


![Getting Data into HCatalog – DML and DDL
14
LOAD Files into tables
Copy / move data from HDFS or local filesystem into HCatalog tables
LOAD
DATA
[LOCAL]
INPATH
'filepath'
[OVERWRITE]
INTO
TABLE
tablename
[PARTITION
(partcol1=val1,
partcol2=val2
...)];
INSERT data from a query into tables
Query results can be inserted into tables of file system directories by using the insert clause.
INSERT
OVERWRITE
TABLE
tablename1
[PARTITION
(partcol1=val1,
partcol2=val2
...)
[IF
NOT
EXISTS]]
select_statement1
FROM
from_statement;
INSERT
INTO
TABLE
tablename1
[PARTITION
(partcol1=val1,
partcol2=val2
...)]
select_statement1
FROM
from_statement;
HCatalog also supports multiple inserts in the same statement or dynamic partition inserts.
ALTER TABLE ADD PARTITIONS
ALTER
TABLE
table_name
ADD
PARTITION
(partCol
=
'value1')
location
'loc1’;](https://image.slidesharecdn.com/datadiscoveryonhadoop-150710015723-lva1-app6891/75/Strata-Conference-Hadoop-World-San-Jose-2015-Data-Discovery-on-Hadoop-14-2048.jpg)

![HCatalog Notifications
17
Namespace:
E.g.
“hcat.thebestcluster”
JMS
Topic:
E.g.
“<dbname>.<tablename>”
Sample
JMS
Notification
{
"timestamp"
:
1360272556,
"eventType"
:
