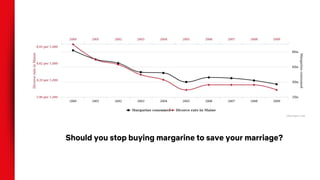
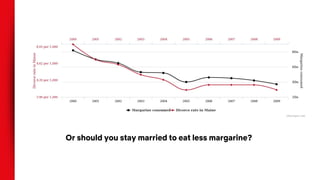
This document discusses causal inference techniques for machine learning, including:
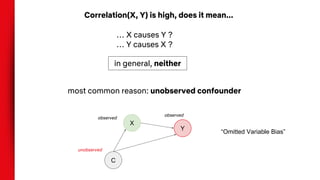
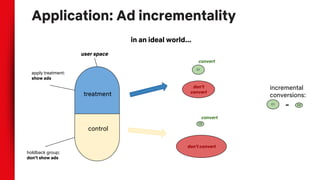
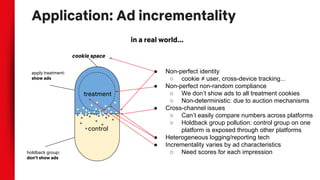
- Correlation does not imply causation, and observational data can be biased by confounding variables. Randomization and counterfactual modeling are introduced as alternatives.
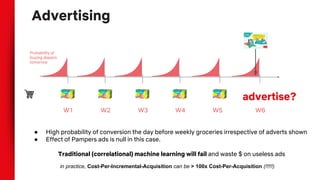
- Inverse propensity scoring is presented as a method for estimating treatment effects from observational data by reweighting samples based on their propensity to receive treatment.
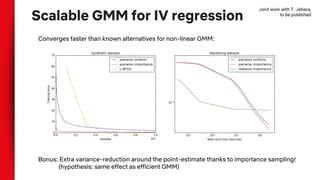
- Instrumental variable regression is discussed as another technique, using variables that influence the treatment but not the outcome except through treatment. Scalable methods for instrumental variable regression on large datasets are proposed.
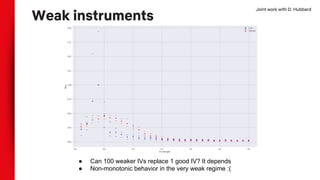
- Challenges with weak instruments are noted, as instrumental variable estimates can become more biased than purely correlational models when instruments are weak