





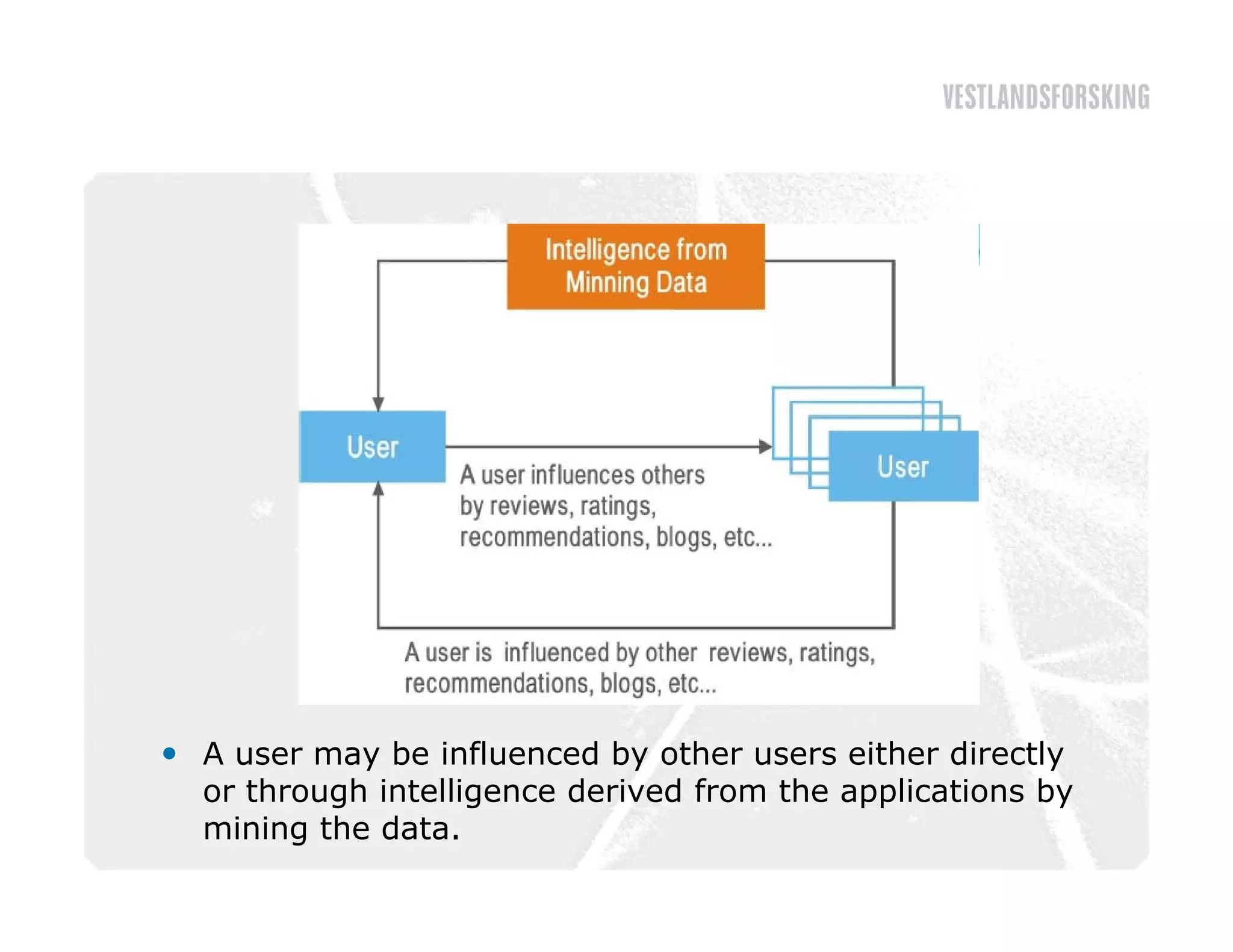


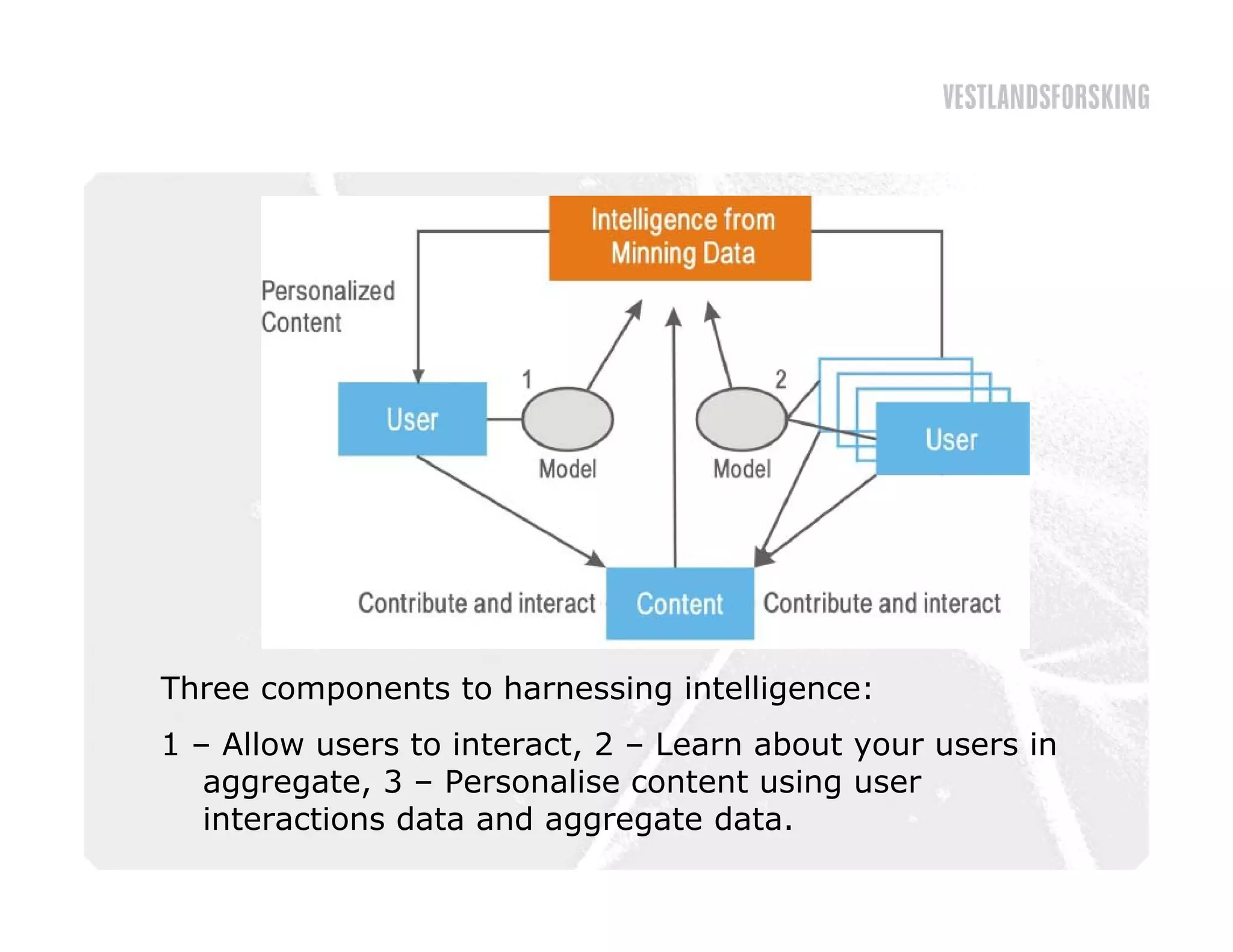


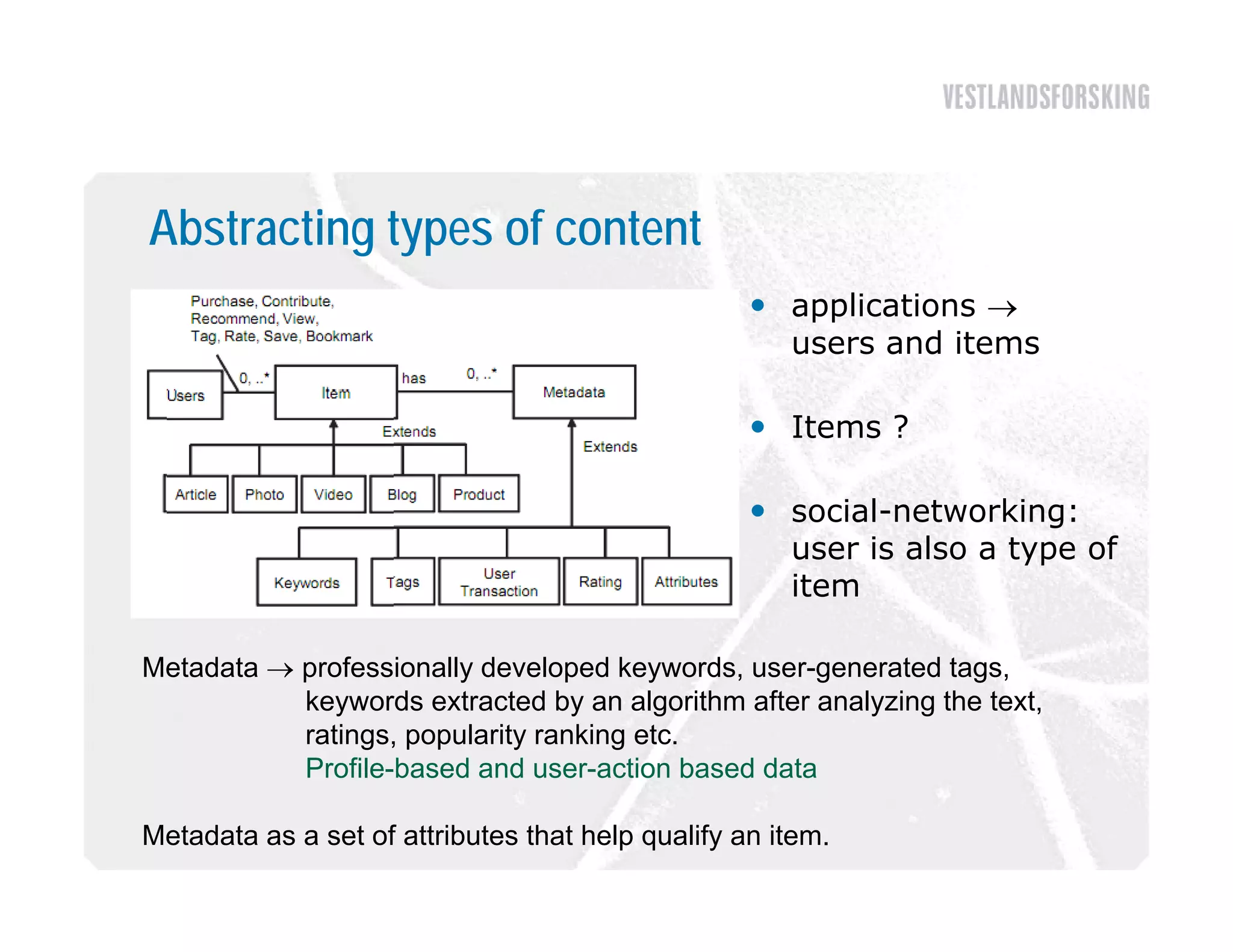

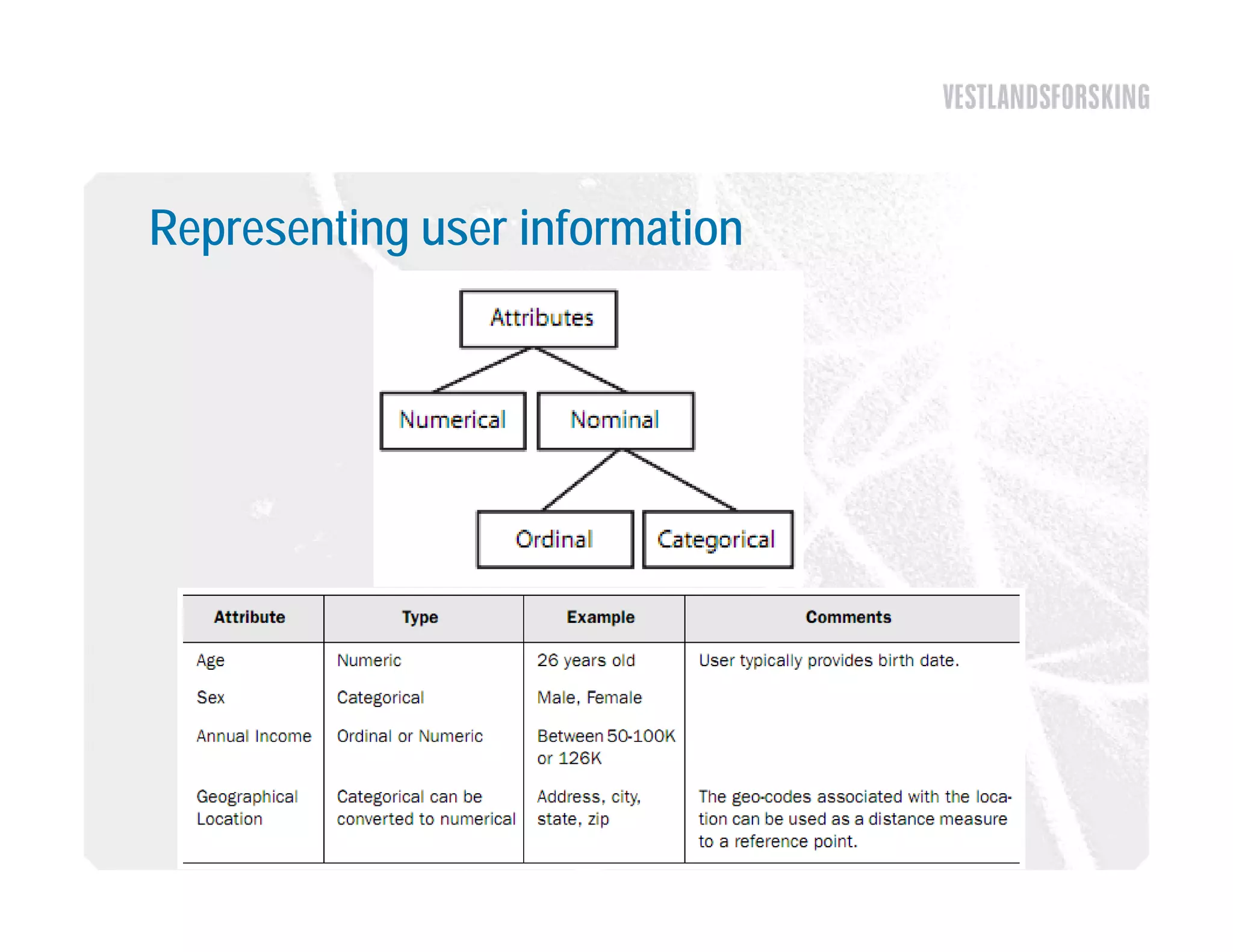




