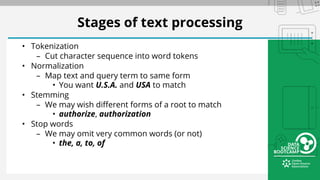
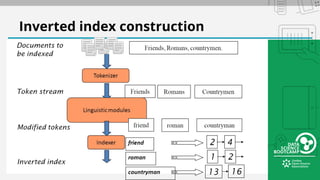
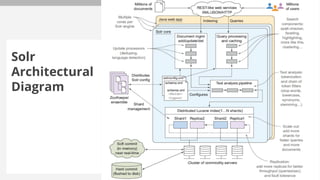
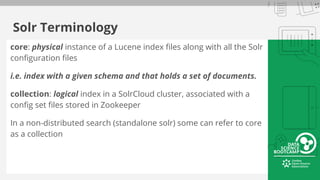
The document outlines a bootcamp on information retrieval (IR) and the use of Solr, led by Kais Hassan, focusing on techniques for unstructured text data search. It covers key concepts such as inverted indexing, Solr architecture, document storage, and field types, including hands-on exercises for working with Solr collections and indexing data. The session also reviews query handling, tokenization, and analysis tools to enhance search functionality within Solr.























![Notable Token(izers|Filters) - 1/2
WhitespaceTokenizer: Creates tokens of characters separated by splitting on whitespace
StandardTokenizerFactory: General purpose tokenizer that strips extraneous characters
LowerCaseFilterFactory: Lowercases the letters in each token
TrimFilterFactory: Trims whitespace at either end of a token.
● Example: " Kittens! ", "Duck" ==> "Kittens!", "Duck".
PatternReplaceFilterFactory: Applies a regex pattern
● Example: pattern="([^a-z])" replacement=""](https://image.slidesharecdn.com/informationretrieval-datasciencebootcamp-160402074116/85/Information-Retrieval-Data-Science-Bootcamp-34-320.jpg)