Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
あしたのオープンソース研究所
PPT, PDF
9,046 views
Apache Hive 紹介
2014年1月23日のあしたのオープンソース研で使用したApache Hive説明資料です。
Technology
◦
Read more
12
Save
Share
Embed
Embed presentation
Download
Downloaded 46 times
1
/ 26
2
/ 26
Most read
3
/ 26
4
/ 26
Most read
5
/ 26
6
/ 26
7
/ 26
8
/ 26
9
/ 26
10
/ 26
11
/ 26
12
/ 26
13
/ 26
14
/ 26
15
/ 26
16
/ 26
17
/ 26
18
/ 26
19
/ 26
20
/ 26
21
/ 26
22
/ 26
23
/ 26
24
/ 26
25
/ 26
26
/ 26
More Related Content
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
2015-10-31 クラウドネイティヴ時代の運用を考える 〜 ドキュメント駆動運用へ
by
Operation Lab, LLC.
PDF
TLS, HTTP/2演習
by
shigeki_ohtsu
PDF
AWS Black Belt Online Seminar Amazon Aurora
by
Amazon Web Services Japan
PDF
Embulk, an open-source plugin-based parallel bulk data loader
by
Sadayuki Furuhashi
PDF
Azure Monitor Logで実現するモダンな管理手法
by
Takeshi Fukuhara
PDF
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
2015-10-31 クラウドネイティヴ時代の運用を考える 〜 ドキュメント駆動運用へ
by
Operation Lab, LLC.
TLS, HTTP/2演習
by
shigeki_ohtsu
AWS Black Belt Online Seminar Amazon Aurora
by
Amazon Web Services Japan
Embulk, an open-source plugin-based parallel bulk data loader
by
Sadayuki Furuhashi
Azure Monitor Logで実現するモダンな管理手法
by
Takeshi Fukuhara
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
What's hot
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PPTX
脱RESTful API設計の提案
by
樽八 仲川
PDF
20210330 AWS Black Belt Online Seminar AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-
by
Amazon Web Services Japan
PDF
nginx入門
by
Takashi Takizawa
PPTX
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
PDF
Apache Airflow入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
CloudFormation/SAMのススメ
by
Eiji KOMINAMI
PDF
Azure Database for PostgreSQL 入門 (PostgreSQL Conference Japan 2021)
by
Keisuke Takahashi
PPTX
HTTP2 最速実装 〜入門編〜
by
Kaoru Maeda
PDF
The Twelve-Factor Appで考えるAWSのサービス開発
by
Amazon Web Services Japan
PDF
超実践 Cloud Spanner 設計講座
by
Samir Hammoudi
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
PDF
Hadoop入門
by
Preferred Networks
PDF
PostgreSQLの冗長化について
by
Soudai Sone
PDF
継承やめろマジやめろ。 なぜイケないのか 解説する
by
TaishiYamada1
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
脱RESTful API設計の提案
by
樽八 仲川
20210330 AWS Black Belt Online Seminar AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-
by
Amazon Web Services Japan
nginx入門
by
Takashi Takizawa
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
Apache Airflow入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
CloudFormation/SAMのススメ
by
Eiji KOMINAMI
Azure Database for PostgreSQL 入門 (PostgreSQL Conference Japan 2021)
by
Keisuke Takahashi
HTTP2 最速実装 〜入門編〜
by
Kaoru Maeda
The Twelve-Factor Appで考えるAWSのサービス開発
by
Amazon Web Services Japan
超実践 Cloud Spanner 設計講座
by
Samir Hammoudi
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
Hadoop入門
by
Preferred Networks
PostgreSQLの冗長化について
by
Soudai Sone
継承やめろマジやめろ。 なぜイケないのか 解説する
by
TaishiYamada1
Similar to Apache Hive 紹介
PDF
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