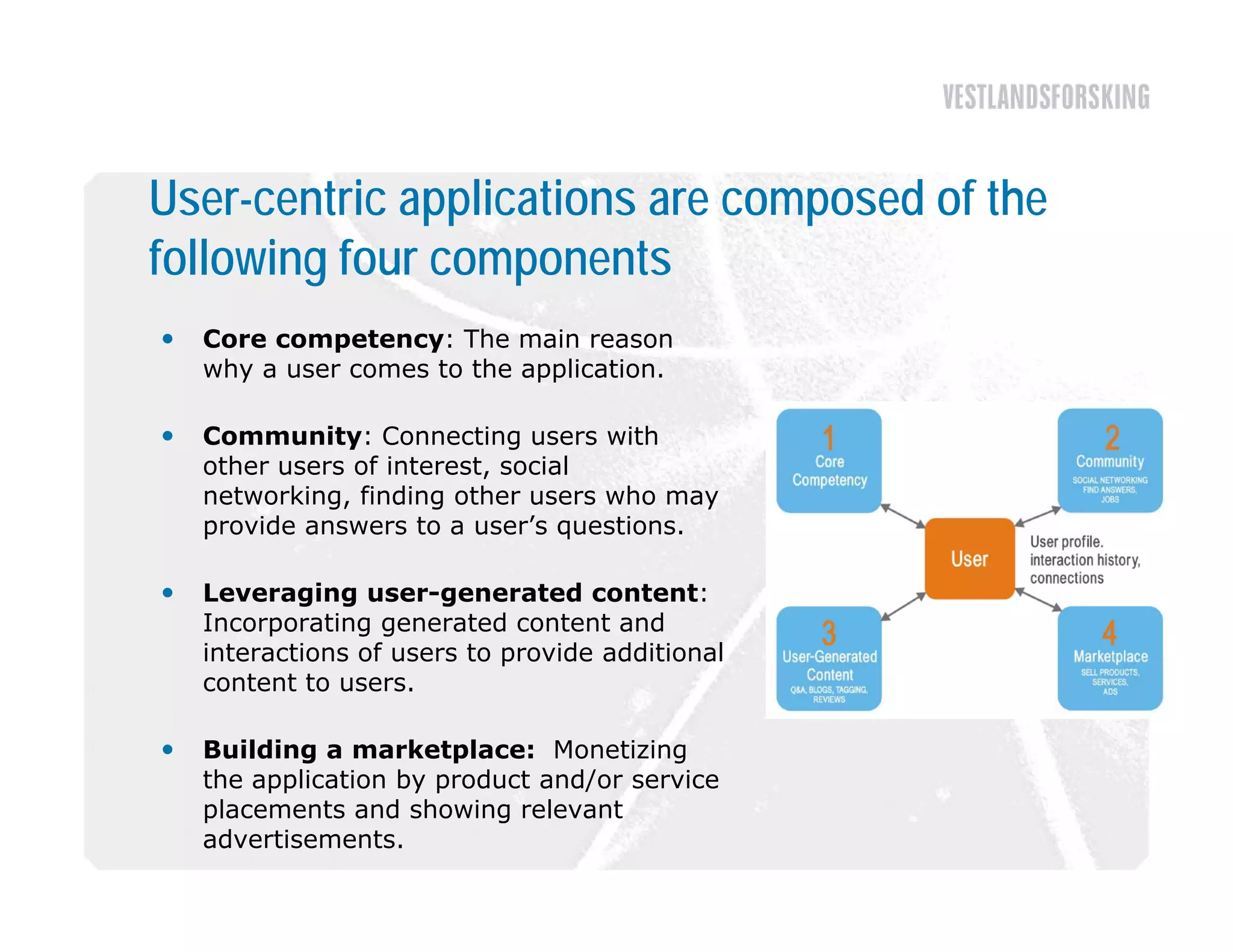
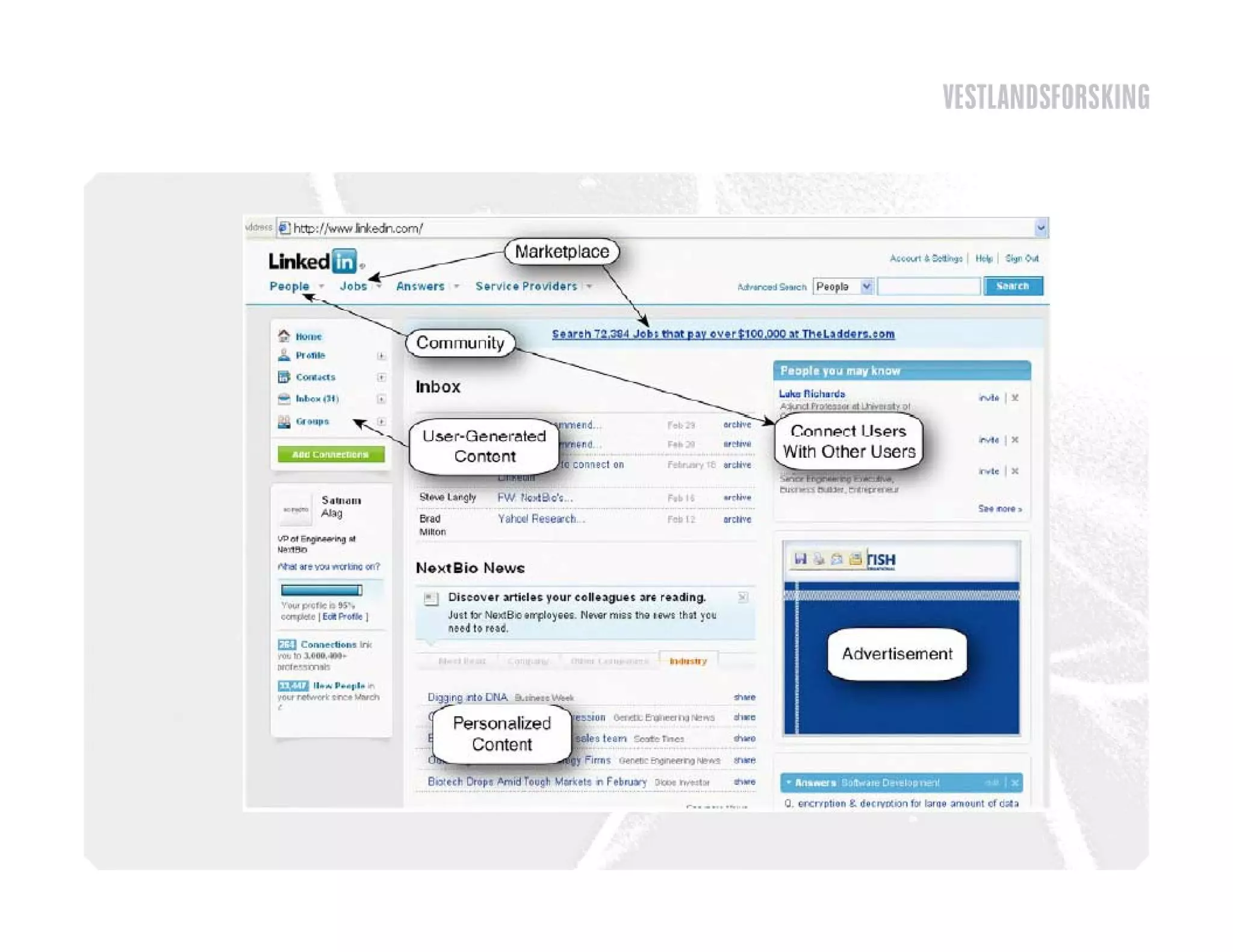
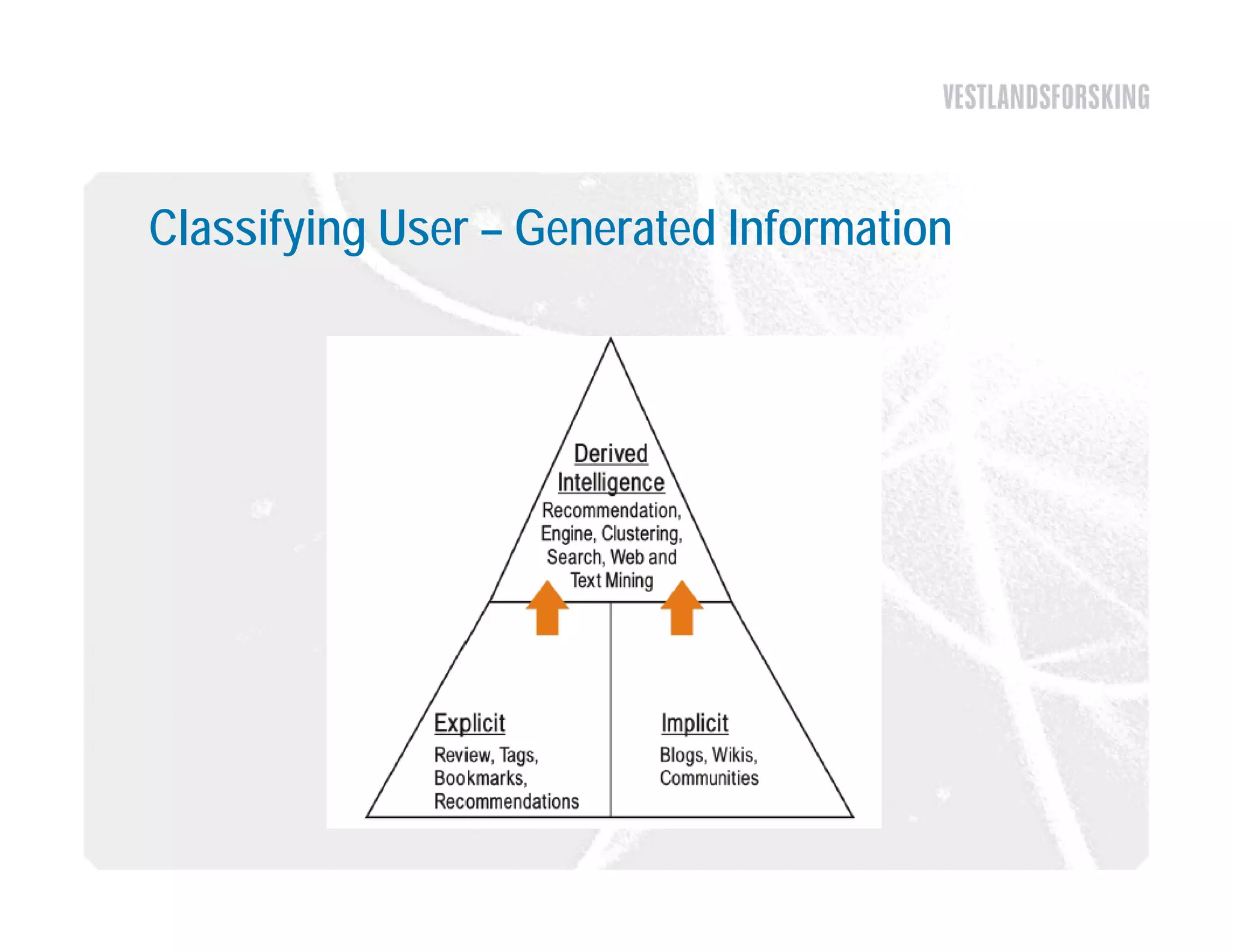


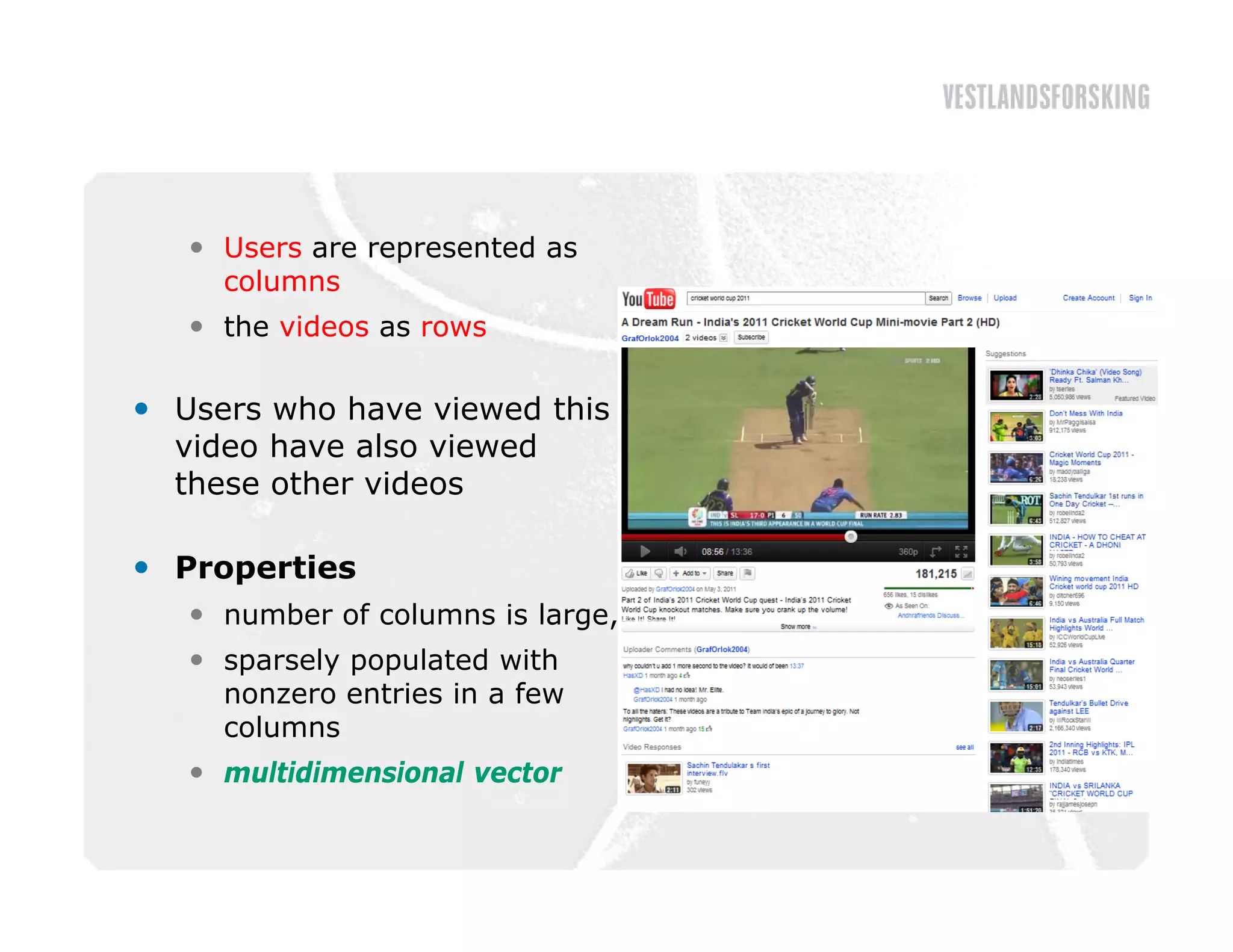



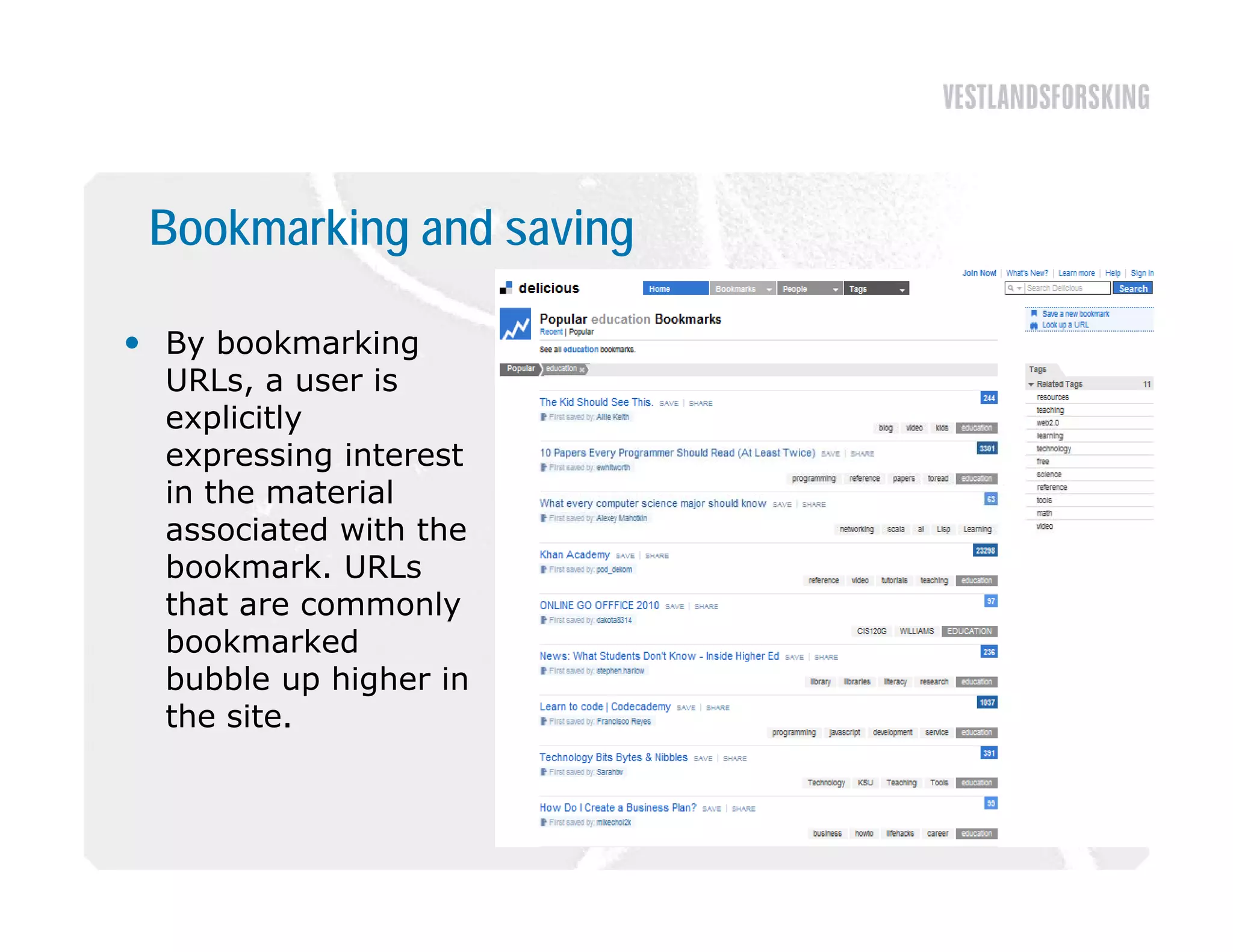
