Download as PDF, PPTX





















The document presents updates from AWS re:Invent 2022, focusing on enhancements to the AWS SDK for Pandas, including serverless capabilities and large language model support. It highlights the scalability of data processing and AI/ML workloads using AWS services like Amazon S3, Glue, SageMaker, and the integration of Ray. Additionally, it discusses tutorials and best practices for utilizing the SDK to manage big data efficiently in cloud environments.
Introduction by Chris Fregly on scaling Pandas using AWS services.
The agenda includes updates from re:Invent 2022, Amazon Code Whisperer, AWS services, and AWS SDK for Pandas.
Focus on SageMaker usability and support for large models like Stable Diffusion; introduces Serverless Ray.
The agenda includes updates from re:Invent 2022, Amazon Code Whisperer, AWS services, and AWS SDK for Pandas.
Introduction to AWS SDK for Pandas, Modin, Pandas, Spark, and Ray.
The presentation includes several DEMOs showcasing features of AWS SDK and related services.
The agenda includes updates from re:Invent 2022, Amazon Code Whisperer, AWS services, and AWS SDK for Pandas.
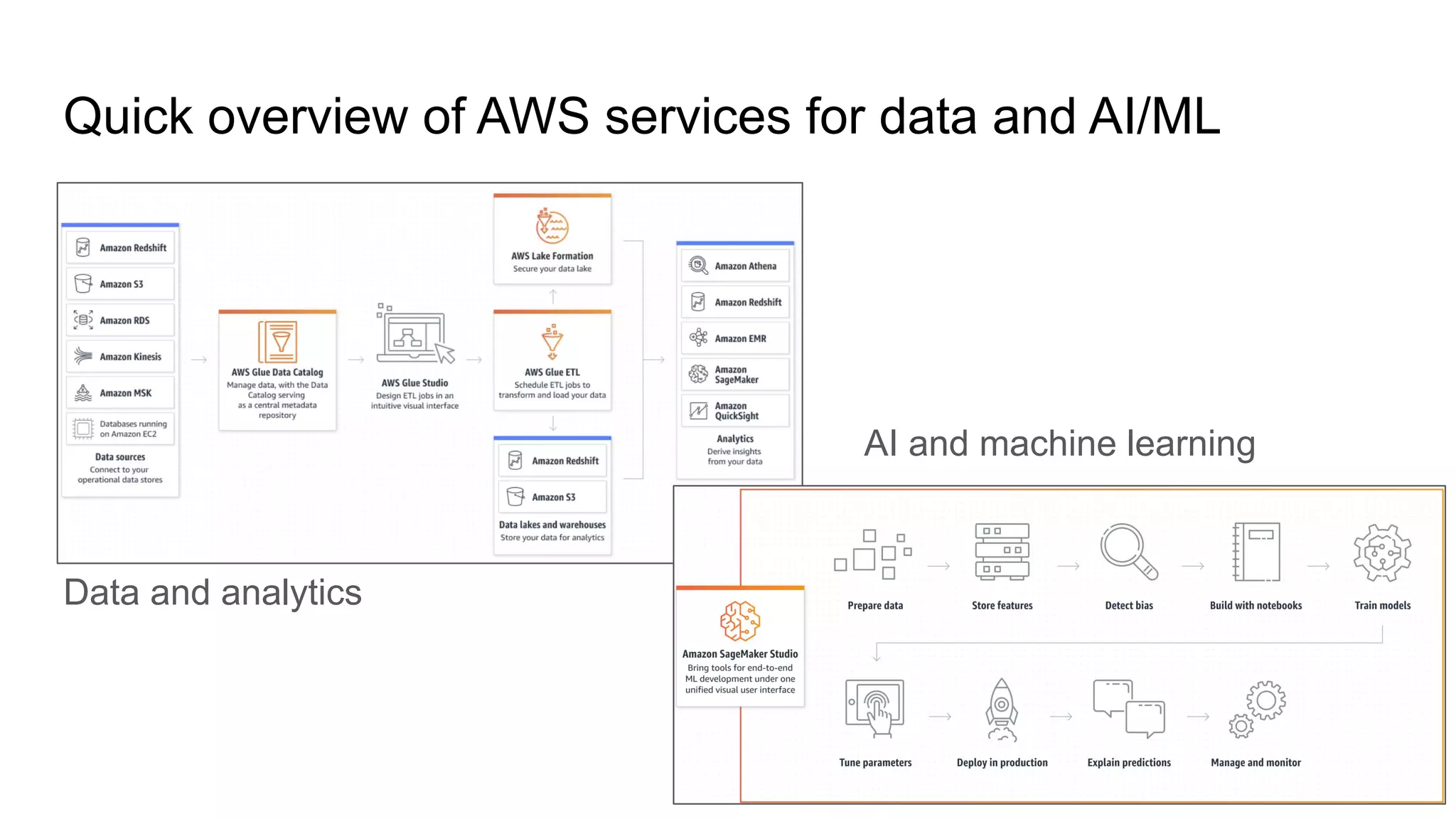
Overview of AWS services relevant to data, AI, and machine learning.
The agenda includes updates from re:Invent 2022, Amazon Code Whisperer, AWS services, and AWS SDK for Pandas.