PDF
"Programming Hive" Reading #1
by
moai kids
PPTX
2012 02-02 mixi engineer's seminor #3
by
Yu Ishikawa
PDF
Hive undocumented feature
by
tamtam180
PDF
Programming Hive Reading #3
by
moai kids
PDF
Hiveハンズオン
by
Satoshi Noto
PDF
Hive chapter 2
by
masahiro_minami
PPTX
Hadoop conference 2013winter_for_slideshare
by
Yu Ishikawa
PDF
株式会社インタースペース 守安様 登壇資料
by
leverages_event
PDF
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
PDF
[Livesence Tech Night] グリーにおけるHiveの運用
by
gree_tech
PDF
PostgreSQL 12の話
by
Masahiko Sawada
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PPTX
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
PDF
Apache Hiveの今とこれから - 2016
by
Yuta Imai
PPTX
Hive on Spark の設計指針を読んでみた
by
Recruit Technologies
PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
PPTX
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
PPTX
HDPをWindowsで動かしてみた
by
adachij2002
PDF
20100930 sig startups
by
Ichiro Fukuda
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
"Programming Hive" Reading #1
by
moai kids
2012 02-02 mixi engineer's seminor #3
by
Yu Ishikawa
Hive undocumented feature
by
tamtam180
Programming Hive Reading #3
by
moai kids
Hiveハンズオン
by
Satoshi Noto
Hive chapter 2
by
masahiro_minami
Hadoop conference 2013winter_for_slideshare
by
Yu Ishikawa
株式会社インタースペース 守安様 登壇資料
by
leverages_event
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
[Livesence Tech Night] グリーにおけるHiveの運用
by
gree_tech
PostgreSQL 12の話
by
Masahiko Sawada
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
Apache Hiveの今とこれから - 2016
by
Yuta Imai
Hive on Spark の設計指針を読んでみた
by
Recruit Technologies
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
HDPをWindowsで動かしてみた
by
adachij2002
20100930 sig startups
by
Ichiro Fukuda
More from あしたのオープンソース研究所
PPT
Datomic&datalog紹介
by
あしたのオープンソース研究所
PPT
Red5
by
あしたのオープンソース研究所
PDF
Friendica_28th_AshitanoKen
by
あしたのオープンソース研究所
PPT
Apache UIMA
by
あしたのオープンソース研究所
PPT
Flume
by
あしたのオープンソース研究所
PDF
Gephi Quick Start (Japanese)
by
あしたのオープンソース研究所
PDF
Gephi Tutorial Visualization (Japanese)
by
あしたのオープンソース研究所
PPT
Cassandra v0.6-siryou
by
あしたのオープンソース研究所
PPT
MongoDB
by
あしたのオープンソース研究所
PDF
Rails.20110405
by
あしたのオープンソース研究所
PPT
S4
by
あしたのオープンソース研究所
PPT
machine learning & apache mahout
by
あしたのオープンソース研究所
PDF
20100831.あしたの研第14回座談会moses.スライド
by
あしたのオープンソース研究所
PDF
Cassandra 分散データベース
by
あしたのオープンソース研究所
Datomic&datalog紹介
by
あしたのオープンソース研究所
Red5
by
あしたのオープンソース研究所
Friendica_28th_AshitanoKen
by
あしたのオープンソース研究所
Apache UIMA
by
あしたのオープンソース研究所
Flume
by
あしたのオープンソース研究所
Gephi Quick Start (Japanese)
by
あしたのオープンソース研究所
Gephi Tutorial Visualization (Japanese)
by
あしたのオープンソース研究所
Cassandra v0.6-siryou
by
あしたのオープンソース研究所
MongoDB
by
あしたのオープンソース研究所
Rails.20110405
by
あしたのオープンソース研究所
S4
by
あしたのオープンソース研究所
machine learning & apache mahout
by
あしたのオープンソース研究所
20100831.あしたの研第14回座談会moses.スライド
by
あしたのオープンソース研究所
Cassandra 分散データベース
by
あしたのオープンソース研究所
Apache Hive 紹介
1.
Apache Hive インフォサイエンス株式会社 永江
哲朗 Copyright © Infoscience Corporation. All rights reserved.
2.
