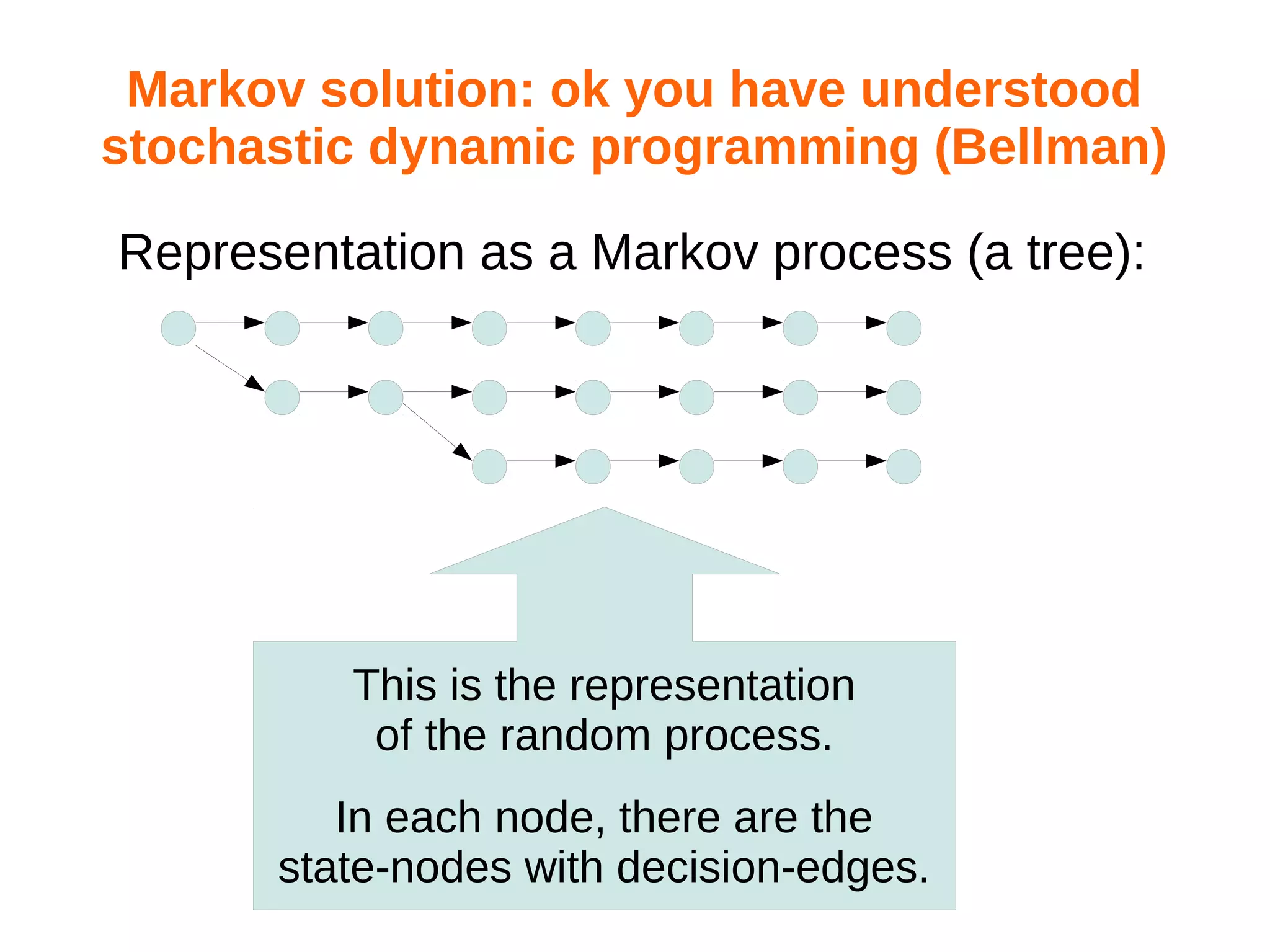
Download to read offline



















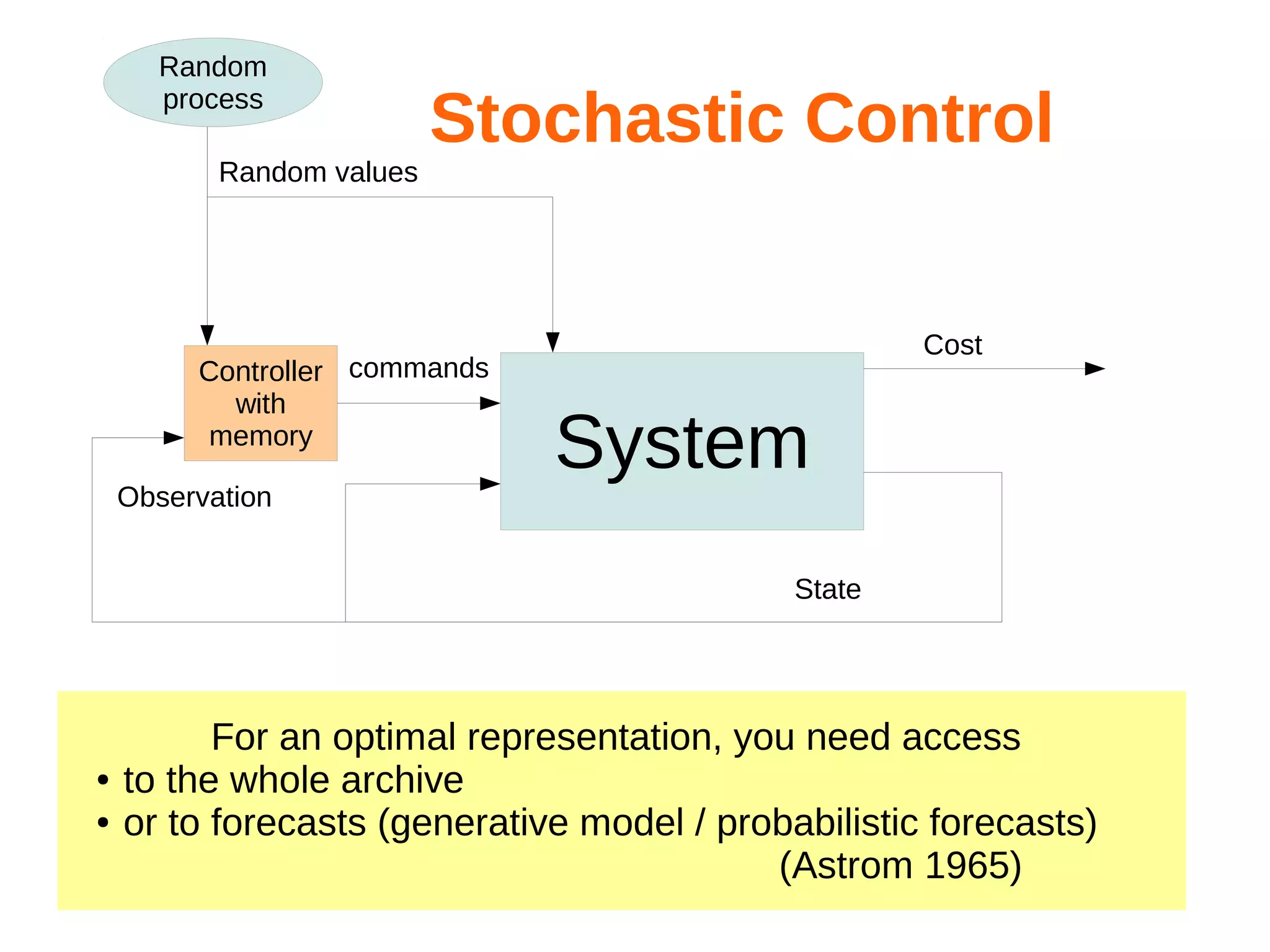






















![Random
process
Random values
Stochastic Control
Controller commands
with
memory
State
Cost
System
State
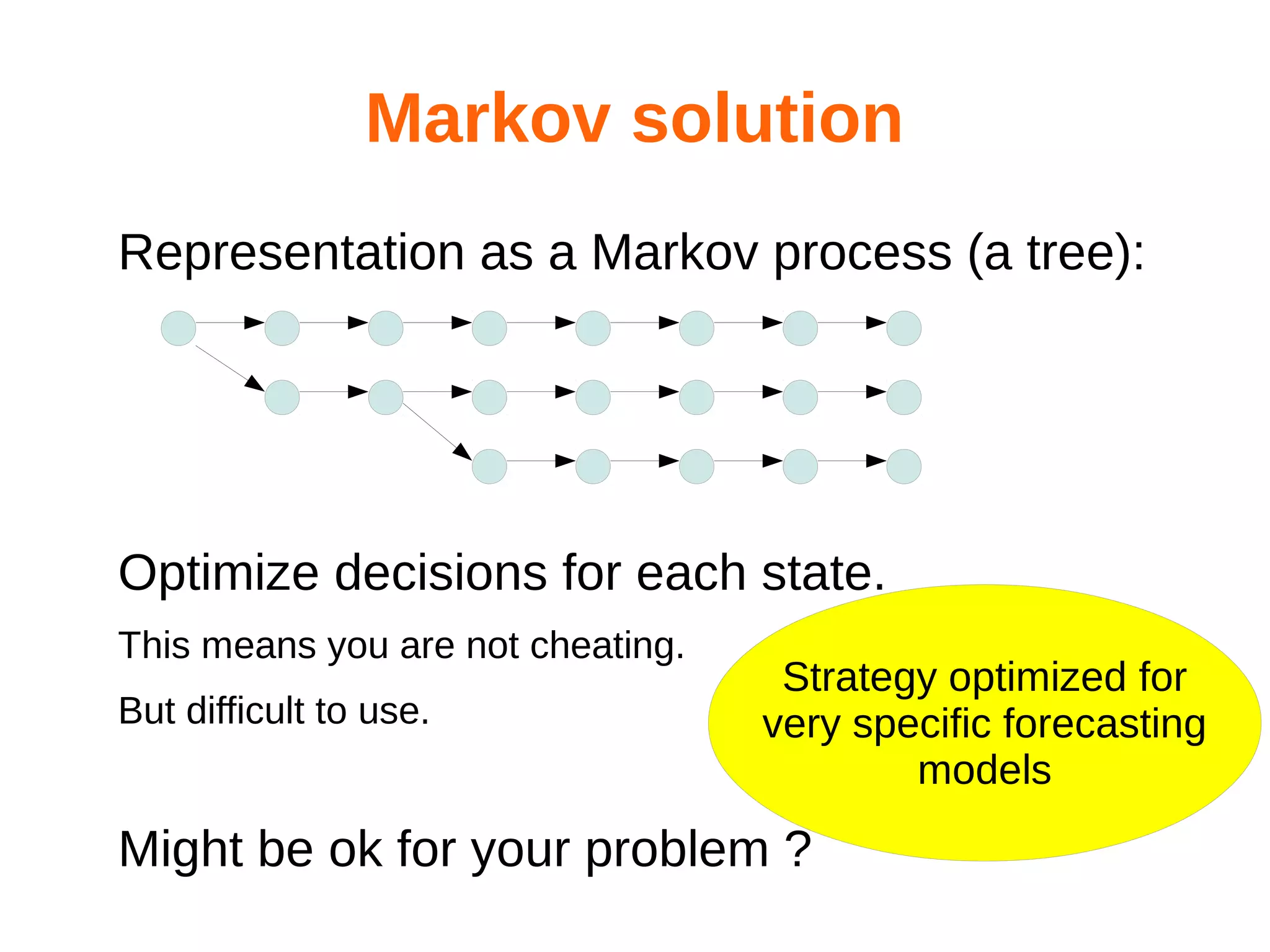