"ADD_PARTITION",
"server"
:
"thebestcluster-‐hcat.dc1.grid.yahoo.com",
"servicePrincipal"
:
"hcat/thebestcluster-‐hcat.dc1.grid.yahoo.com@GRID.YAHOO.COM",
"db"
:
"xyz",
"table"
:
"search",
"partitions":
[
{
"locale"
:
"US",
"datestamp"
:
"20140602"
},
{
"locale"
:
"UK",
"datestamp"
:
"20140602"
},
{
"locale"
:
"IN",
"datestamp"
:
"20140602"
}
]
}
HCatalog uses JMS (ActiveMQ) notifications that can be sent for add_database, add_table, add_partition, drop_partition,
drop_table, and drop_database. Notifications can be extended for schema change communication
HCat
Client
HCat
MetaStore
ActiveMQ
Server
Register Channel Publish to listener channels
Subscribers](https://image.slidesharecdn.com/datadiscoveryonhadoop-150710015723-lva1-app6891/75/Strata-Conference-Hadoop-World-San-Jose-2015-Data-Discovery-on-Hadoop-17-2048.jpg)


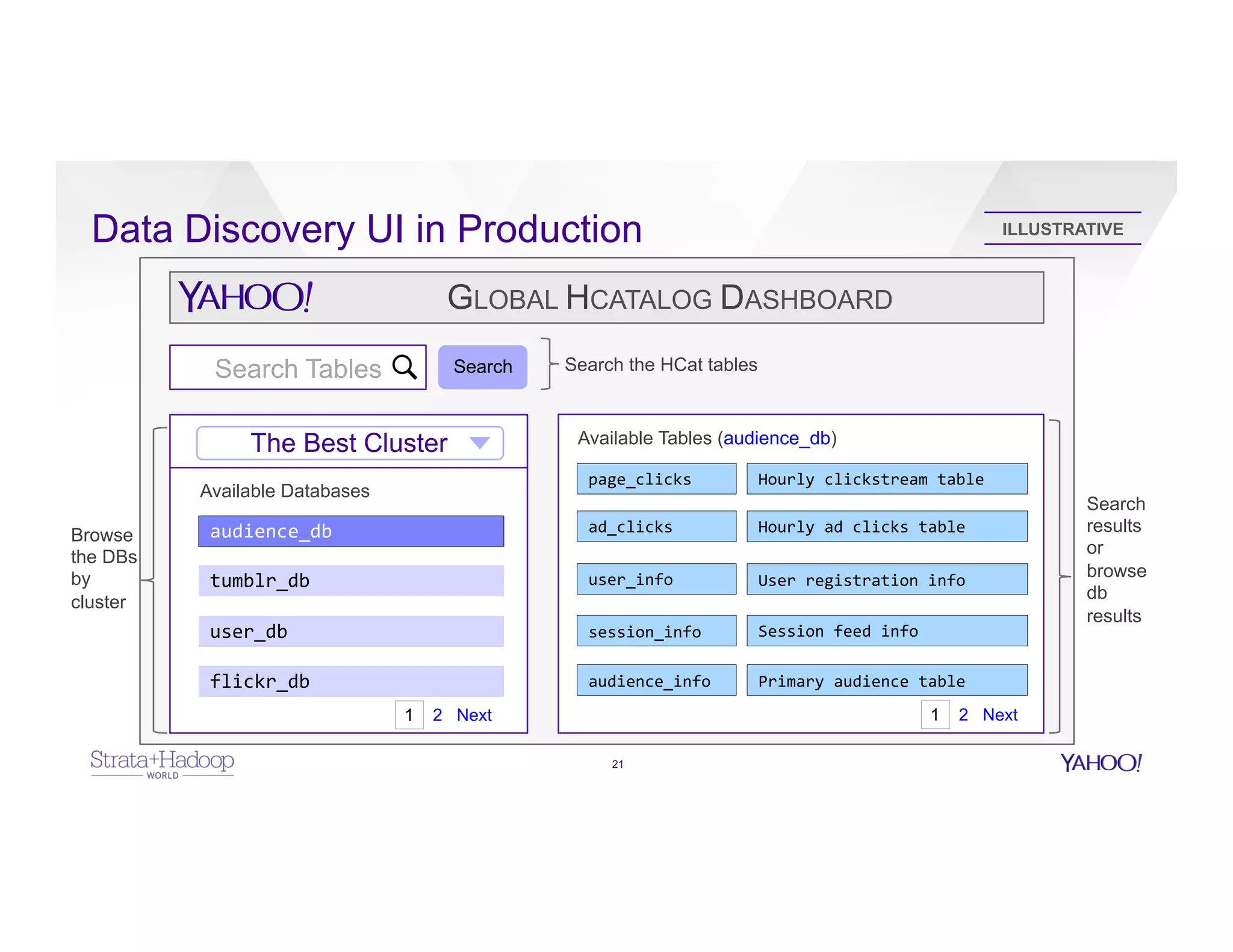
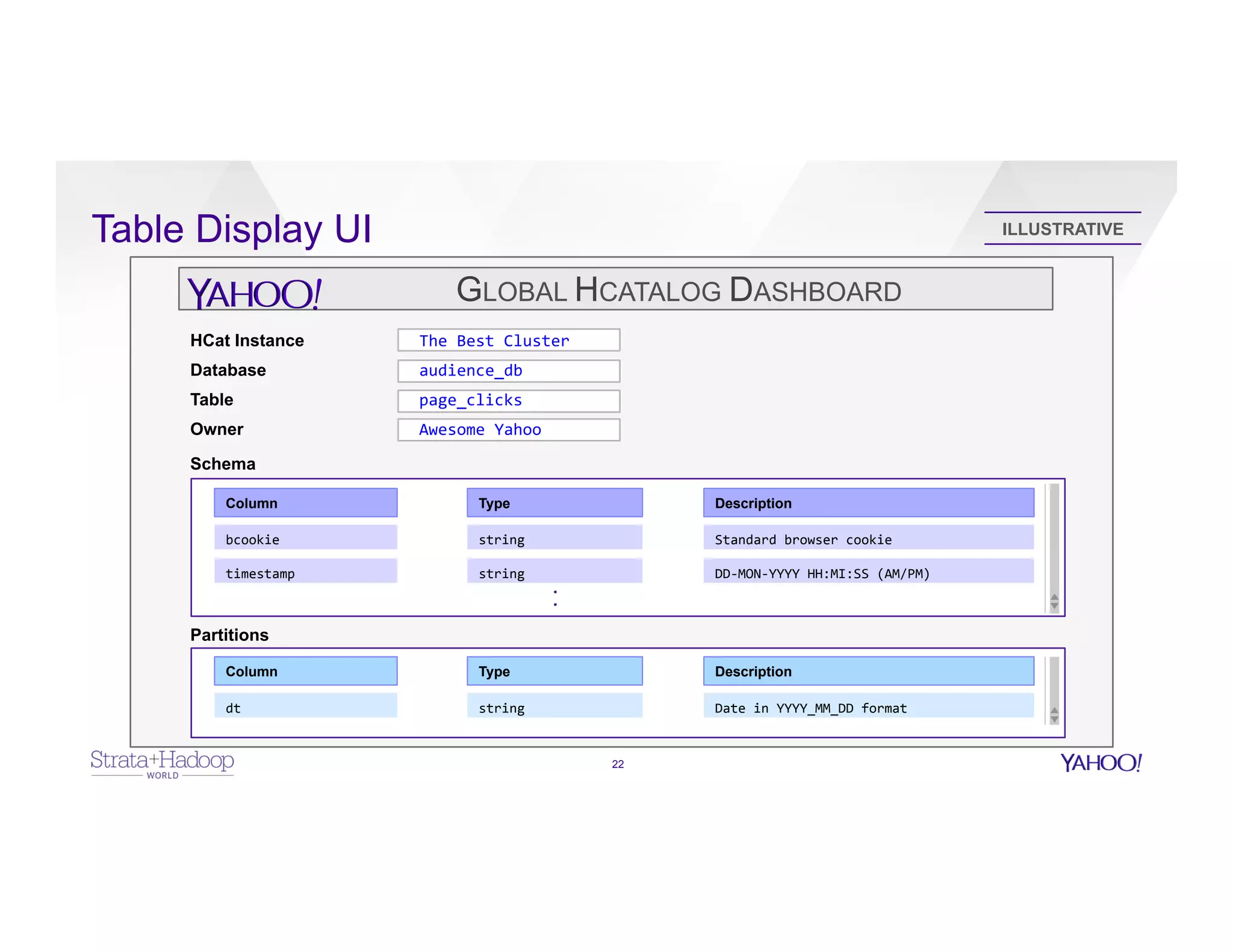
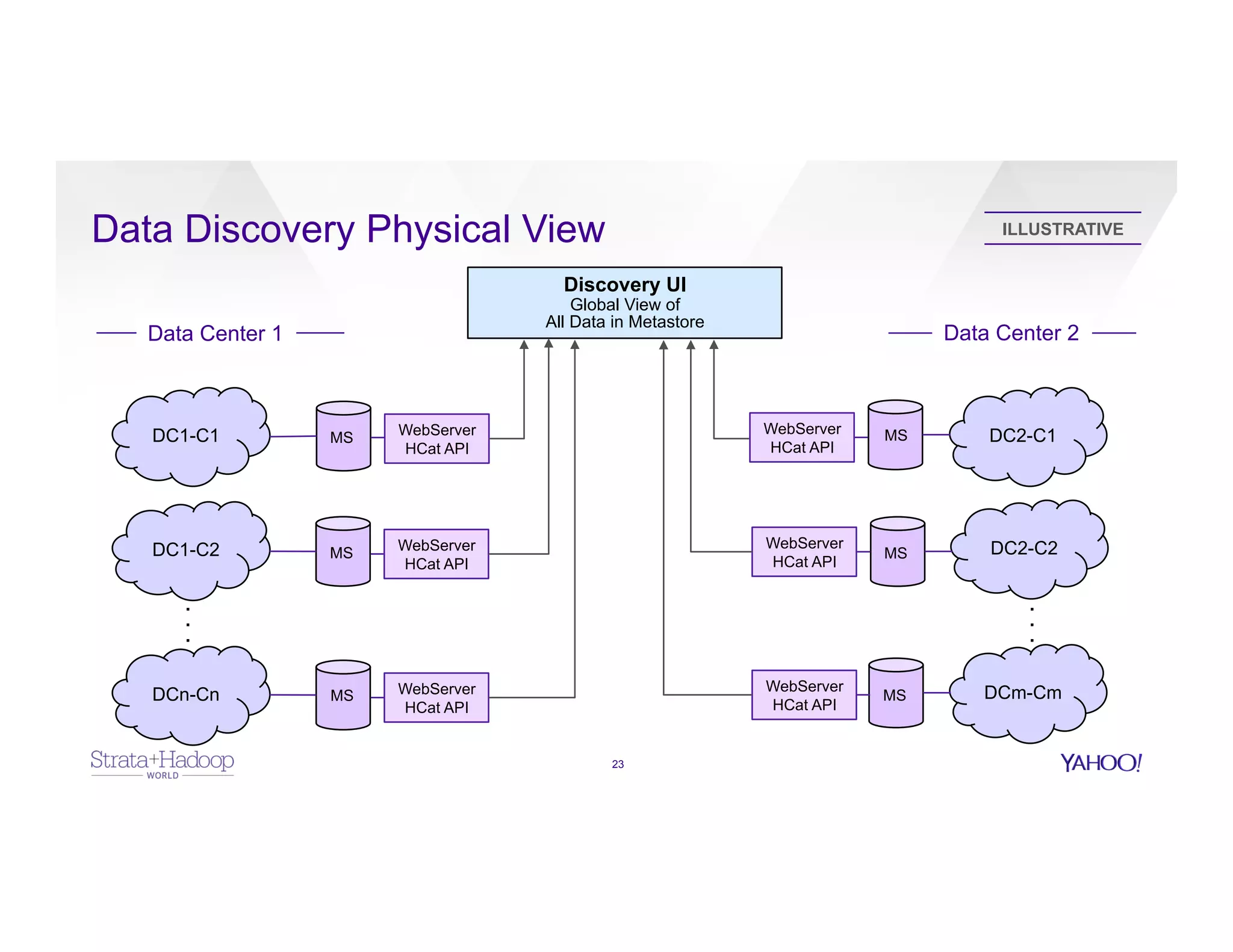



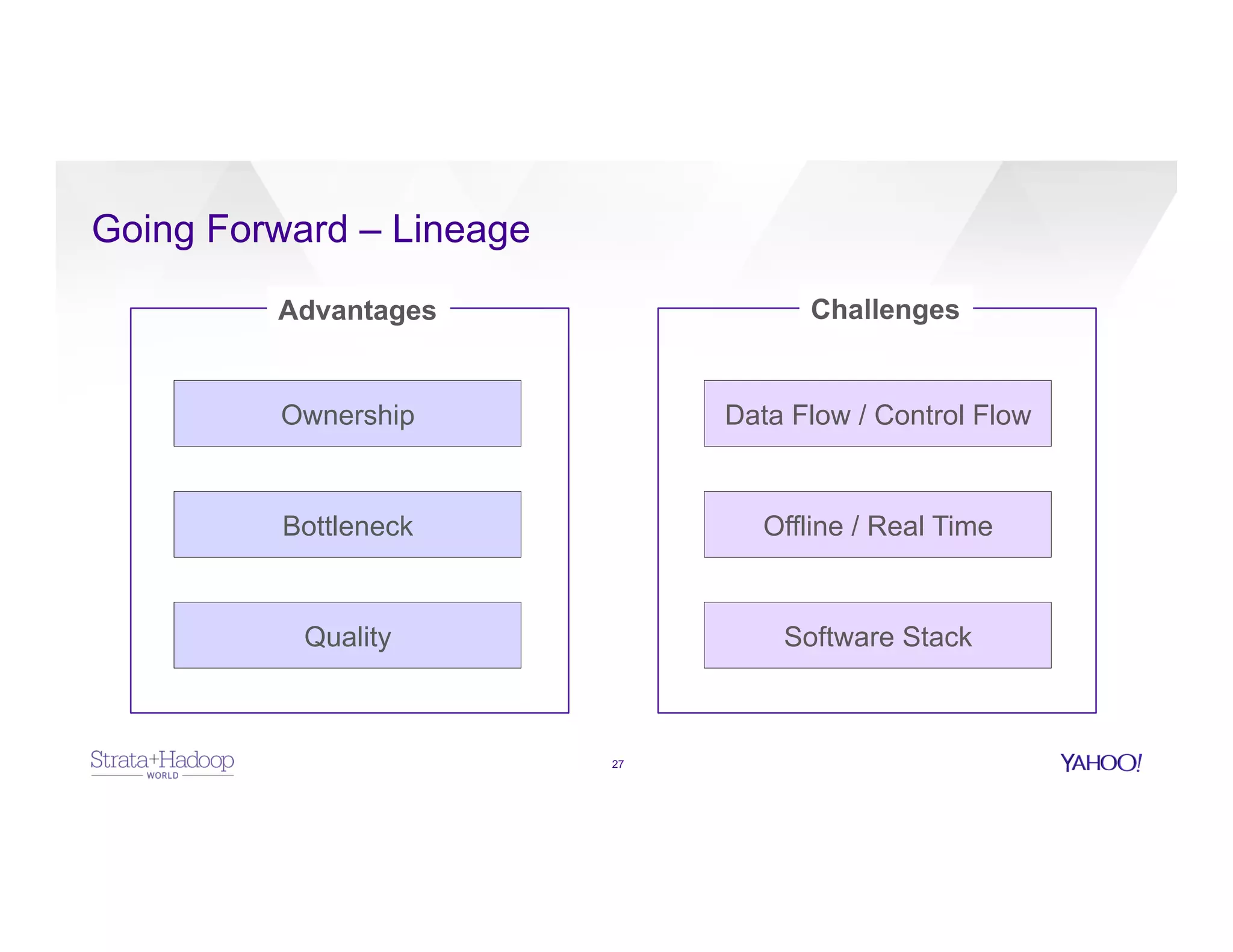



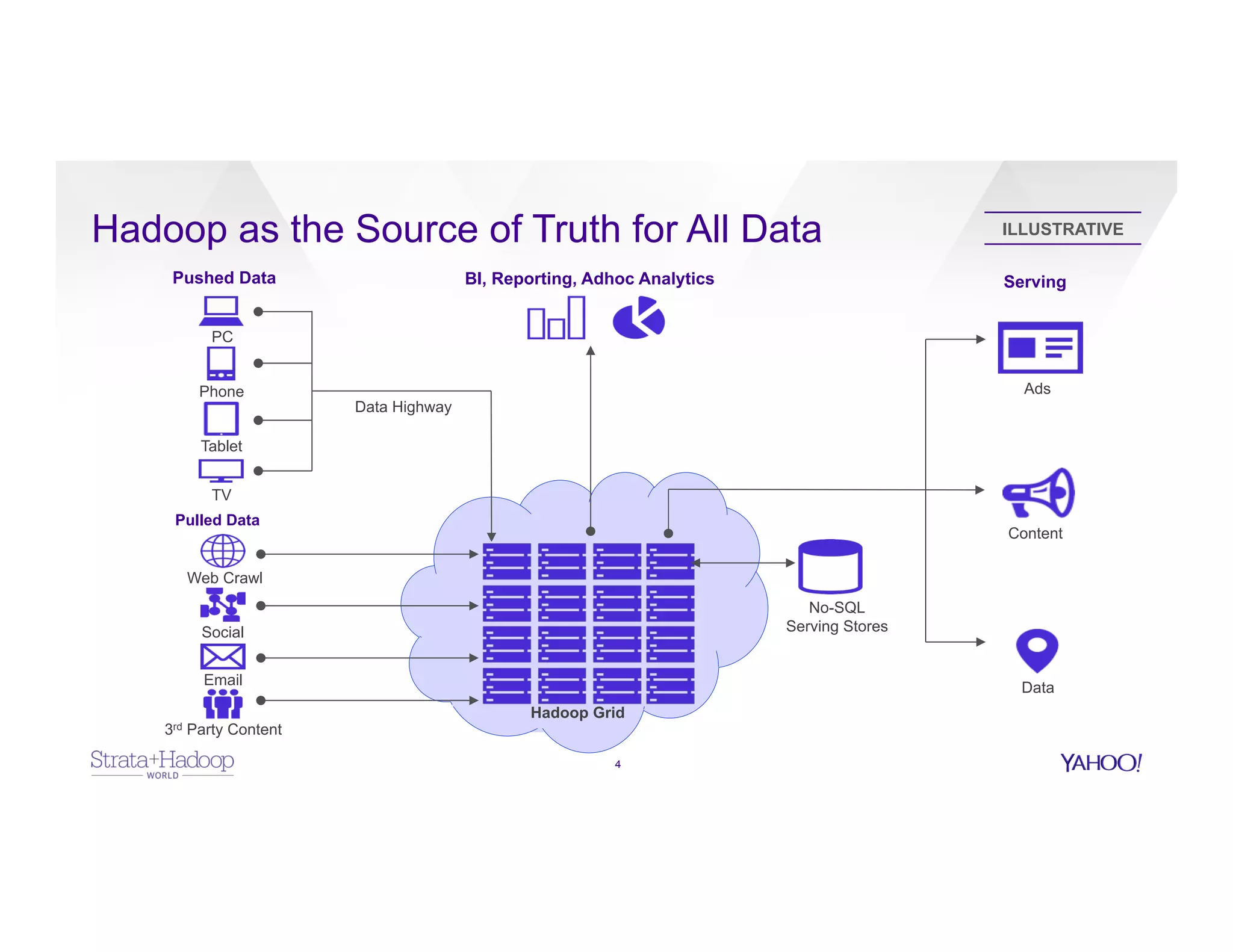
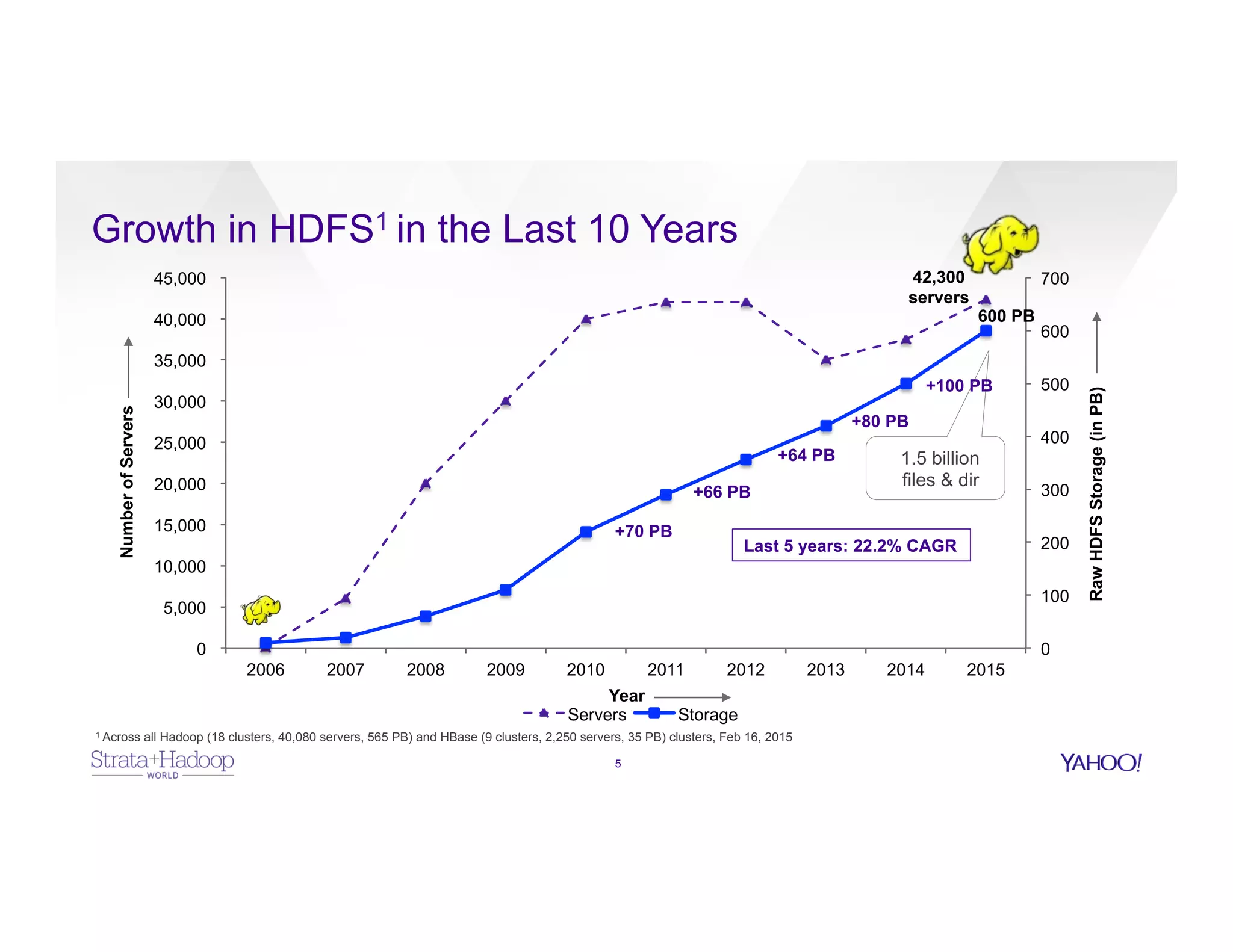
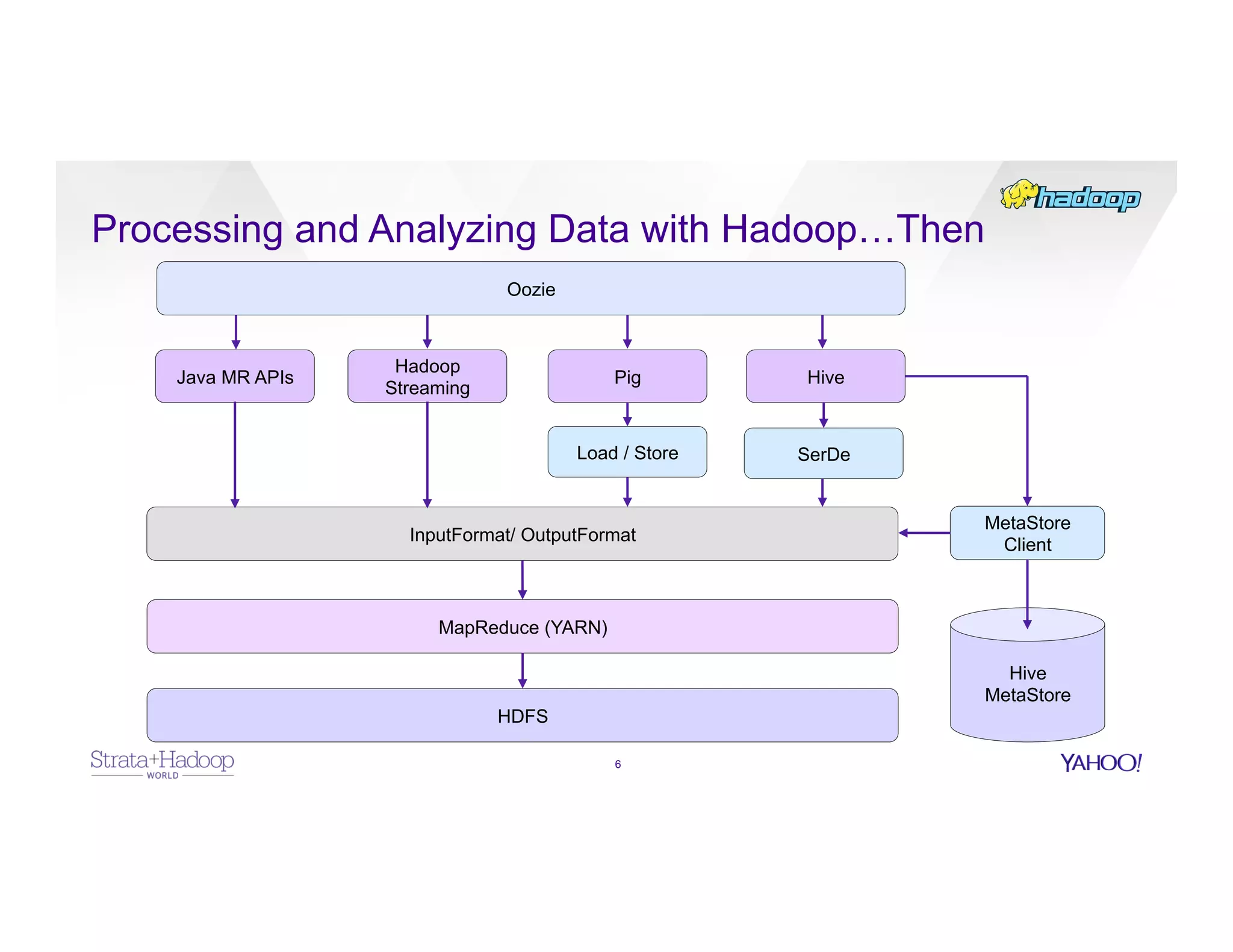
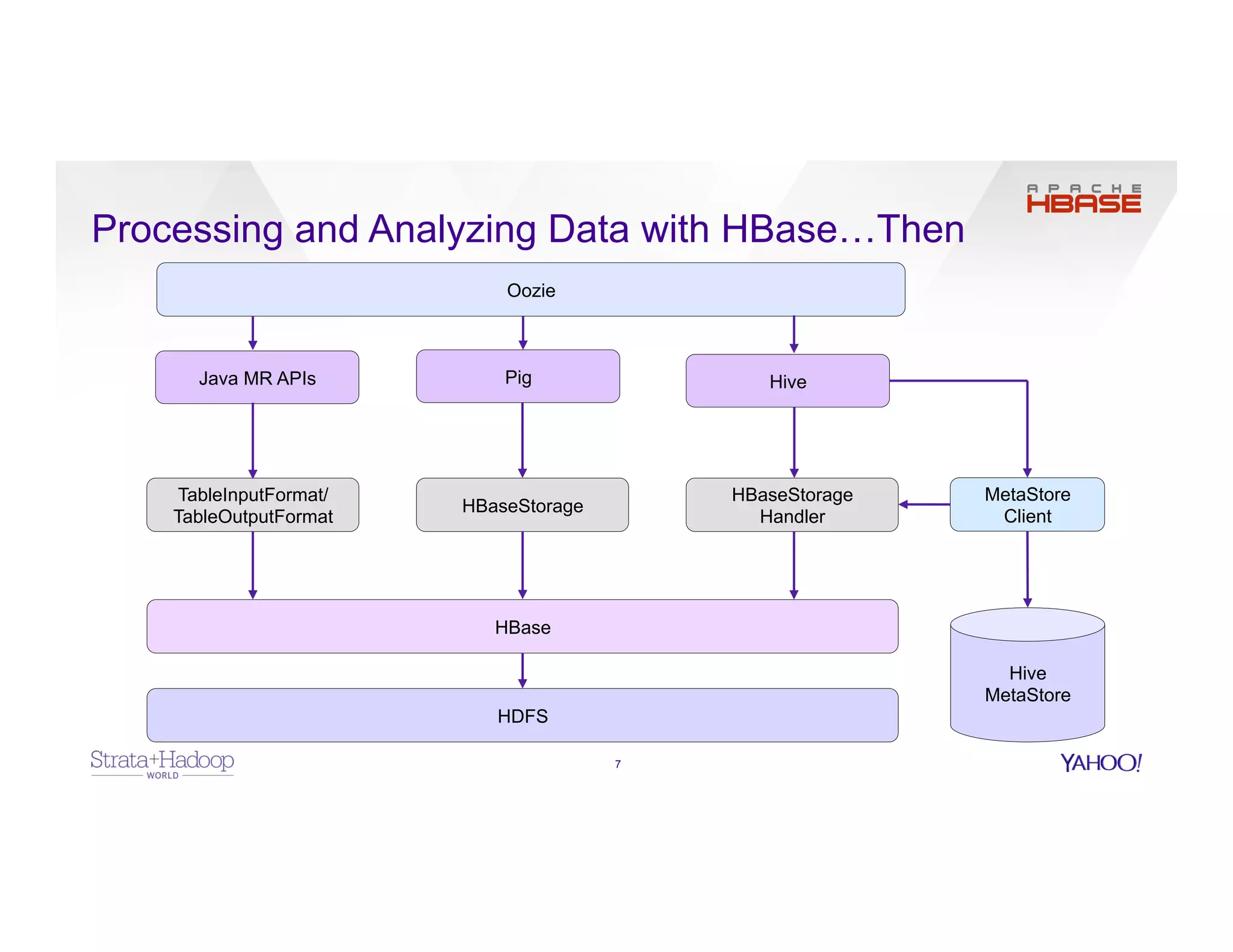