Hive のことをおおまかに言うと … ユーザーが
SQL に似たクエリ言語 HiveQL でクエリを書く。 ↓ Hive がそれを map/reduce のジョブに変換して Hadoop に実行させる。 浅く使う場合には、クエリを使うユーザーは内部構造をあまり知らなくていいとい うところは DBMS に似ています。 Copyright © Infoscience Corporation. All rights
3.
Apache Hive の特徴 Apache
Hive の特徴 ・ Hadoop 互換のファイルシステムに格納されたデータセットの分析を行う。 ・ map/reduce をサポートした SQL ライクな「 HiveQL 」という言語を用いる。 ・クエリの高速化のため、ビットマップインデックスを含めたインデックス機能も 実装している Copyright © Infoscience Corporation. All rights
4.
Apache Hive の機能 Apache
Hive の機能 ・高速化のためインデックスを作成して使用できる。 ・別の種類のストレージタイプが使える。たとえばプレーンテキスト、 RCFile, HBase など ・クエリ実行時の構文チェック時間を大幅に短縮するため、メタデータを RDBMS に格納する機能をもつ。 ・ Hadoop 環境に格納された圧縮データを扱う機能をもつ。 ・日付型や文字列型を扱ったり他のデータ操作を可能とする、組み込みユーザ定義 関数( UDF) が使える。組み込み関数で用意されていない機能もユーザが自作 UDF を作成することで対応できる。 ・ SQL ライクなクエリ言語 (HiveQL) 。これは内部的に Map/Reduce ジョブに変換 される。 Copyright © Infoscience Corporation. All rights
5.
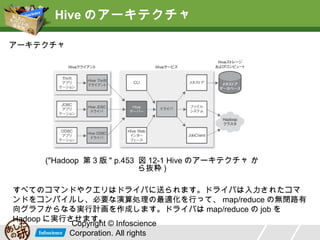
Hive のアーキテクチャ アーキテクチャ ("Hadoop 第
3 版 " p.453 図 12-1 Hive のアーキテクチャ か ら抜粋 ) すべてのコマンドやクエリはドライバに送られます。ドライバは入力されたコマ ンドをコンパイルし、必要な演算処理の最適化を行って、 map/reduce の無閉路有 向グラフからなる実行計画を作成します。ドライバは map/reduce の job を Hadoop に実行させます。 Copyright © Infoscience Corporation. All rights
6.
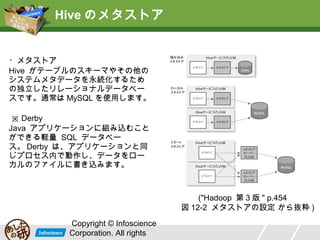
Hive のメタストア ・メタストア Hive がテーブルのスキーマやその他の システムメタデータを永続化するため の独立したリレーショナルデータベー スです。通常は
MySQL を使用します。 ※ Derby Java アプリケーションに組み込むこと ができる軽量 SQL データベー ス。 Derby は、アプリケーションと同 じプロセス内で動作し、データをロー カルのファイルに書き込みます。 ("Hadoop 第 3 版 " p.454 図 12-2 メタストアの設定 から抜粋 ) Copyright © Infoscience Corporation. All rights
7.
Hive のデータ型 プリミティブと複合型 プリミティブ :
INT, DOUBLE など 複合型 : ARRAY, MAP, STRUCT (RDB にはありません ) ("Hadoop 第 3 版 " p.459 表 12-3 Hive のデータ型 から抜粋 ) Copyright © Infoscience Corporation. All rights
8.
ファイルフォーマット (1) ファイルフォーマット TAB や空白はレコードの中でよく見られるので、区切り文字には制御文字を使う ことが多いようです。 区切り文字 説明 n テキストファイルでは各行がレコードになるので、改行 文字がレコードを区切ることになります。 ^A (
Control-A ) フィールド(列)同士を区切る。 CREATE TABLE 文で 明示的に指定する場合は、 8 進表記で 001 と書く。 ^B ARRAY や STRUCT の要素、あるいは MAP 中のキー / 値ペアを区切る。 CREATE TABLE 文で明示的に指定 する場合は、 8 進表記で 002 と書く。 ^C MAP 中のキー / 値ペアのキーと対応する値を区切る。 CREATE TABLE 文で明示的に指定する場合は、 8 進表 記で 003 と書く。 「プログラミング Hive 」 p.47 表 3-3 Hive におけるデフォルトのレコード及びフィールドの区切り文字 から抜粋 Copyright © Infoscience Corporation. All rights
9.