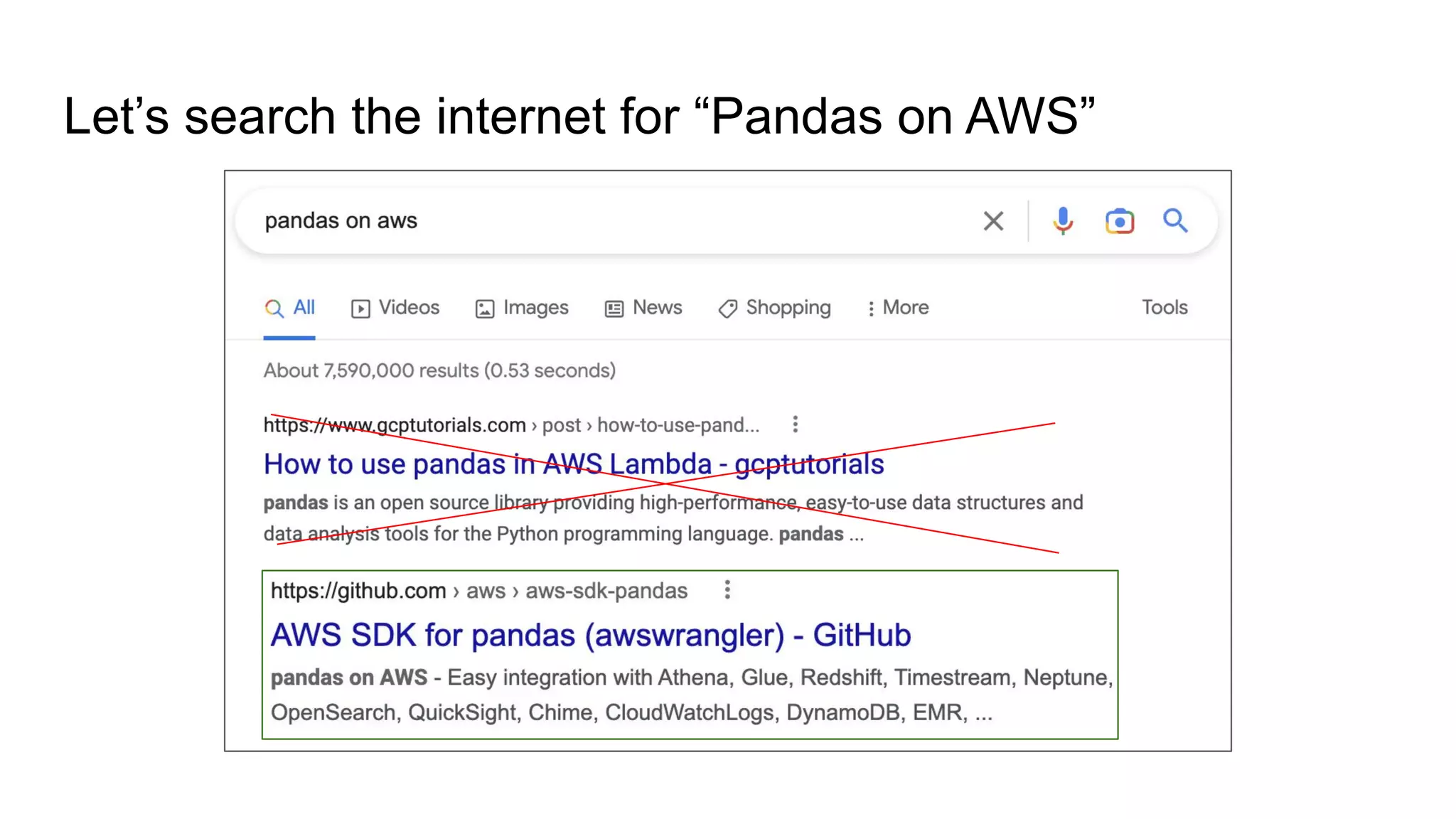
A search prompt highlighting the resources of Pandas on AWS.