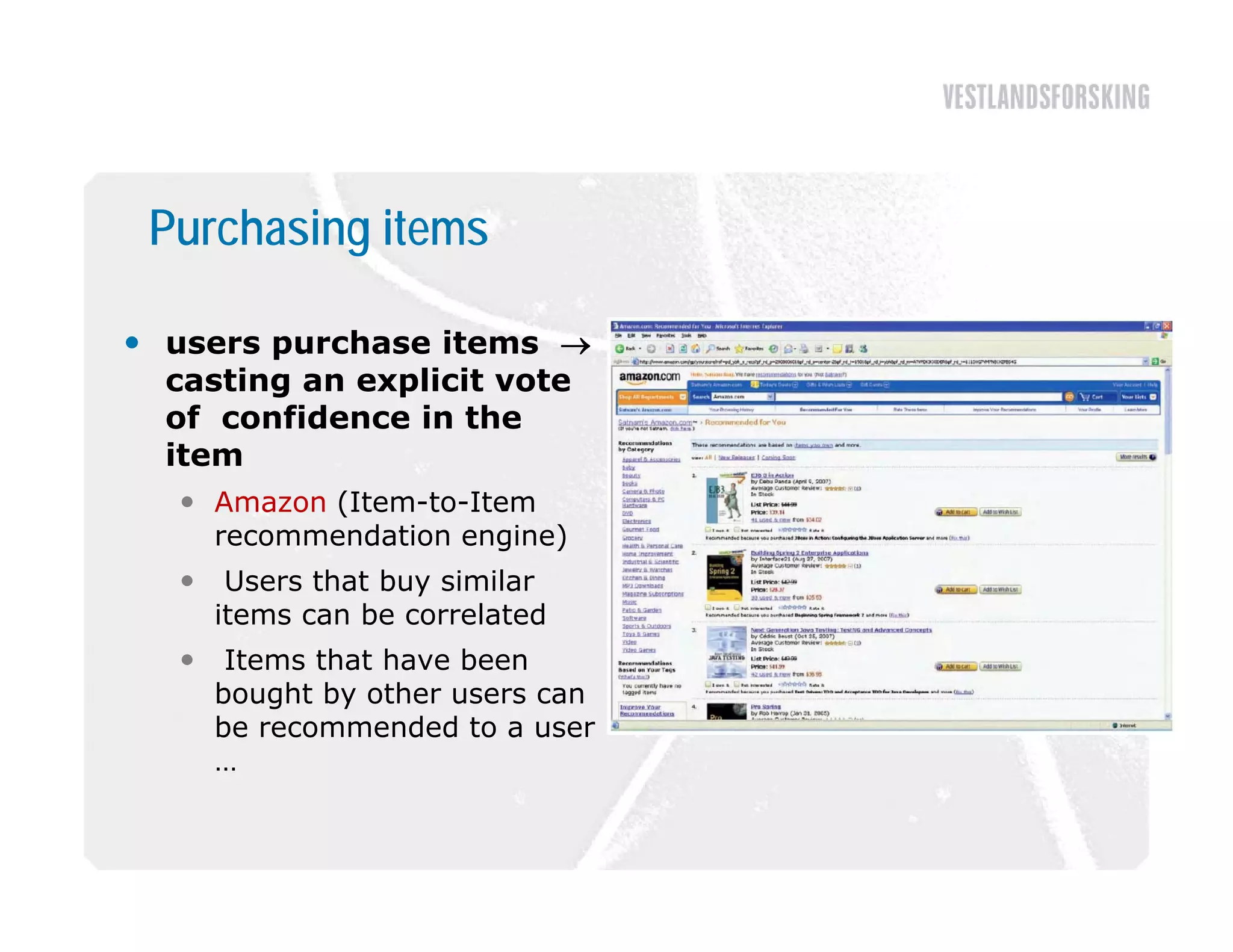
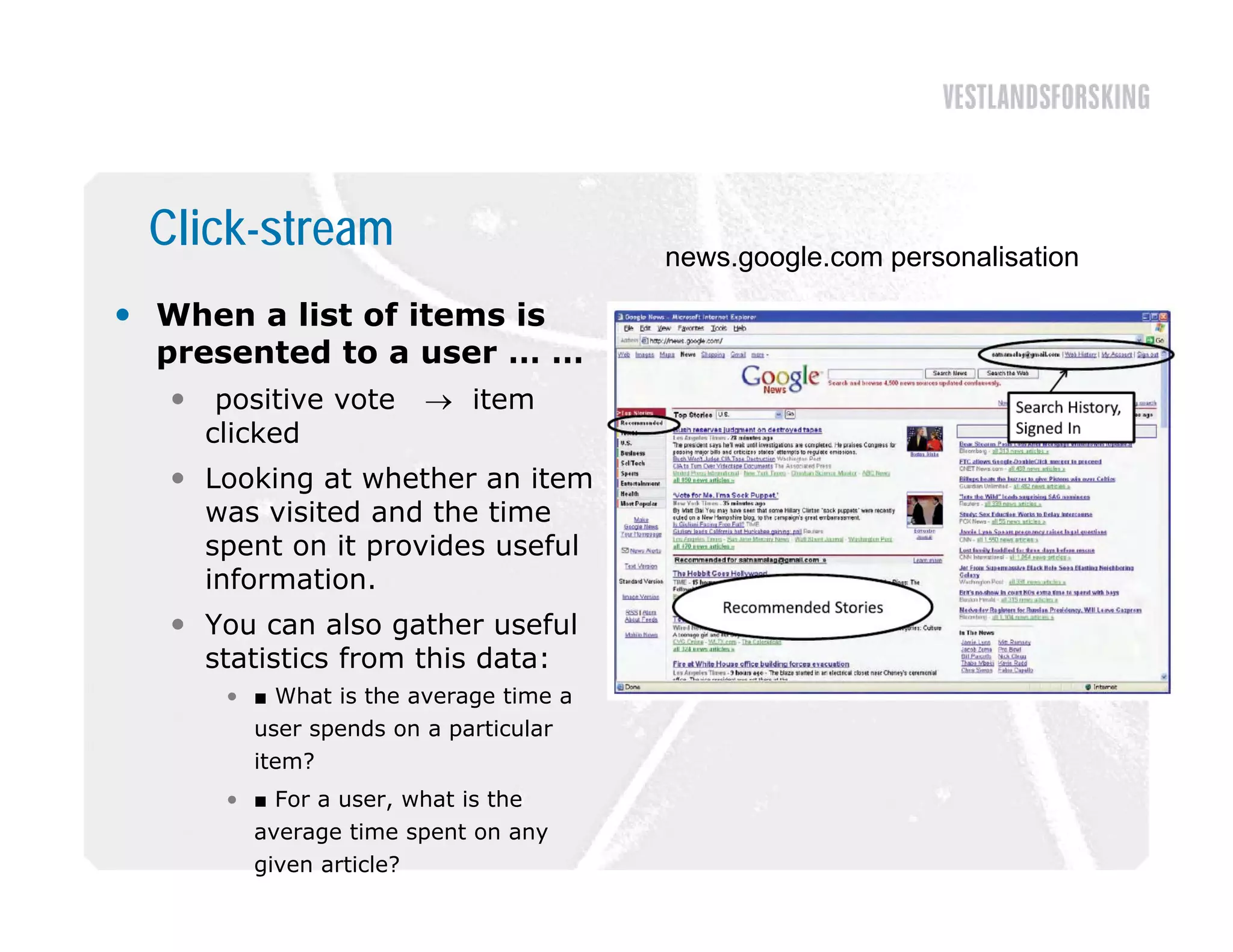
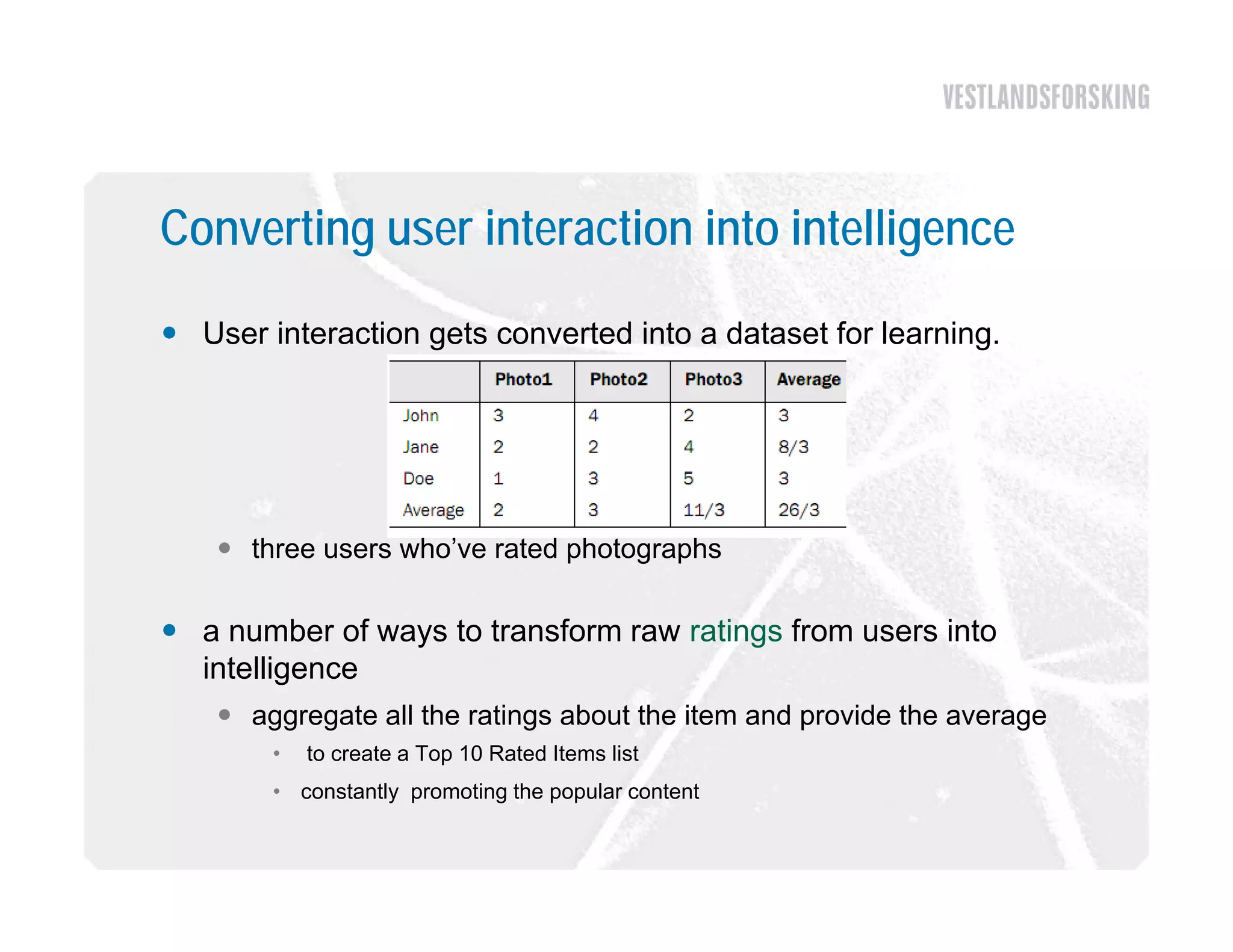


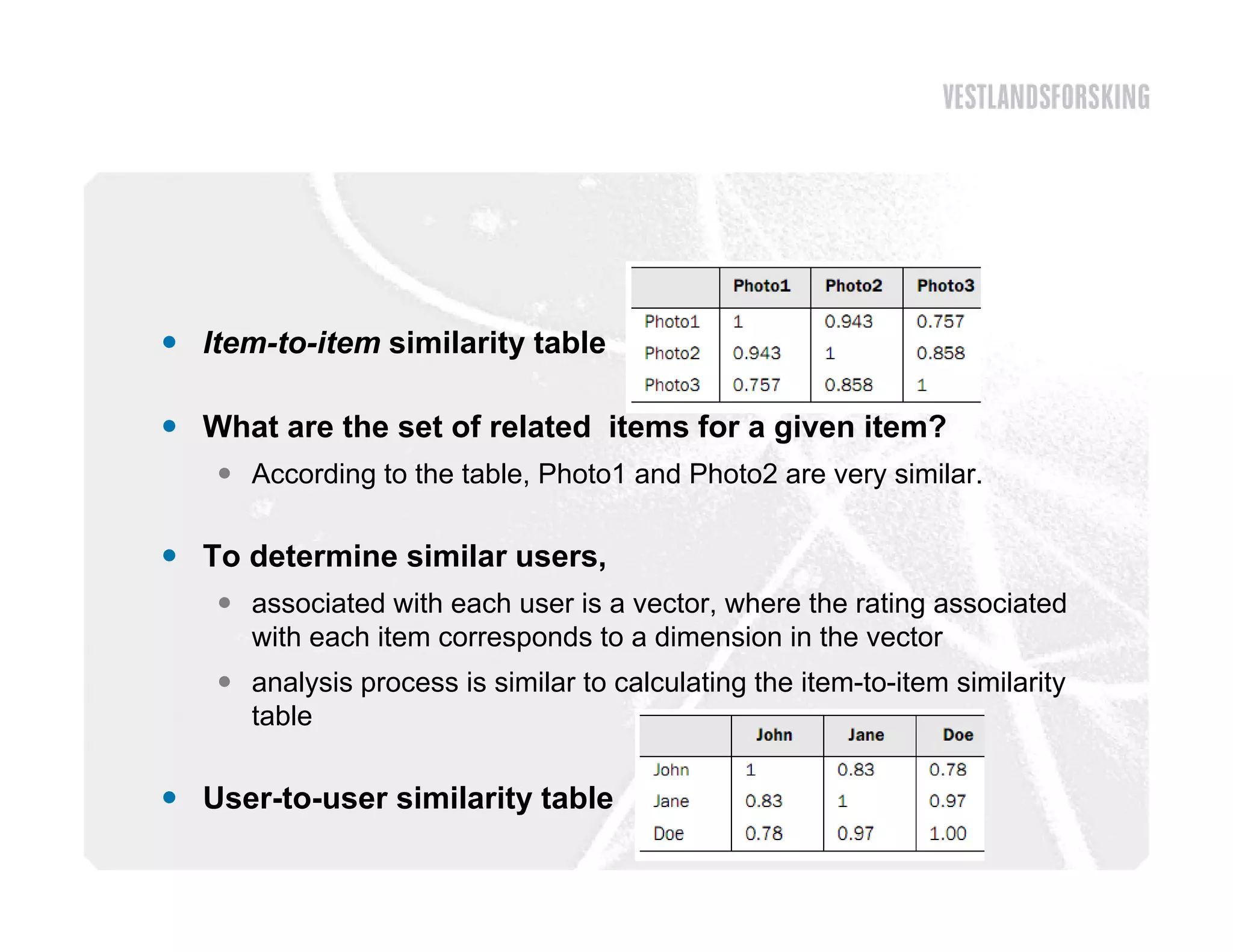