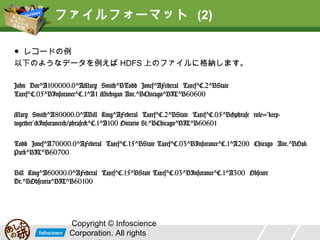
ファイルフォーマット (2) ● レコードの例 以下のようなデータを例えば
HDFS 上のファイルに格納します。 John Doe^A100000.0^AMary Smith^BTodd Jones^AFederal Taxes^C.2^BState Taxes^C.05^BInsurance^C.1^A1 Michigan Ave.^BChicago^BIL^B60600 Mary Smith^A80000.0^ABill King^AFederal Taxes^C.2^BState Taxes^C.05^B<phrase role="keep-together">Insurance</phrase>^C.1^A100 Ontario St.^BChicago^BIL^B60601 Todd Jones^A70000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A200 Chicago Ave.^BOak Park^BIL^B60700 Bill King^A60000.0^AFederal Taxes^C.15^BState Taxes^C.03^BInsurance^C.1^A300 Obscure Dr.^BObscuria^BIL^B60100 Copyright © Infoscience Corporation. All rights
10.
書き込み時のスキーマ適用と読み込み時のスキーマ適用 ● 書き込み時のスキーマ適用: RDBMS 読み込まれたデータがスキーマに則していなければ、そのデータのロードは拒否 されます。 ●
読み込み時のスキーマ適用: Hive 読み込み時点ではデータを確認せず、クエリの発行時に確認を行います。スキー マに即していないデータはクエリ発行時にエラーとなります。 メリット デメリット 書き込み時の スキーマ適用 クエリの実行パフォーマン データベースへのデータ スは高速になる。 のロードには時間がかか る。 読み込み時の スキーマ適用 初期のデータ読み込みはき クエリの実行が遅い。 わめて高速になる。 Copyright © Infoscience Corporation. All rights
11.
HiveQL : テーブルの作成 CREATE
TABLE 文の例 CREATE TABLE records (year STRING, temperature INT, quality INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't'; ROW FORMAT DELIMITED FIELDS TERMINATED BY 't': データファイル中の各行はタブ区切りのテキストということを示しています。 ※ CREATE TABLE を実行しても、 RDB のように実際に DB の中にセグメントが 作られるわけではありません。メタストアにスキーマ情報が登録されます。 Copyright © Infoscience Corporation. All rights
12.
Hive のパーティション •Hive は、テーブルをパーティション群として構成します。パーティションは、テ ーブルを、例えば日付のようなパーティション列の値に基づき、部分部分に大きく 分割する方法です。パーティションを使えば、データの断片群に対するクエリの実 行を高速化できます。 •パーティションは、テーブルの作成時に
PARTITIONED BY 節で指定しま す。 PARTITIONED BY 節は、列の定義のリストをとります。 例 CREATE TABLE logs (ts BIGINT, line STRING) PARTITIONED BY (dt STRING, country STRING); 上記の場合、日付 ( 文字列 ) と国名でパーティションが 作られます ( 例 . 右図参照 ) 。 Copyright © Infoscience Corporation. All rights ("Hadoop 第 3 版 " p.464 より抜粋 )
13.
HiveQL : テーブルの確認 テーブルの確認 hive>
SHOW TABLES; ユーザーが見られるテーブルをすべて表示します。 hive> SHOW TABLES '.*s'; 's' で終わるテーブルをすべて表示します。 ( 正規表現 ) hive> DESCRIBE invites; 列を表示します。 例 hive> describe invites; OK foo int bar string ds string # Partition Information # col_name data_type None None None comment ds string None Time taken: 0.265 seconds, Fetched: 8 row(s) Copyright © Infoscience Corporation. All rights
14.