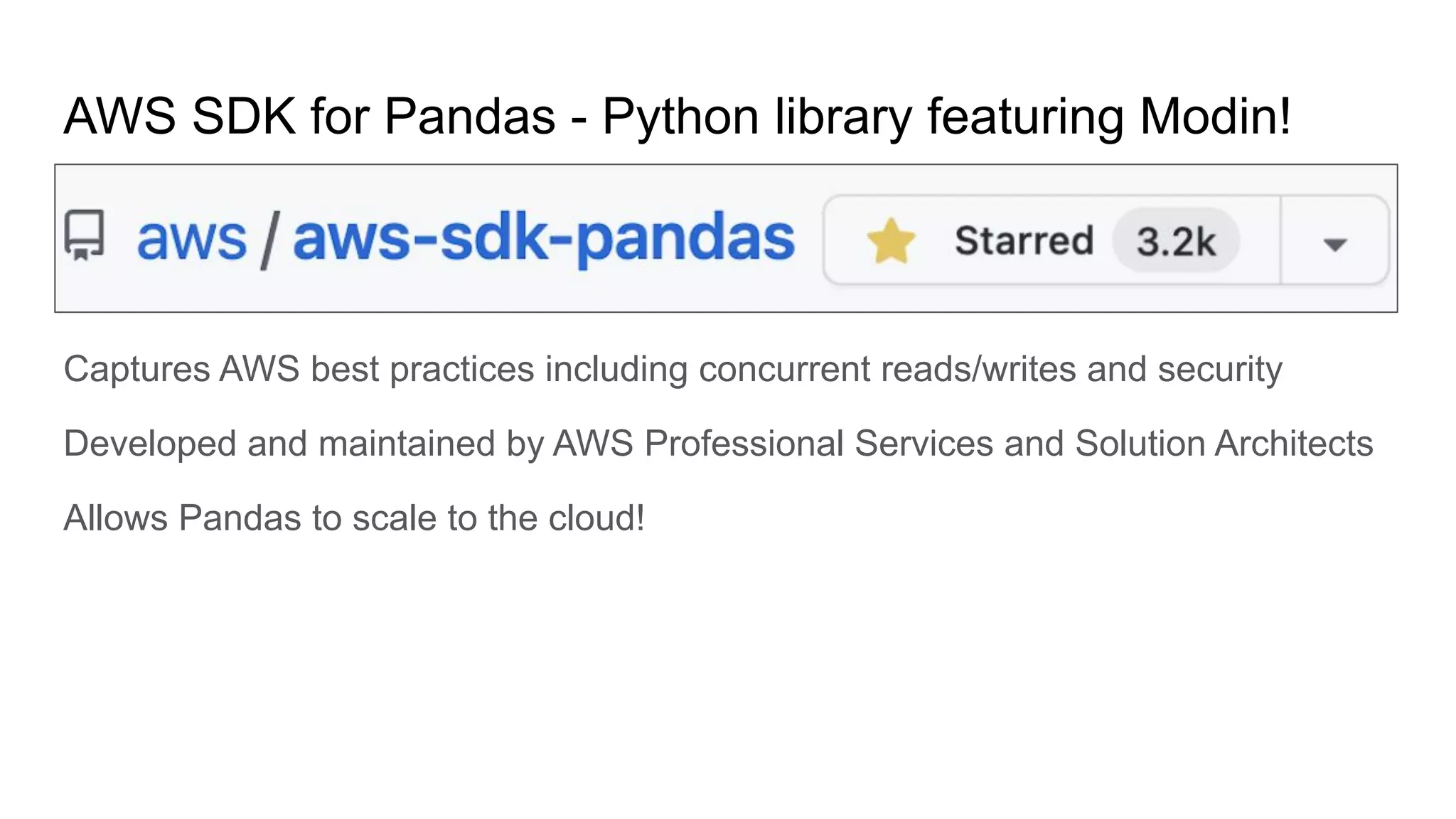
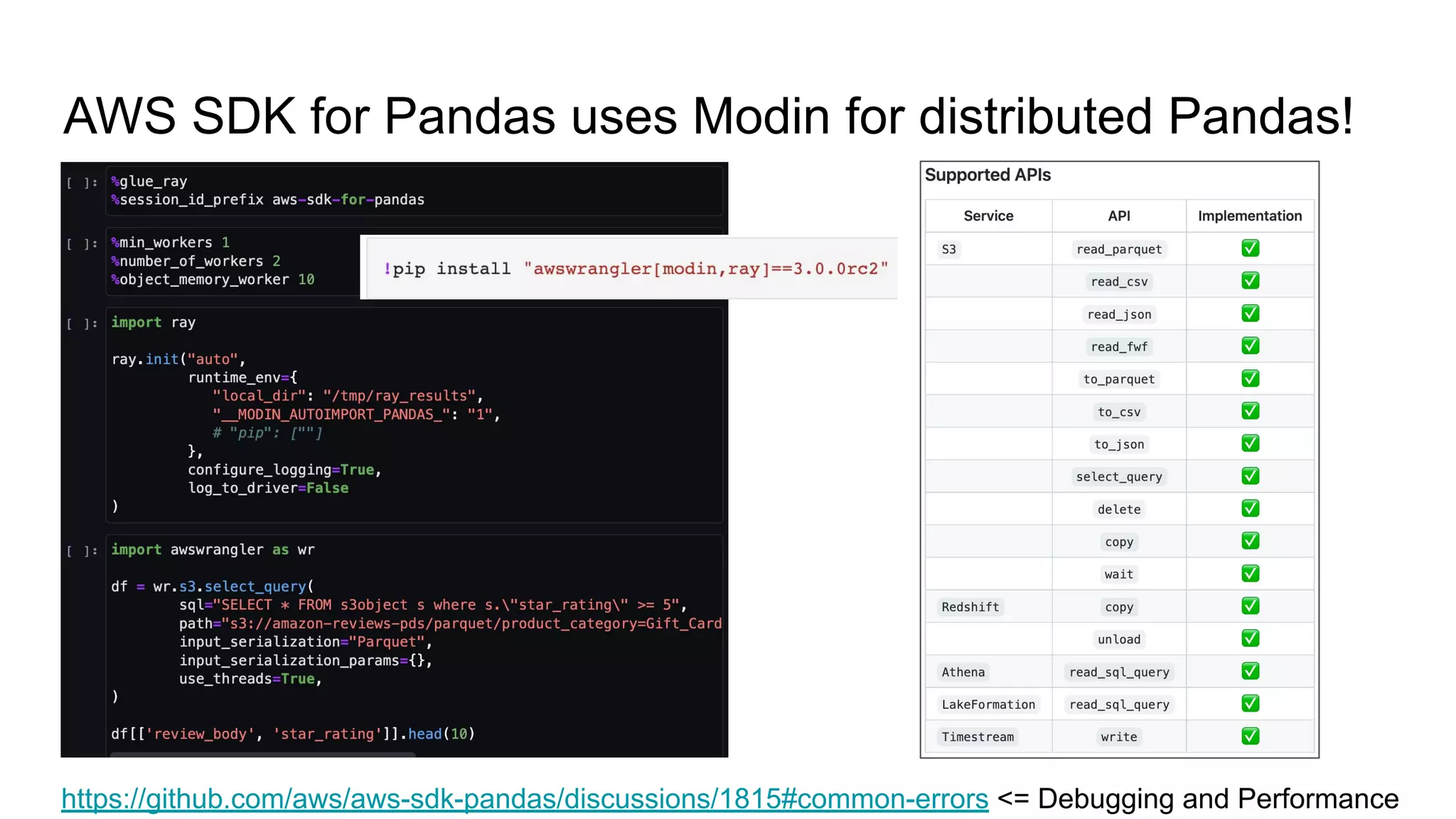
Python library with AWS best practices for scaling Pandas in the cloud.
