Downloaded 65 times

















































![FUSED BATCH NORMALIZATION
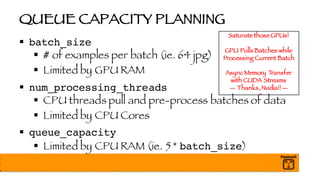
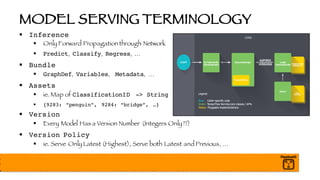
§ What is Batch Normalization?
§ Each batch of data may have wildly different distributions
§ Normalize per batch (and layer)
§ Speeds up training dramatically
§ Weights are learned quicker
§ Final model is more accurate
Always Use Batch Normalization!
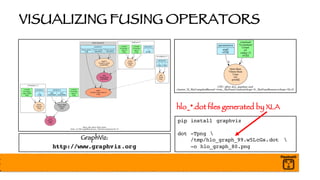
§ GTT Fuses Final Mean and Variance MatMul into Graph
z = tf.matmul(a_prev, W)
a = tf.nn.relu(z)
a_mean, a_var = tf.nn.moments(a, [0])
scale = tf.Variable(tf.ones([depth/channels]))
beta = tf.Variable(tf.zeros ([depth/channels]))
bn = tf.nn.batch_normalizaton(a, a_mean, a_var,
beta, scale, 0.001)](https://image.slidesharecdn.com/hotelsdotcommay2017-170524093741/85/Optimize-Deploy-Distributed-Tensorflow-Spark-and-Scikit-Learn-Models-on-GPUs-Advanced-Spark-and-TensorFlow-Meetup-May-23-2017-Hotels-com-London-72-320.jpg)

















The document presents a comprehensive overview of optimizing and deploying TensorFlow models in high-performance environments with GPUs, specifically from a presentation given by Chris Fregly at the GPU Tech Conference in 2017. It covers topics such as training optimizations, deployment techniques, the usage of various tools including TensorFlow Serving, XLA (Accelerated Linear Algebra), and strategies for both single-node and distributed multi-GPU training. Key takeaways include the importance of using queues to manage data movement, optimizing models via JIT compilation and AOT compiling, and the necessity of effective monitoring during the training process.


















































