HiveQL : データのロード データのロードの例 LOAD
DATA LOCAL INPATH 'input/ncdc/micro-tab/sample.txt' OVERWRITE INTO TABLE records; このコマンドを実行すると、 Hive は指定されたローカルファイルを Hive の保 管用ディレクトリに保存します。例えば HDFS 上の Hive 保管用ディレクトリ上に ファイルとして保存します。 ※ OVERWRITE キーワードは、ディレクトリ中にそのテーブル用のファイルがす でにあった場合、 Hive に対して、それらを削除するように指示します。 Copyright © Infoscience Corporation. All rights
15.
HiveQL: INSERT データをインポートするには INSERT
文を使います。 (Hive には今のところ UPDATE, DELETE はありません ) INSERT の例 hive> INSERT OVERWRITE TABLE events > SELECT a.* FROM profiles a WHERE a.key < 100; profiles というテーブルからその key という列の値が 100 未満の行を抽出し、それ を events というテーブルに INSERT しています。 ※ 上記の例では OVERWRITE キーワードが指定されているため、既存のデータ は新たに指定されたデータに置き換わります。 Copyright © Infoscience Corporation. All rights
16.
HiveQL : SELECT クエリの例 SELECT
weekday, COUNT(*) FROM u_data_new GROUP BY weekday; このように、 SQL に似た構文が使用できます。 Copyright © Infoscience Corporation. All rights
17.
HiveQL のクエリの制限 (1) •SELECT
に関して FROM には単一のテーブル もしくは ビュー しか書けません。 •( 内部 ) 結合に関して Hive では、結合の述部に複数の式を AND キーワードで区切って並べ、複数の列を 使って結合させることができます。クエリに JOIN...ON... 節を追加すれば、 3 つ以 上のテーブルを結合することもできます。 例 SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id); Copyright © Infoscience Corporation. All rights
18.
HiveQL のクエリの制限 (2) •サブクエリ FROM
節中にしか書けません。 例 SELECT station, year, AVG(max_temperature) FROM ( SELECT station, year, MAX(temperature) AS max_temperature FROM records2 WHERE temperature != 9999 AND (quality = 0 OR quality = 1 OR quality = 4 OR quality = 5 OR quality = 9) GROUP BY station, year ) mt GROUP BY station, year; Copyright © Infoscience Corporation. All rights
19.
HiveQL : 関数 HiveQL
で使用できる関数 ・数値関数 : round, floor, ceil, rand, exp, ln, pow, sqrt, … 等 ・集計関数: count, sum, avg, min, max, variance, … 等 ・テーブル生成関数 : json_tuple ( 複数の名前をとってタプルを返す ), parse_url_tuple 等 ・その他の組み込み関数 length, reverse, concat, substr, upper, lower, … 等 Copyright © Infoscience Corporation. All rights
20.
HiveQL : ビュー •ビュー 読み出しのみ。マテリアライズド・ビューはサポートされていません。 その
ビューを参照する文が実行された時点で、ビューの SELECT 文が実行され ます。 例 CREATE VIEW max_temperatures (station, year, max_temperature) AS SELECT station, year, MAX(temperature) FROM valid_records GROUP BY station, year; Copyright © Infoscience Corporation. All rights
21.
HiveQL : インデックス 現時点では、インデックスには
compact と bitmap の 2 種類があります。 • compact インデックス それぞれの値に対し、各ファイル内のオフセット(基準点からの距離)ではなく、 HDFS のブロック番号を保存します。そのため、 compact インデックスはそれ ほどディスク容量を消費しませんが、それでも値が近傍の行にまとまっているよう な場合には効果的です。 例. CREATE TABLE t(i int, j int); CREATE INDEX x ON TABLE t(j) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'; •bitmap インデックス 特定の値が現れている行を、圧縮されたビット集合を使って効率的に保存するもの で、通常はカーディナリティの低い列(性別や国など)に対して使うのが適切です 。 Copyright © Infoscience Corporation. All rights
22.