Scalability necessity due to large data volumes and RAM limitations; benefits of serverless clusters.
List of various AWS services supporting AWS SDK for Pandas, including S3, Glue, and Redshift.
Various environments to run SDK for Pandas including local laptops, AWS Glue, and SageMaker.
A list of 33 tutorial topics available to help users learn the AWS SDK for Pandas.
The presentation includes several DEMOs showcasing features of AWS SDK and related services.
The agenda includes updates from re:Invent 2022, Amazon Code Whisperer, AWS services, and AWS SDK for Pandas.
Ray is used by Amazon.com for data-intensive tasks, performing better than Apache Spark for some cases.
Ray enables scalable data transformations and AI/ML workloads through serverless clusters.
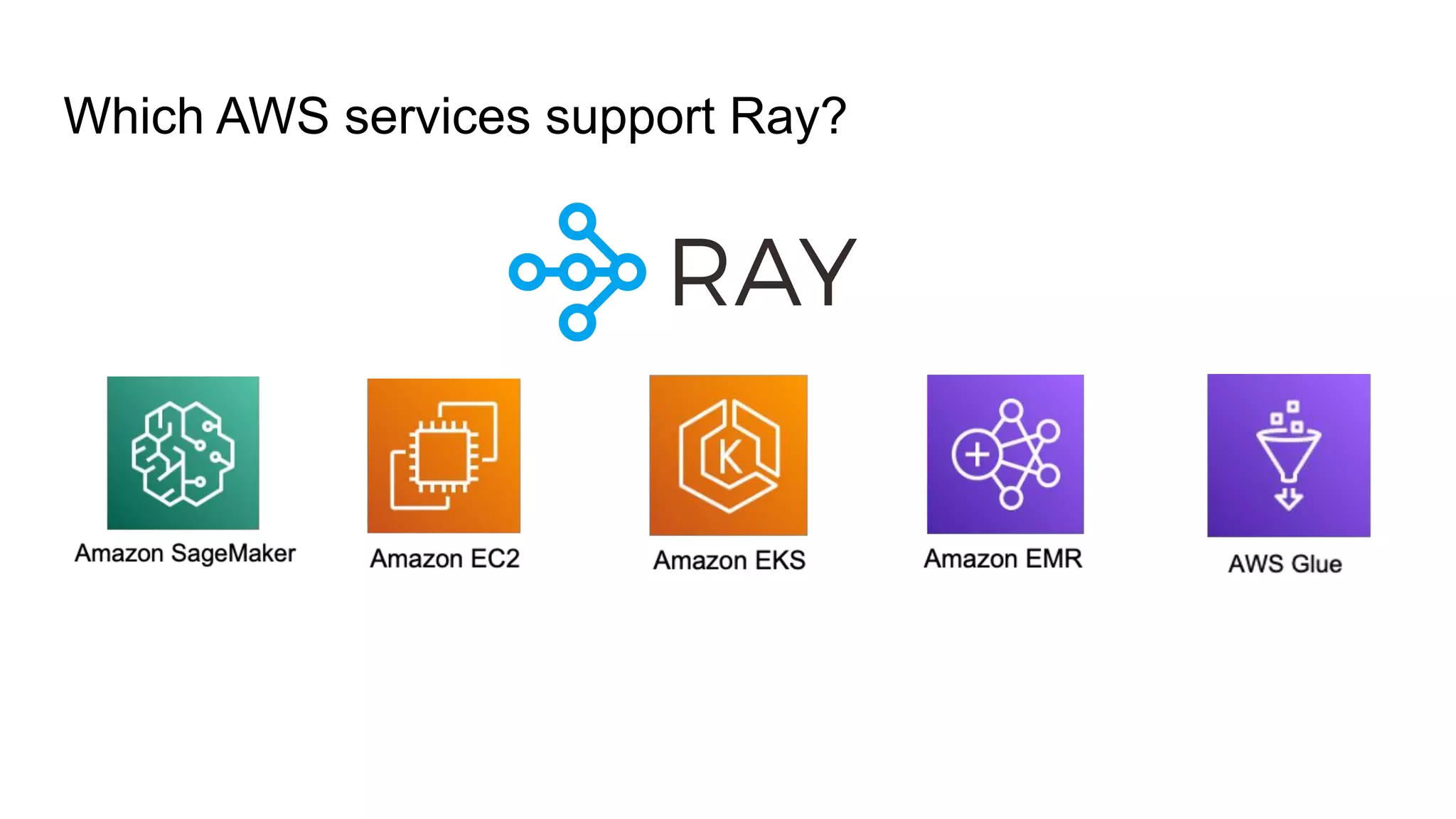
Discussion on the AWS services that support Ray.
