Downloaded 183 times


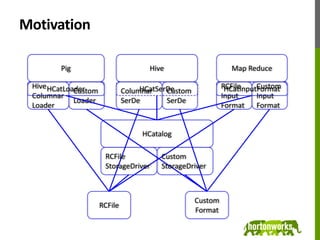

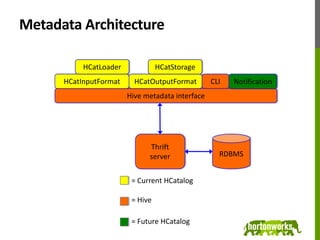






HCatalog is a table management and metadata layer for Hadoop that allows users to access data in different formats like RCFile and Hive in a uniform manner. It provides a metadata abstraction layer that allows data producers to declare schema for output data, and consumers to understand the schema to make sense of that data. This allows data sharing across different tools like Pig, MapReduce, Hive and more without needing to know the internal data representation. The project was recently accepted into the Apache incubator and the 0.1 release supports reading and writing data from Pig, MapReduce and Hive. Future plans include adding support for storing data in HBase and improving integration with other Hadoop components.
































































































