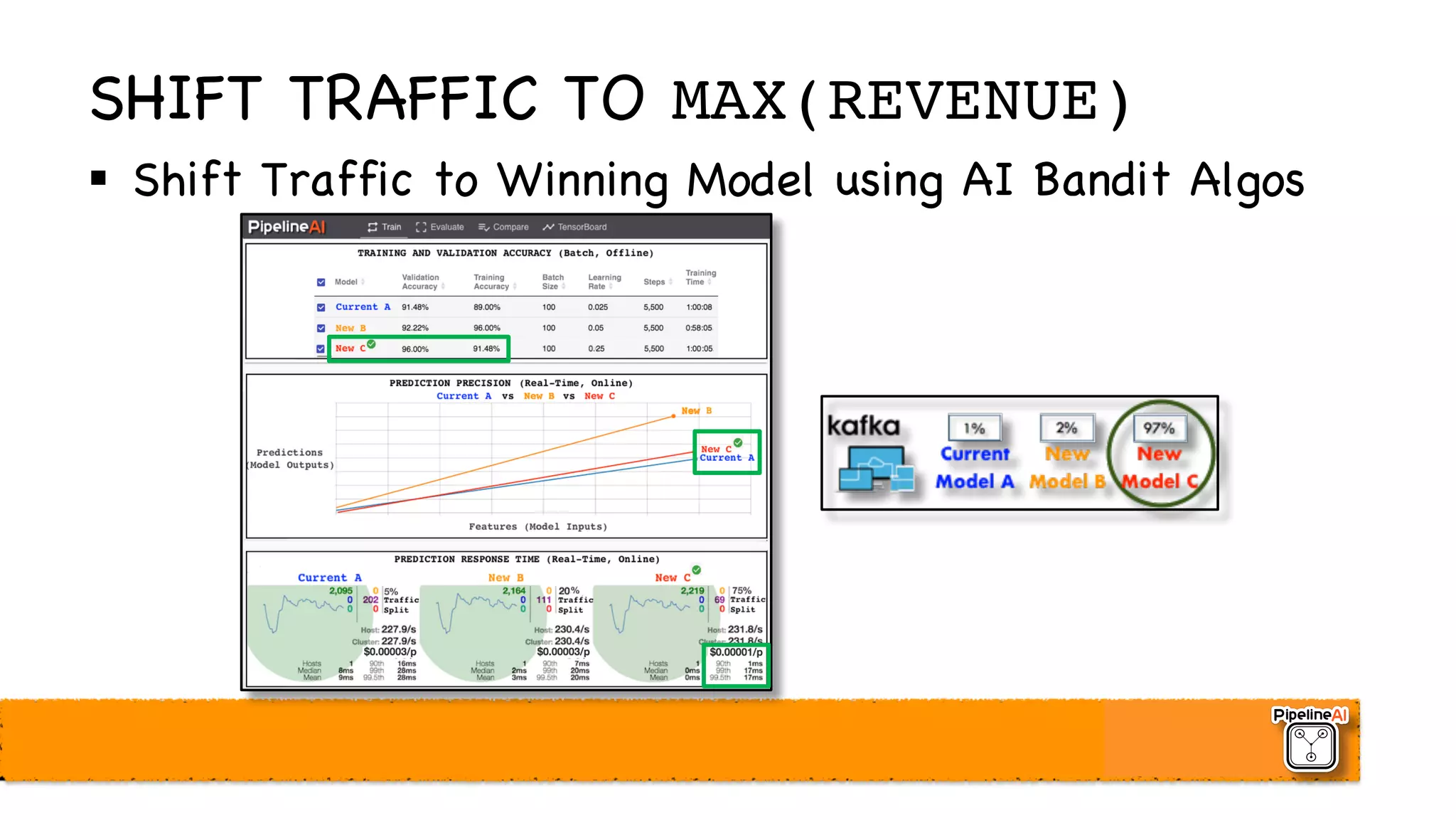
![LIVE, ADAPTIVE TRAFFIC ROUTING
§ A/B Tests
§ Inflexible and Boring
§ Multi-Armed Bandits
§ Adaptive and Exciting!
pipeline traffic-router-split --model-type=tensorflow
--model-name=mnist
--model-tag-list=[A,B,C]
--model-weight-list=[1,2,97]
Adjust
Traffic Routing
Dynamically](https://image.slidesharecdn.com/pipelineaioverview-171212020249/75/PipelineAI-AWS-SageMaker-Distributed-TensorFlow-AI-Model-Training-and-Serving-December-2017-NIPS-Conference-LA-Big-Data-and-Python-Meetups-23-2048.jpg)






Pipeline.AI is a platform for deploying and optimizing machine learning models at scale. It allows users to package models with their runtime dependencies, perform load testing and optimizations, deploy models to production safely using techniques like canary deployments, and monitor models both offline and online. The platform aims to enable live, continuous model training directly in production environments.
















































