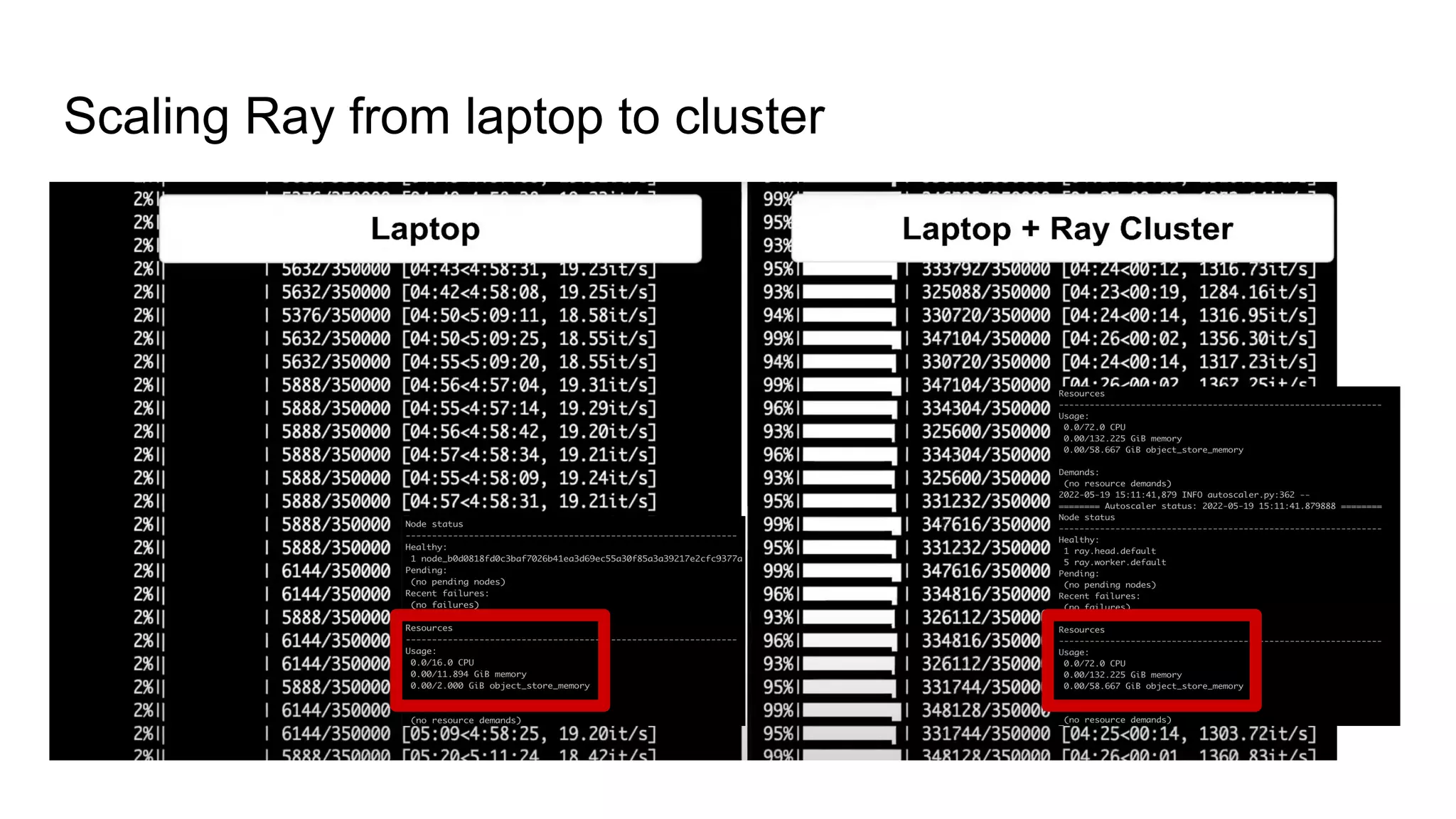
Insights on scaling Ray operations from personal devices to cluster environments.
