Download as PDF, PPTX










![Collecting raw web data is not enough
2015-05-15T00:26:41.328Z,3,D,
[ip_hidden],i1xszg0f-19hqrje,"Mozilla/5.0 (Windows NT
5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
42.0.2311.152 Safari/537.36",”[url_hidden]",
7279848891,@906,"https://www.google.pl/",vuser-history-
allegro-1-
hc20150509.1,"122_100003_Park@700:html_620x100_single_ban
ner:See offer"
IP, URL, cookie, user-agent, timestamp](https://image.slidesharecdn.com/deepbiitbsb2bconferencev20151012enpublish-151014203815-lva1-app6892/75/Real-time-big-data-analytics-based-on-product-recommendations-case-study-12-2048.jpg)




![So, how to build tailored recommendations?
Pick an algorithm that is suitable for the problem
Product [ feature_1, feature_2, …, feature_N]
User [ feature_1, feature_2, …, feature_N]
User [ product_1, product_2, …, product_N]](https://image.slidesharecdn.com/deepbiitbsb2bconferencev20151012enpublish-151014203815-lva1-app6892/75/Real-time-big-data-analytics-based-on-product-recommendations-case-study-19-2048.jpg)





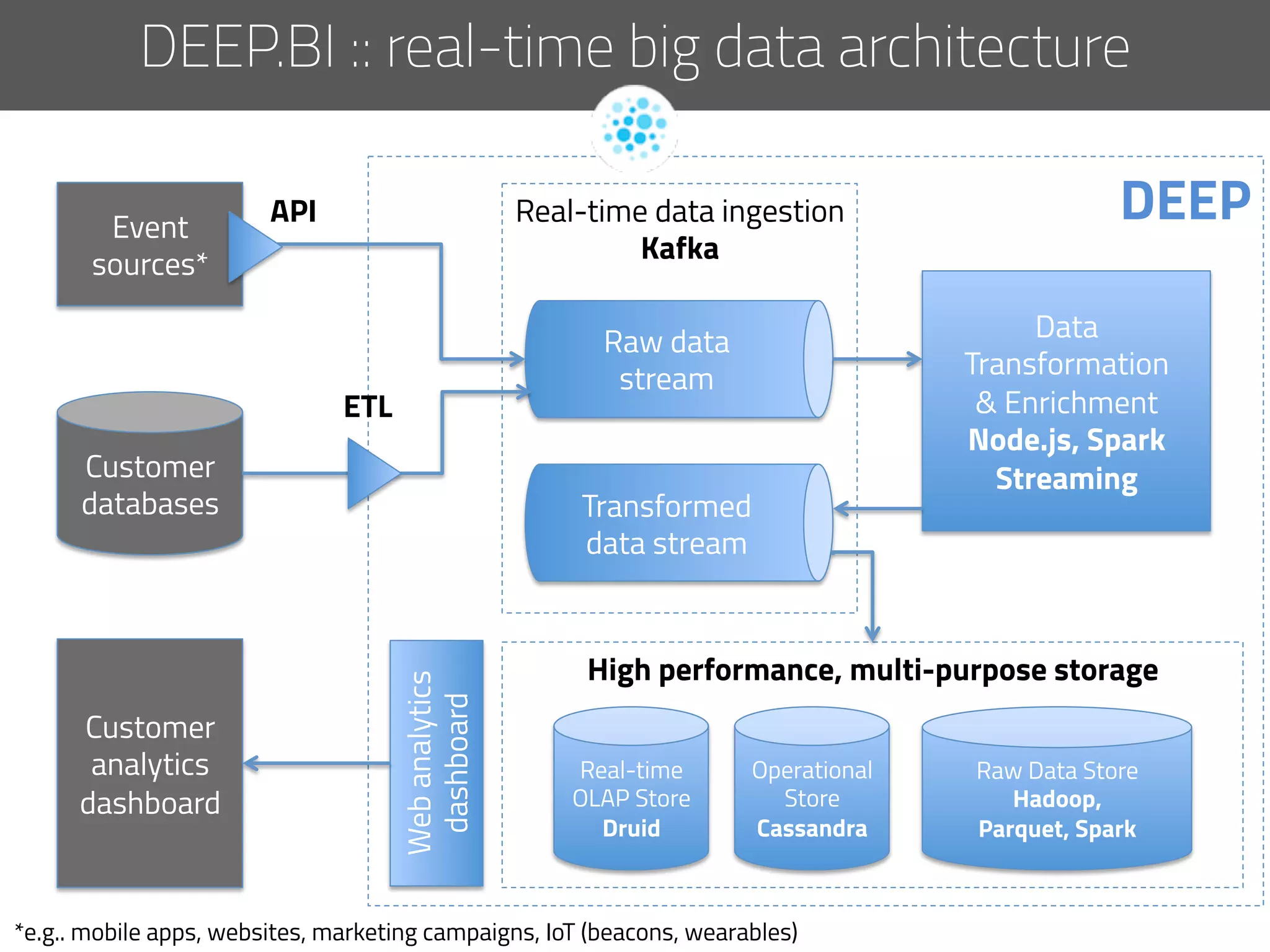
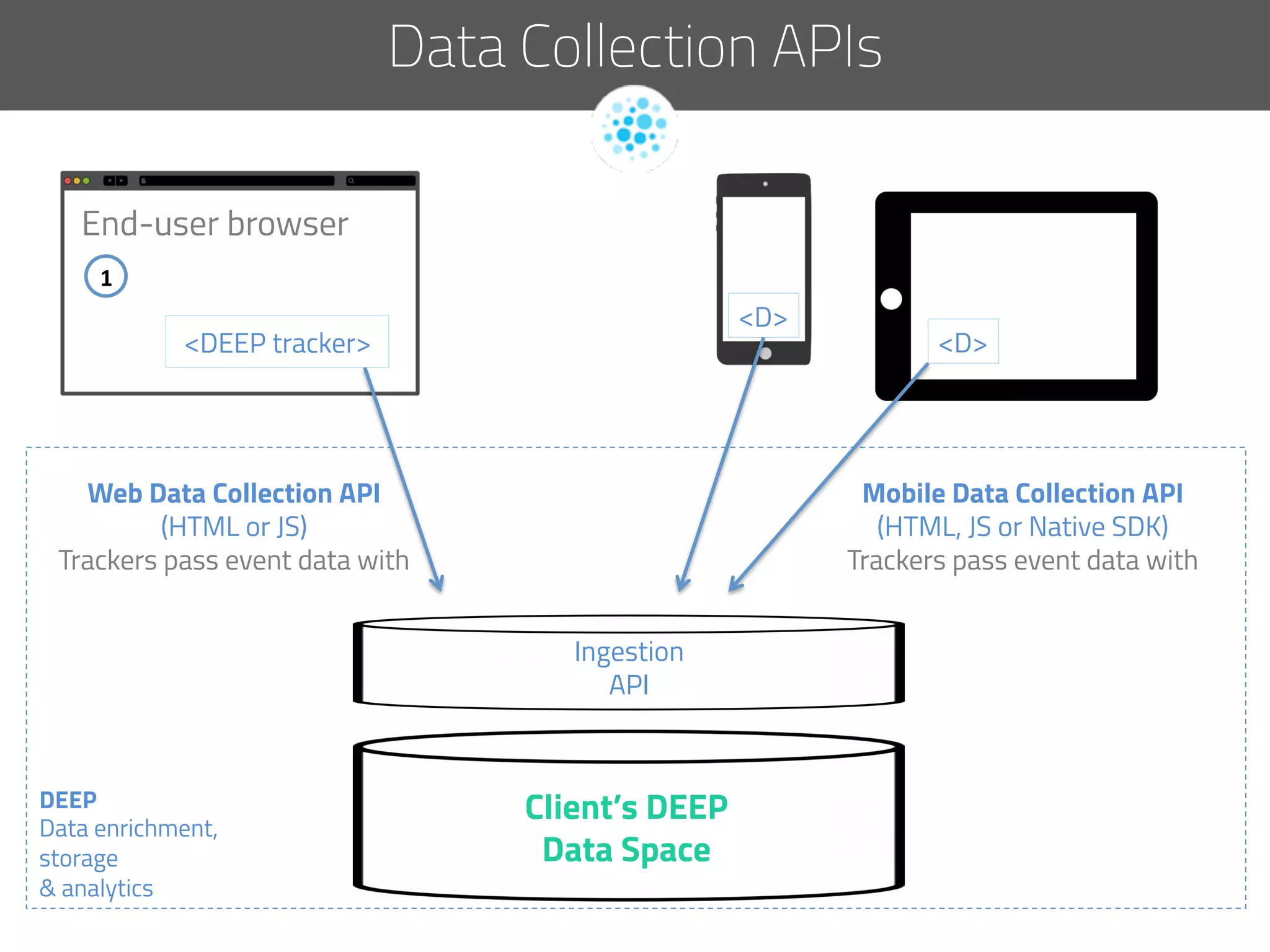

