Downloaded 10 times











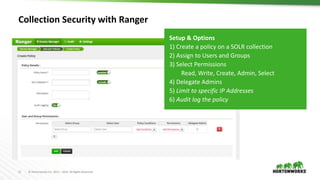


The document discusses search capabilities in Hortonworks Data Platform (HDP) 2.6, including Apache Solr, Banana, and Hadoop connectors. It provides an overview of Solr/Lucene features and deployment options for storing the Solr index on HDFS or local storage. Methods for indexing data into Solr using MapReduce, Pig, Hive, Apache NiFi, and Ranger for collection-level security are also summarized.