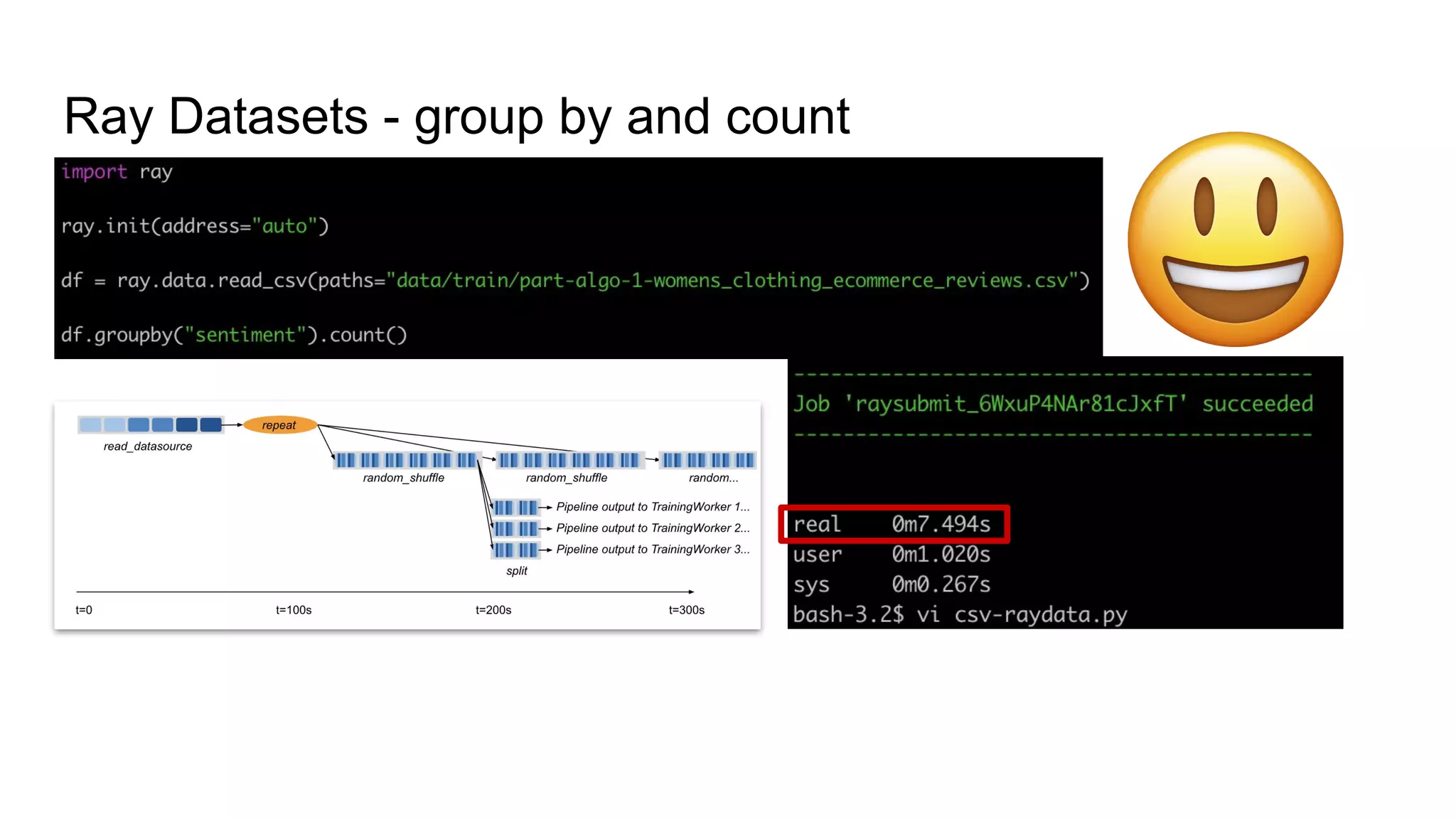
Example usage of Ray Datasets for group by and count operations.
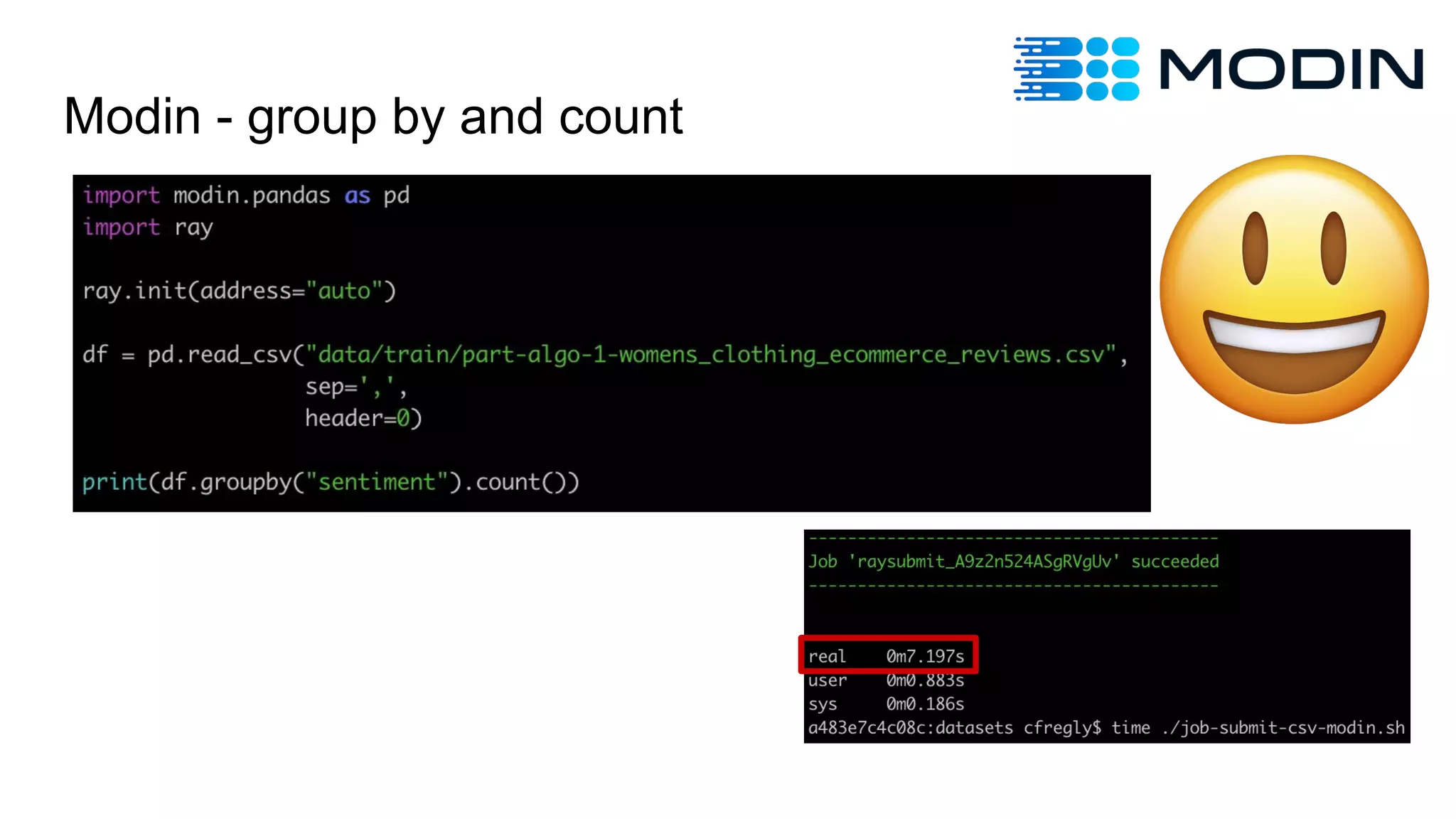
Demonstration of group by and count using Modin.