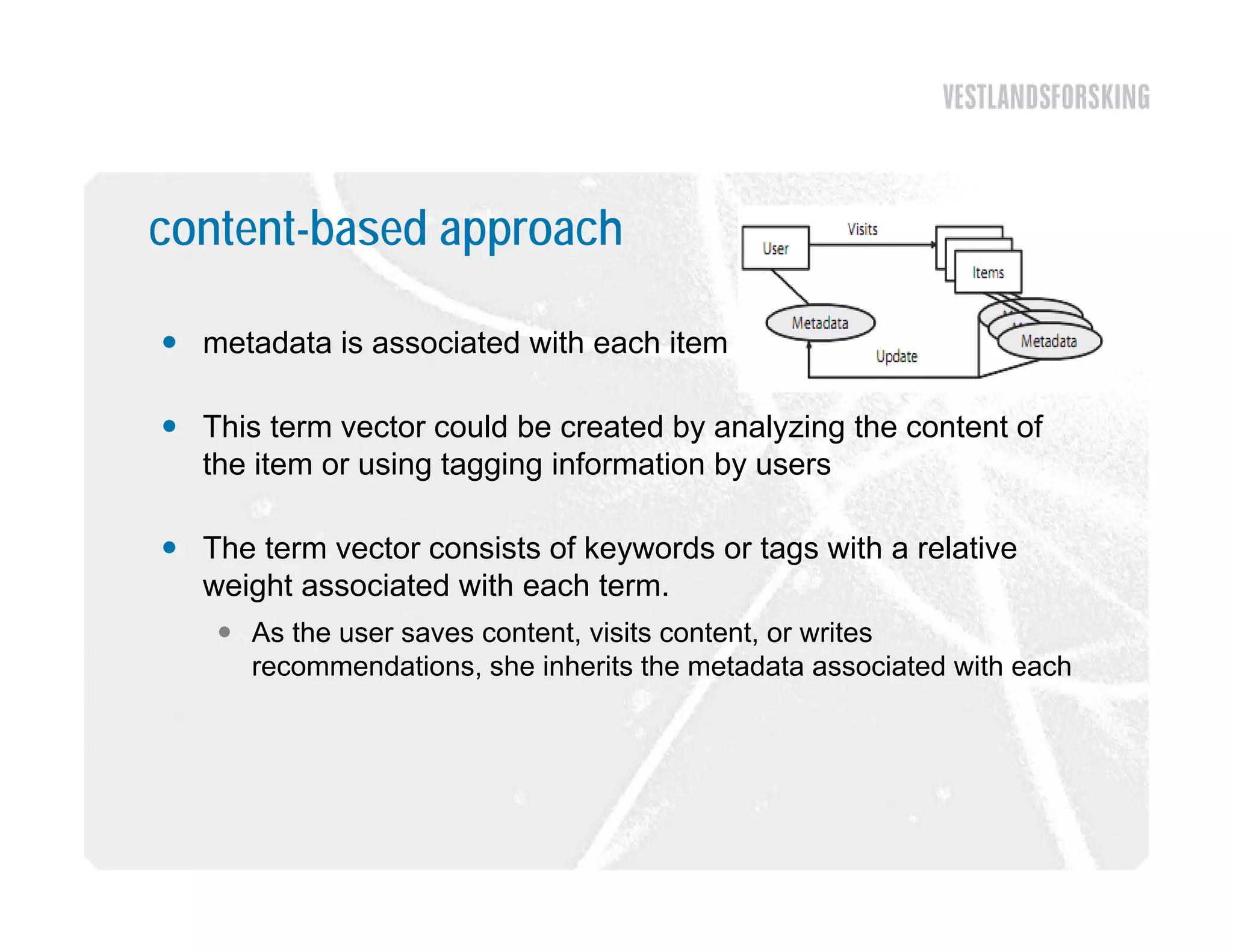
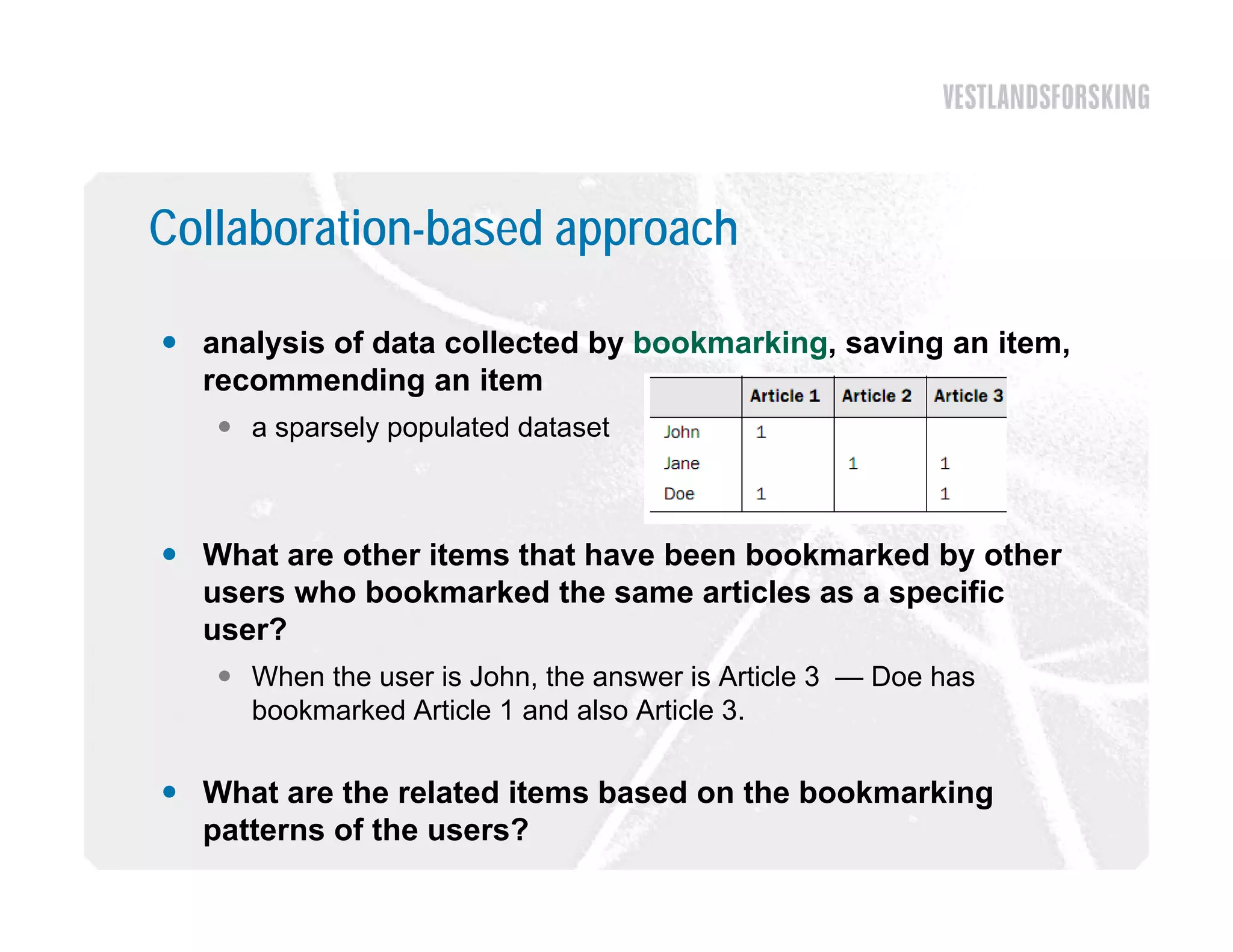






This document discusses how to harvest intelligence from user interactions on websites. It explains that as users share opinions, content, and participate in online communities, data is generated that can be converted into intelligence to personalize websites. It describes how collecting diverse opinions from many users can lead to "wise crowds" and collective intelligence. The key is to allow user interactions, learn about users in aggregate, and personalize content using this data. Content and collaborative filtering are approaches to build user and item profiles to detect meaningful relationships and make recommendations. The goal is to transform applications from being content-centric to being user-centric using collective intelligence.

































































