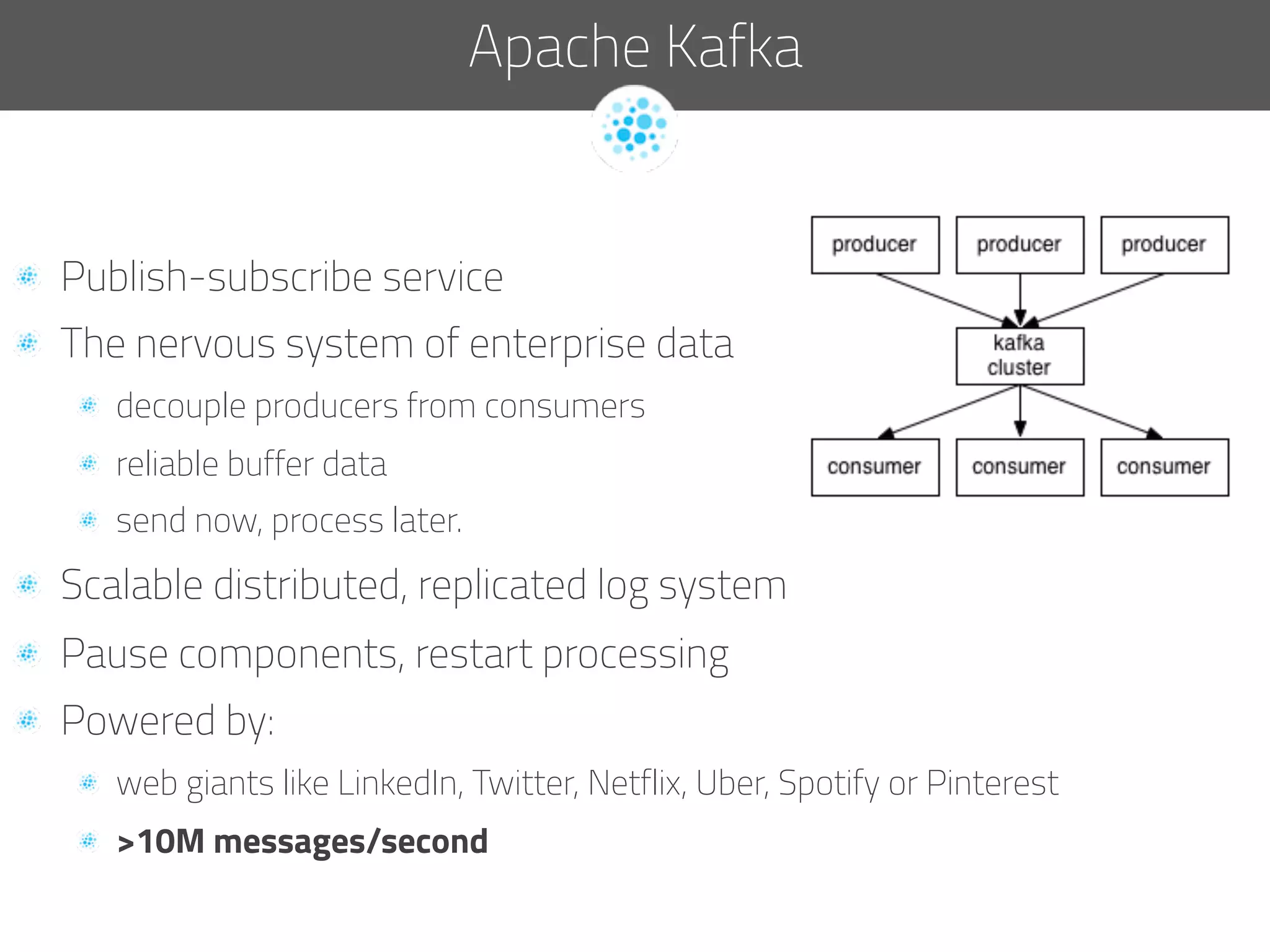
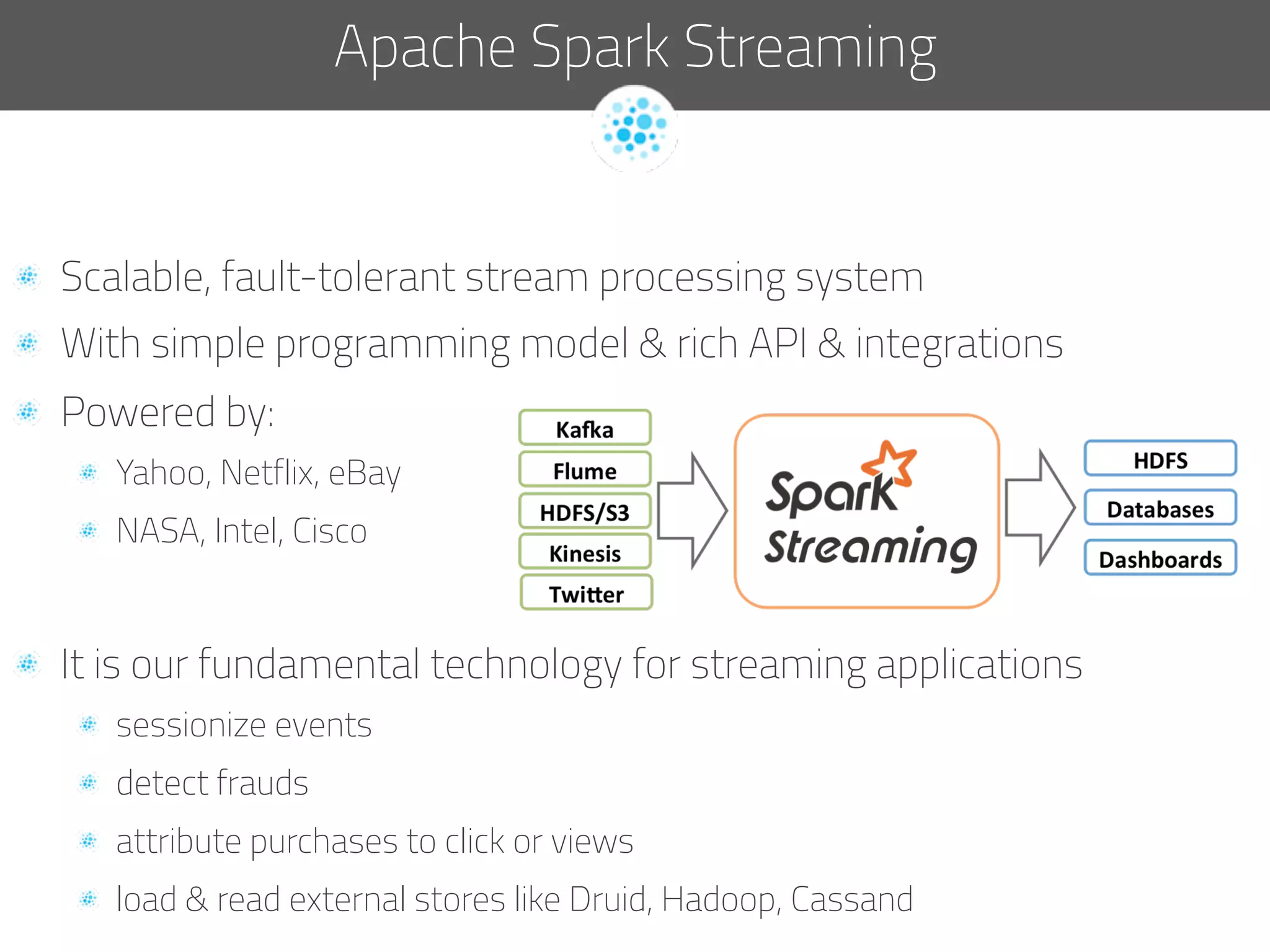






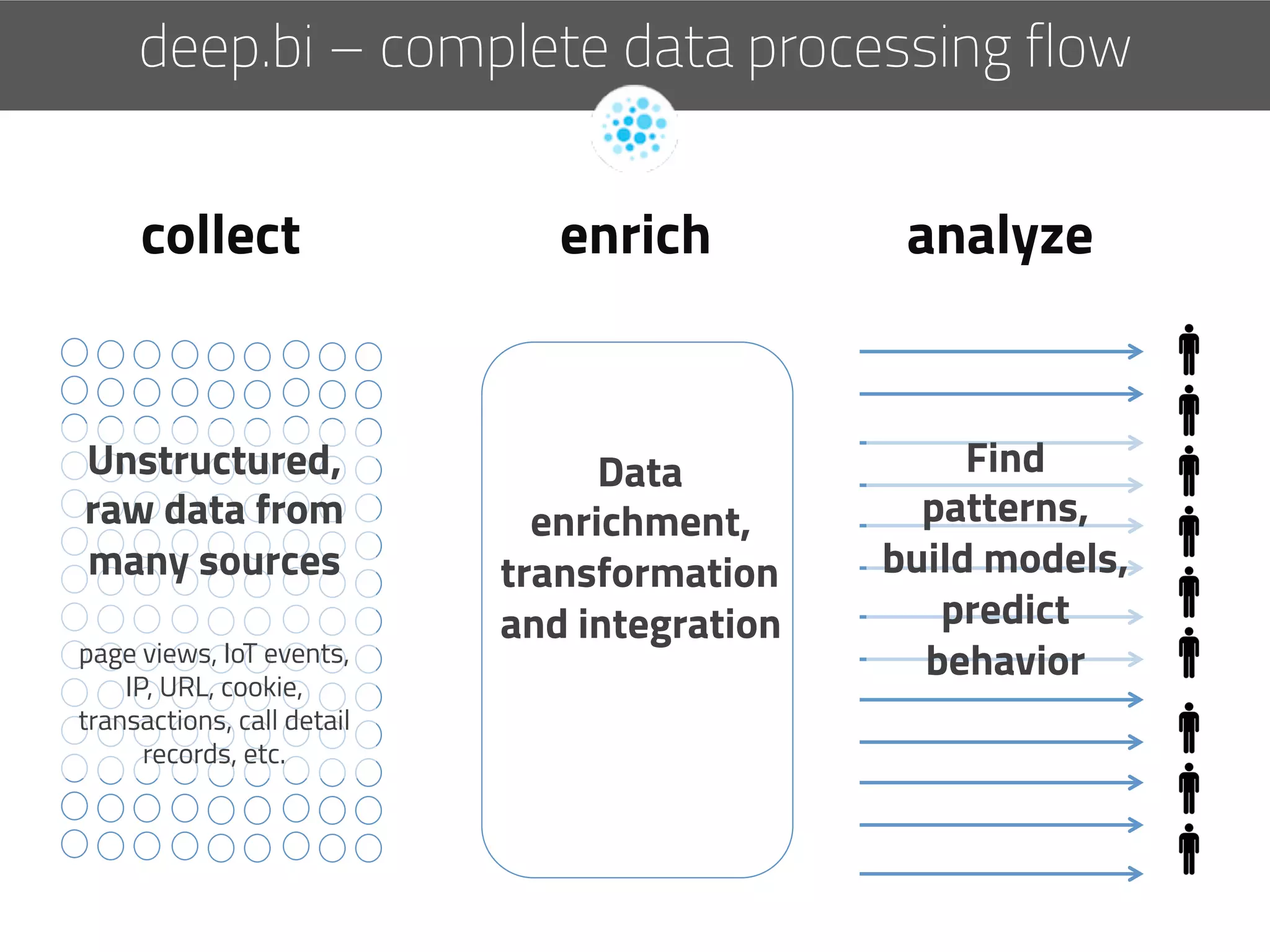
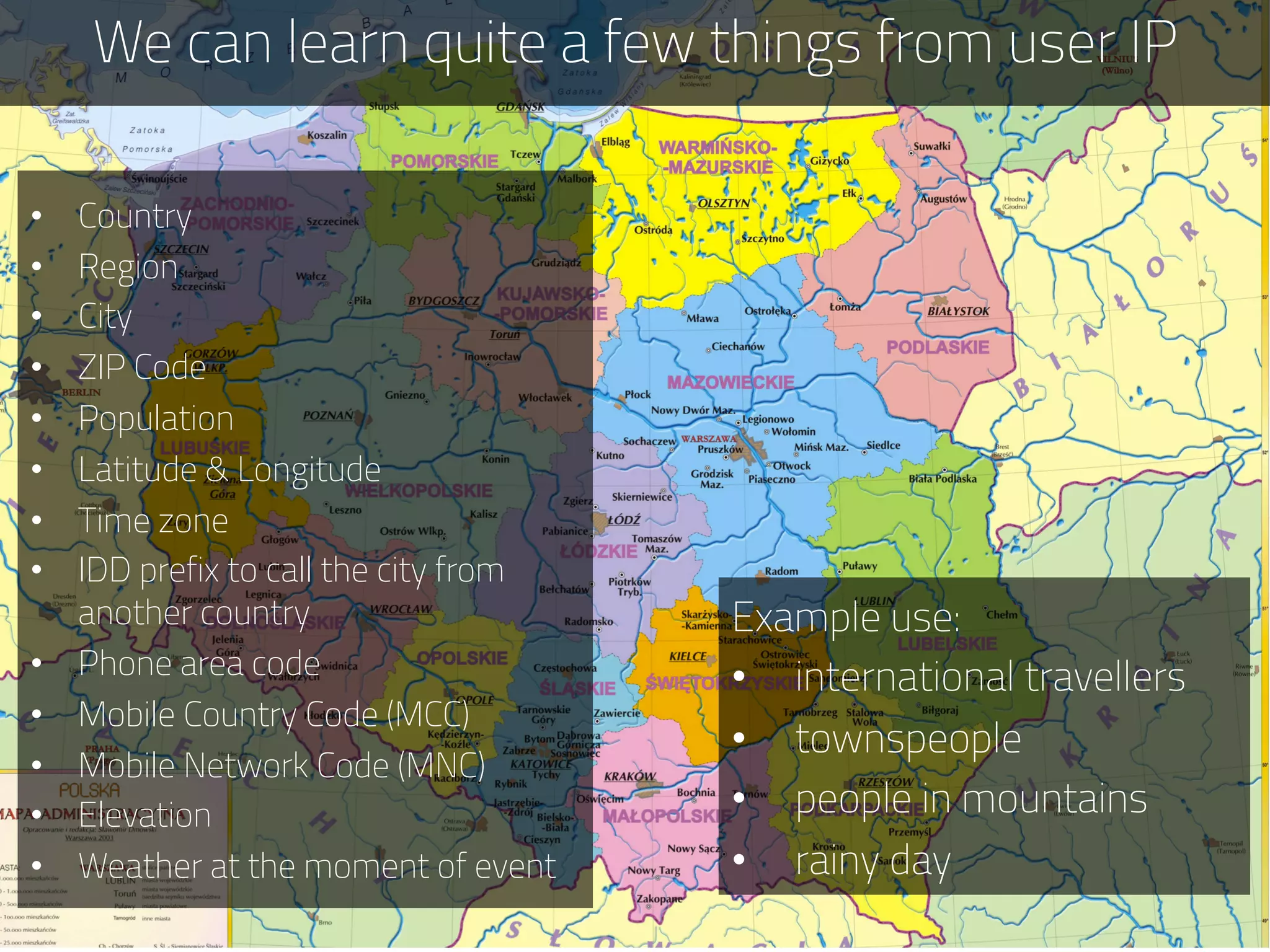
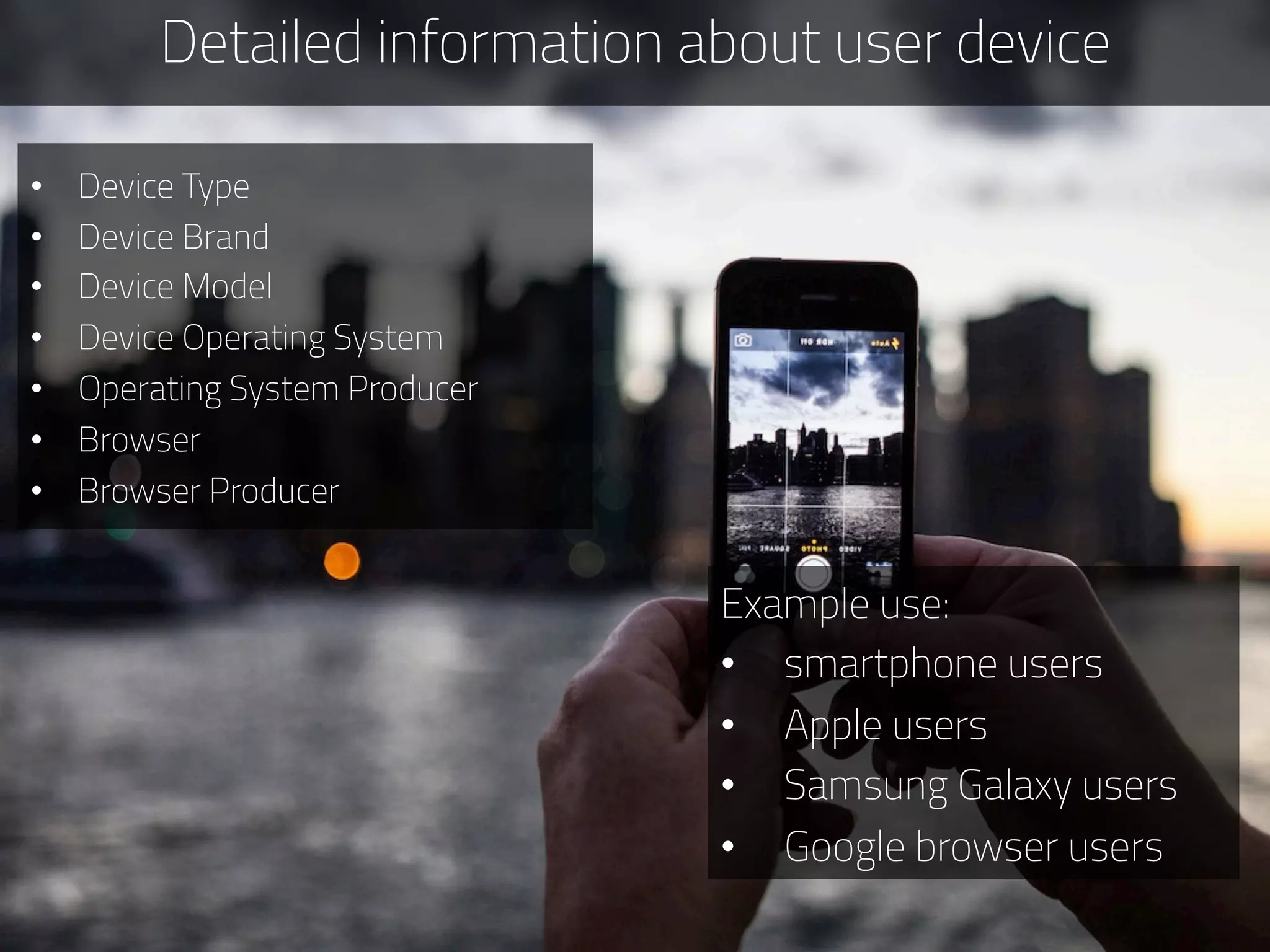
The document discusses the development of deep.bi, a big data analytics solution designed to provide real-time product recommendations for high-growth companies. It highlights the challenges faced with traditional SQL and NoSQL databases and outlines how deep.bi solves fast data problems through scalable data collection, enrichment, and analytics. Key features include deep data enrichment and the ability to predict user behavior based on various data points, ultimately enhancing targeted marketing efforts.

































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