Illustration of group by and count operation in Apache Spark.
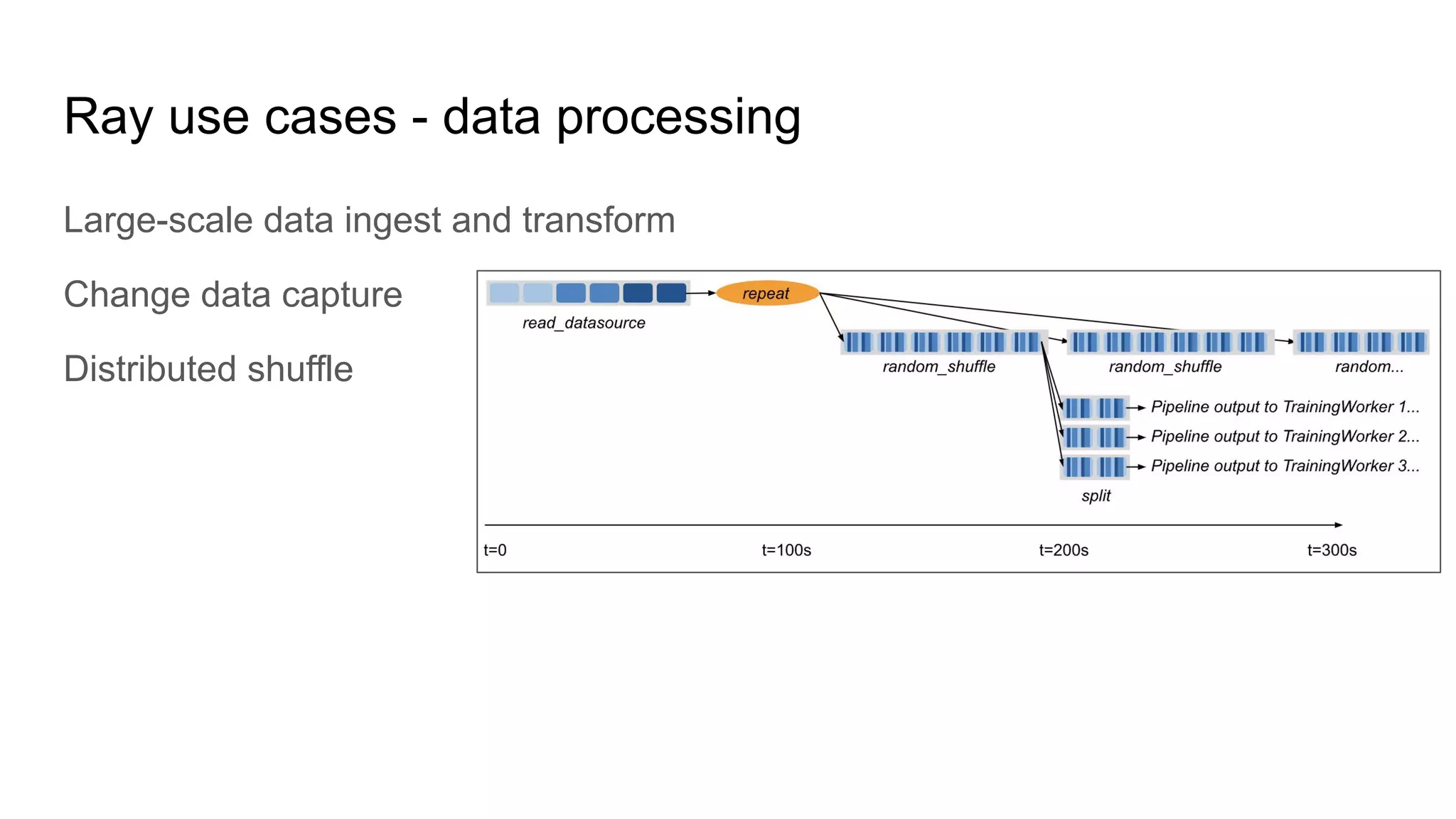
Ray for large-scale data ingestion, transformation, and distributed processing.