HiveQL : ユーザー定義関数 •ユーザー定義関数を書けば、独自の処理のコードを
Hive に組み込み、 Hive のクエ リ中から簡単に呼び出すことができます。 •ユーザー定義関数 (User-Defined Function:UDF) UDF は、 1 つの行を受け取り、 1 つの出力行を生成します。数値関数や文字列関数 など。 •ユーザー定義集計関数 (User-Defined Function:UDAF) UDAF は、複数の入力行を受け取り、 1 つの出力行を生成します。 COUNT や MAX といった関数など。 •ユーザー定義テーブル生成関数 (User-Defined Table-generating Function:UDTF) UDTF は、 1 つの行に対して処理を行い、複数の行 ( すなわちテーブル ) を出力しま す。 Copyright © Infoscience Corporation. All rights
23.
Hive の事例 ・ KIXEYE オンラインゲームのログの分析に
Hive を使用している。 https://cwiki.apache.org/confluence/download/attachments/27362054/Hive-kixeyeanalytics.pdf?version=1&modificationDate=1360856744000&api=v2 ・ NASA ジェット推進研究所 地域気象モデル評価システムで使用。 ( 「プログラミング Hive 」 p.317 ~ 321) Copyright © Infoscience Corporation. All rights
24.
Impala, Presto Hive にはジョブの実行に時間がかかるという弱点があります。 Hive
の有効性を受け、その問題を解決した Impara や Presto という OSS が開発さ れています。 ・ Impala Hive よりも高速。 map/reduce を使用しない。 耐障害性がない。 Cloudera により開発される。 ・ Presto アドホックなクエリの結果をインタラクティブに得ることに最適化。 map/reduce とは異なるアーキテクチャ。 Facebook により開発される。 Copyright © Infoscience Corporation. All rights
25.
まとめ ・ Hadoop 互換のファイルシステムに格納されたデータセットの分析を行う。 ・
map/reduce をサポートした SQL ライクな「 HiveQL 」という言語を用いる。 ・ Hadoop を使ったクエリで mapreduce のプログラミングが不要になるの で、 MapReduce に詳しくない人でも Hadoop を使って分析することが可能になる 。 → いままでのような、ユーザーが RDBMS を使って分析を行うということの延長 線上にある。 ・ Hive では一般のユーザーでも Hadoop のスケーラブルなところを活かせる。 cf. RDBMS の性能はスケーラブルになりにくい。シャーディングにすることも可 能だが運用が面倒になる。 NoSQL はスケーラブルだが ( クエリは ) 一般のユーザ ーには難しい。 Copyright © Infoscience Corporation. All rights
26.
参考文献 ・”オライリーセミナー Hive 入門
" 嶋内 翔 著 (http://www.slideshare.net/Cloudera_jp/hive-20130724) ・ "Hadoop 第 3 版 " (12 章 ), オライリー・ジャパン、 Tom White 著、 Sky 株式会社 玉川 竜司、兼田 聖司 訳 ・ " プログラミング Hive", オライリー・ジャパン、 Edward Capriolo, Dean Wampler, Jason Rutherglen 著、 Sky 株式会社 玉川 竜司 訳 ・ Apache Hive, wikipedia (http://ja.wikipedia.org/wiki/Apache_Hive, http://en.wikipedia.org/wiki/Apache_Hive) ・ Apache Hive Wiki: GettingStarted https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStartedInstallingHivefromaStableRelease ・ Hadoop クイックスタートガイド http://metasearch.sourceforge.jp/wiki/index.php?Hadoop%A5%AF %A5%A4%A5%C3%A5%AF%A5%B9%A5%BF%A1%BC%A5%C8%A5%AC %A5%A4%A5%C9 Copyright © Infoscience Corporation. All rights
Download



























































![[Livesence Tech Night] グリーにおけるHiveの運用](https://cdn.slidesharecdn.com/ss_thumbnails/livesencetechnight-150602053505-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