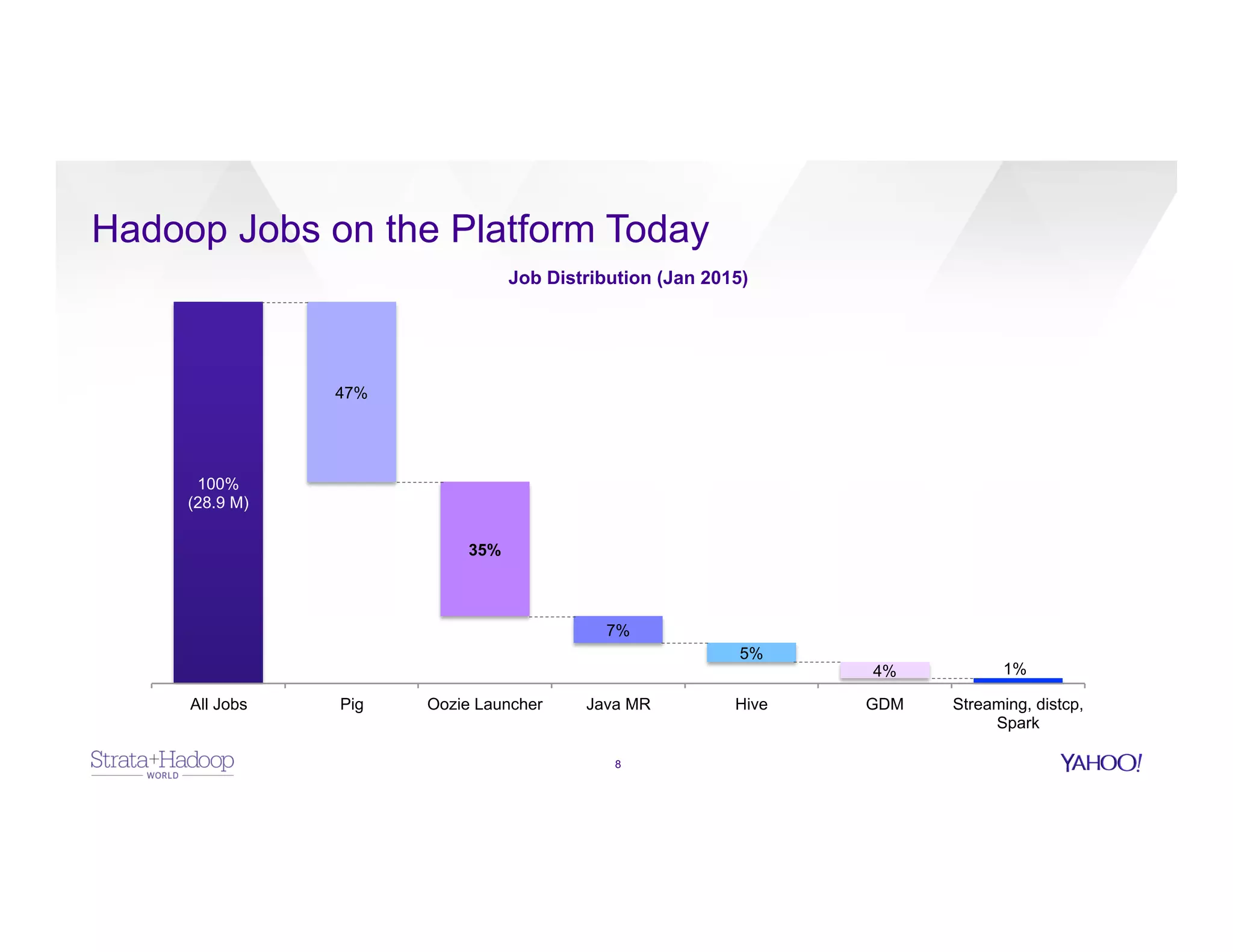
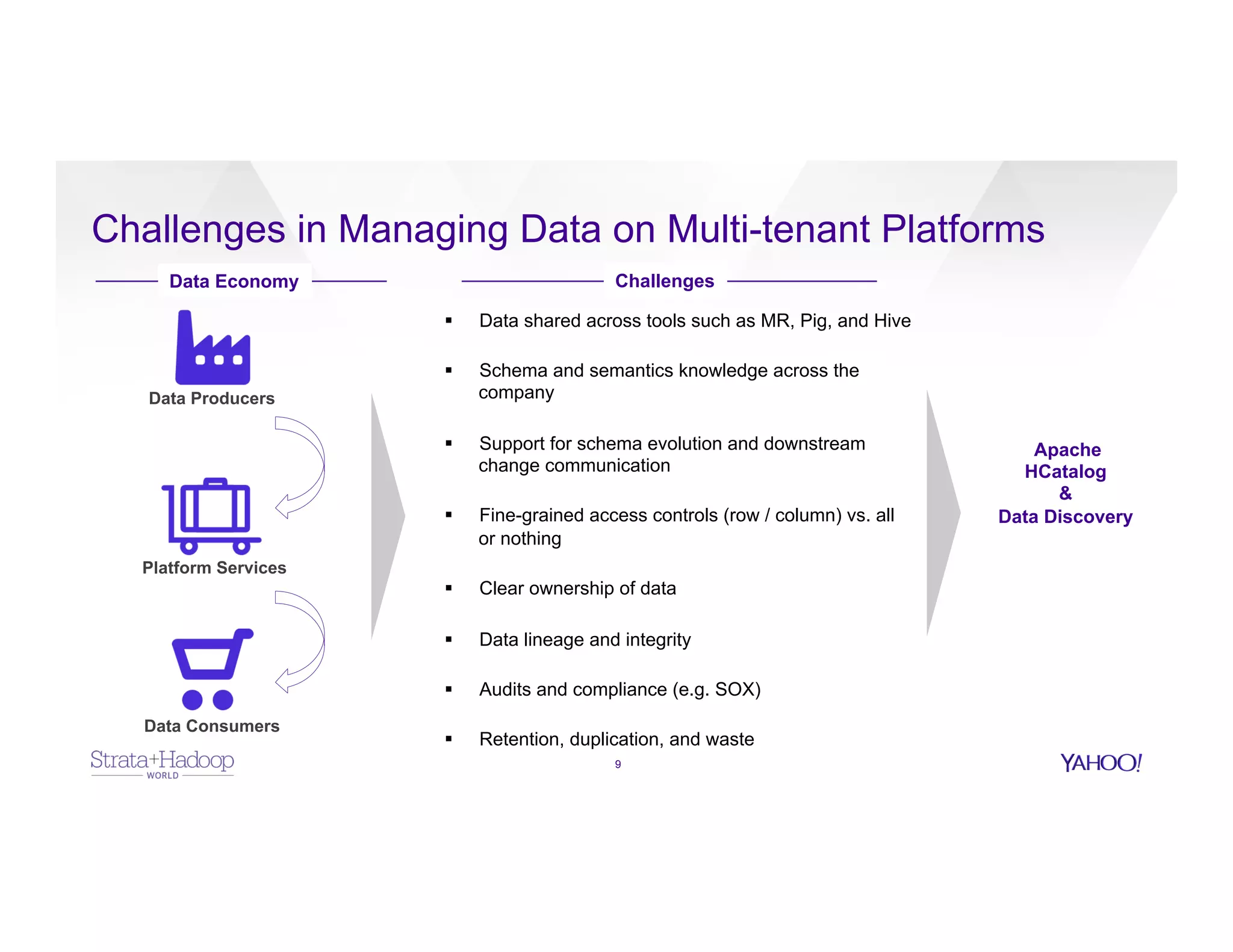
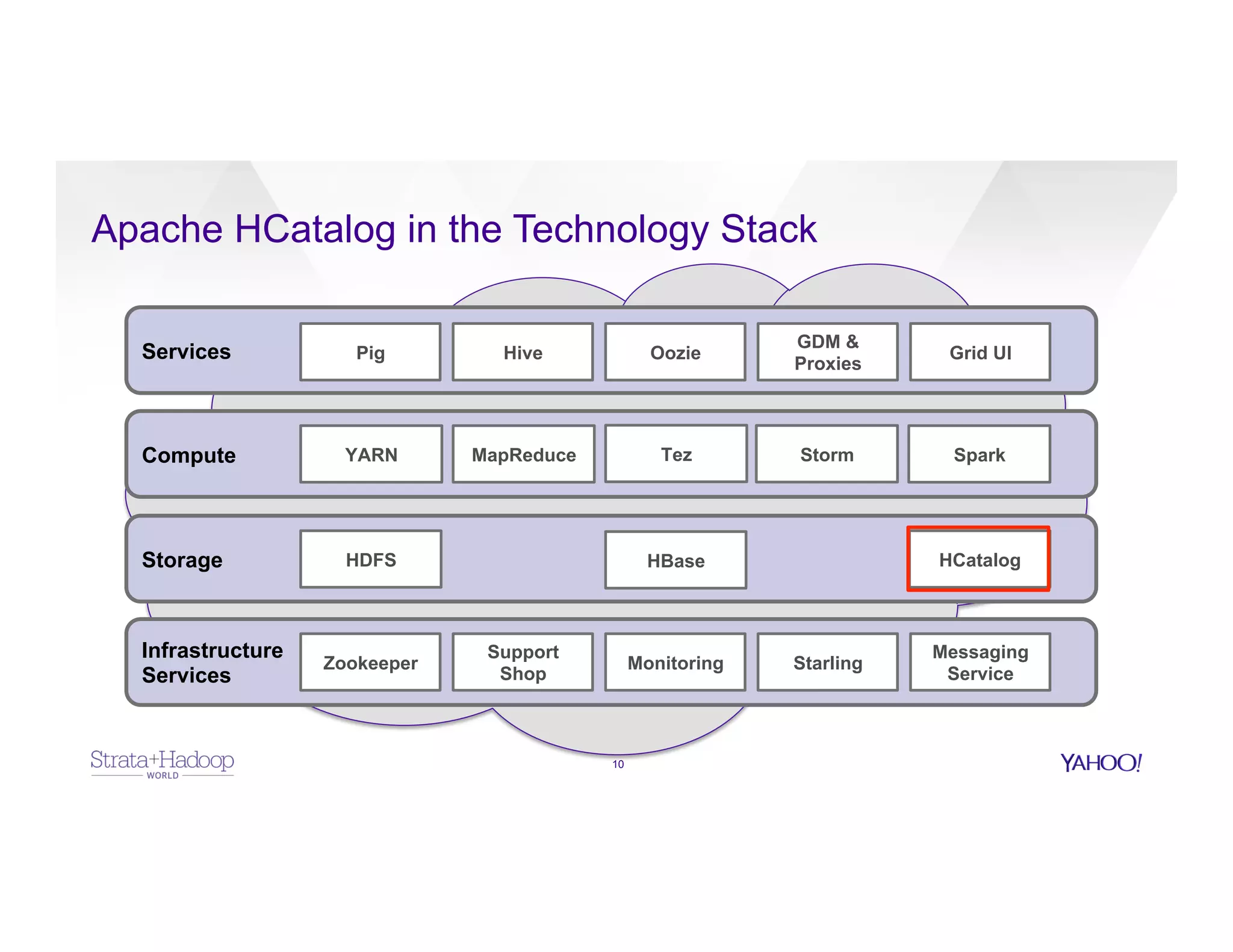
The document discusses data discovery using Apache HCatalog on Hadoop, highlighting the roles of Sumeet Singh and Thiruvel Thirumoolan at Yahoo in managing and analyzing large datasets. It addresses the challenges of data management across multi-tenant platforms, including schema evolution and access control, while proposing HCatalog as a solution for data registration and discovery. Key features of HCatalog are presented, including data management integration, notifications, and a unified metadata store to enhance data accessibility and integrity.

































































![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