Application of Ray for automated model training, hyper-parameter tuning, and reinforcement learning.
Description of Modin's role in distributed processing within the SDK for Pandas.
Links to numerous tutorials available for learning Ray functionalities.
The presentation includes several DEMOs showcasing features of AWS SDK and related services.
Conclusion of the presentation and final thoughts by Chris Fregly.
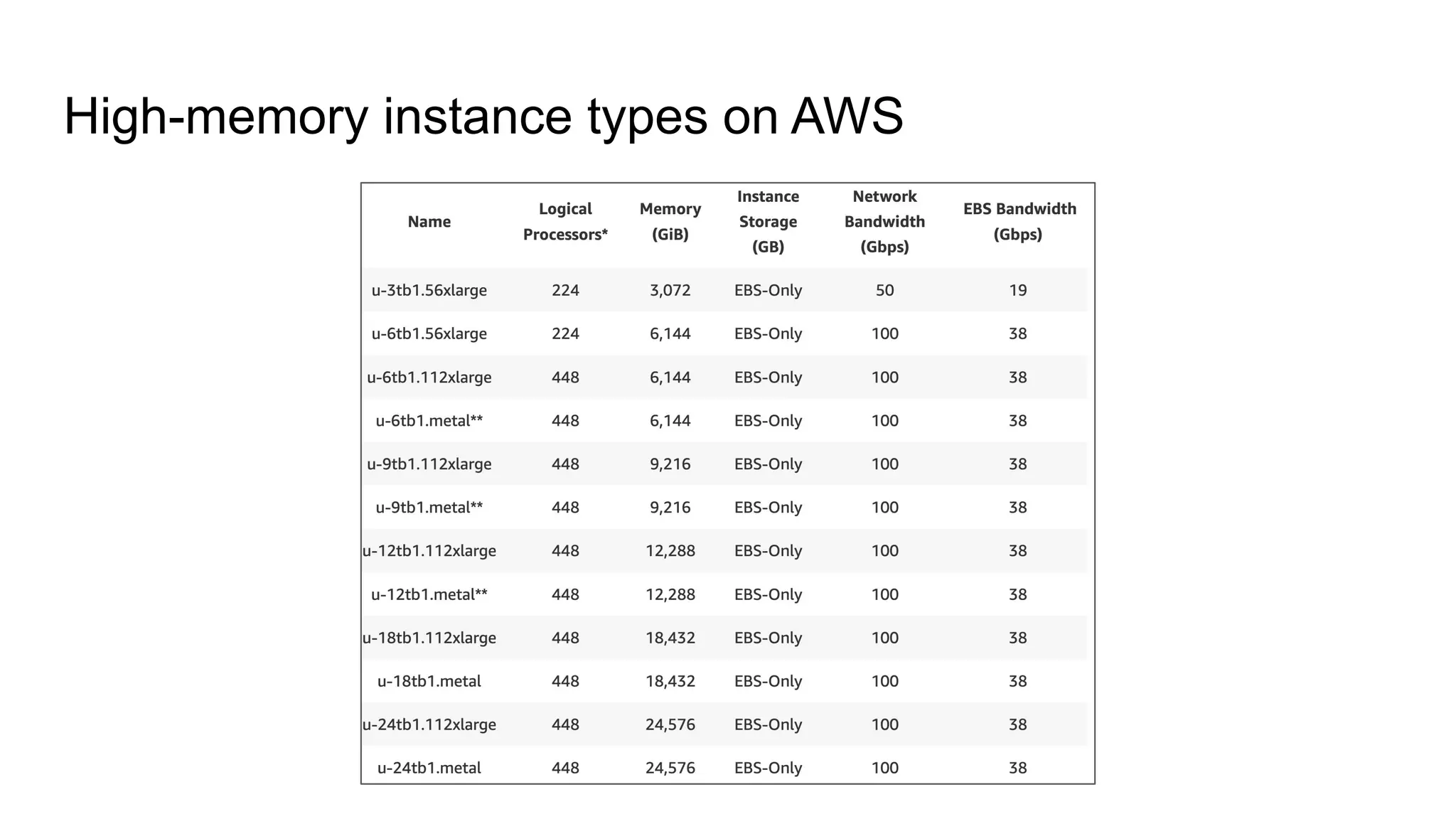
Extra information regarding AWS high-memory instance types.
Overview of AWS instance types designed for high-memory requirements.



































