Optimize the controller thanks to a simulator:
●
●
●
Command = Controller(w,state,forecasts)
Simulate( w ) = stochastic loss with parameter w
w* = argmin [Simulate(w)]](https://image.slidesharecdn.com/hualien2013-131208210046-phpapp02/75/Optimization-of-power-systems-old-and-new-tools-53-2048.jpg)
![Random
process
Random values
Stochastic Control
Controller commands
with
memory
State
●
●
●
Cost
System
Ok,
State
we have done the 3rd
of the four targets:
Optimize the controller thanks to a simulator:
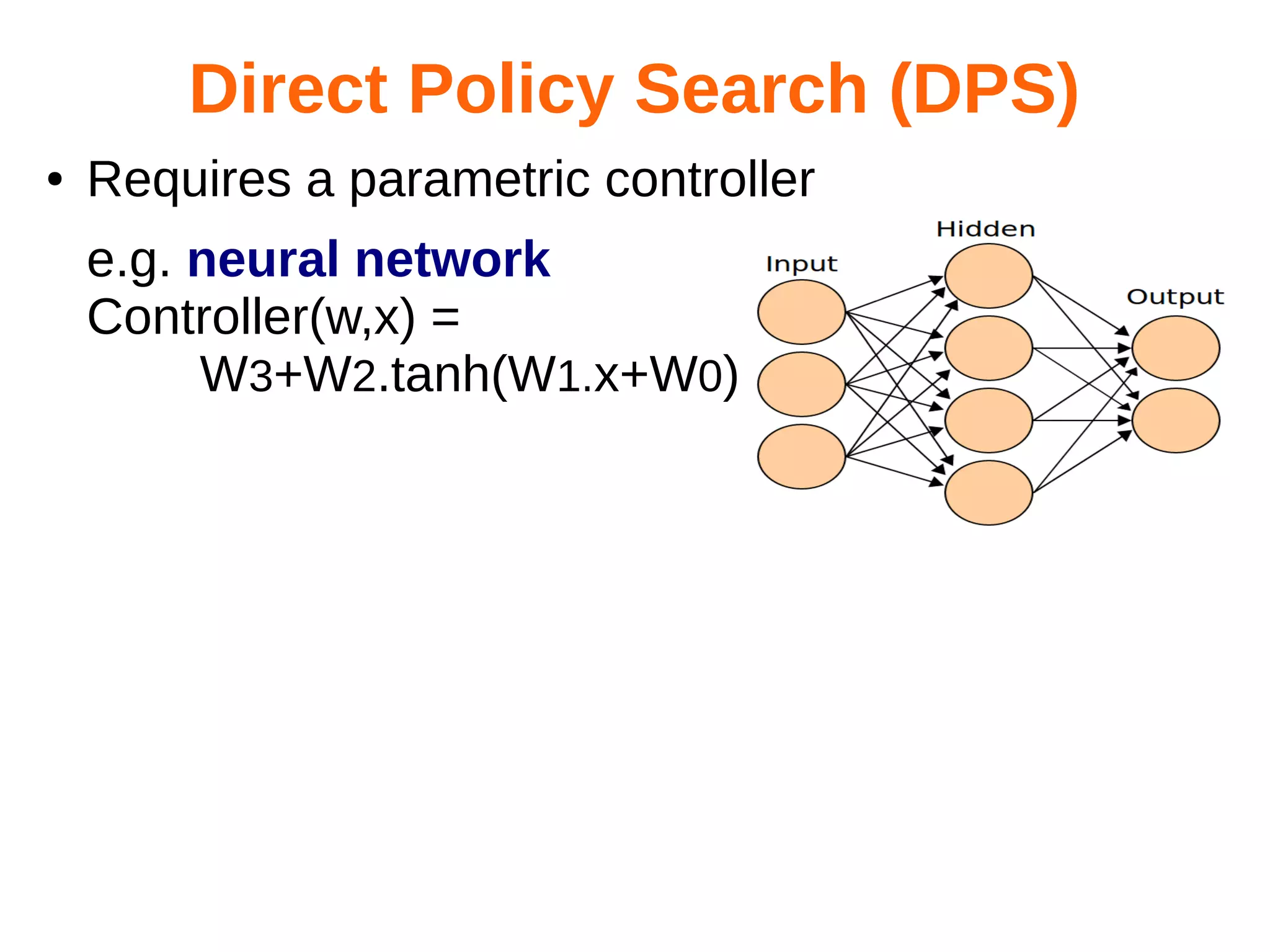
Direct policy search.
Command = Controller(w,state,forecasts)
Simulate( w ) = stochastic loss with parameter w
w* = argmin [Simulate(w)]](https://image.slidesharecdn.com/hualien2013-131208210046-phpapp02/75/Optimization-of-power-systems-old-and-new-tools-54-2048.jpg)

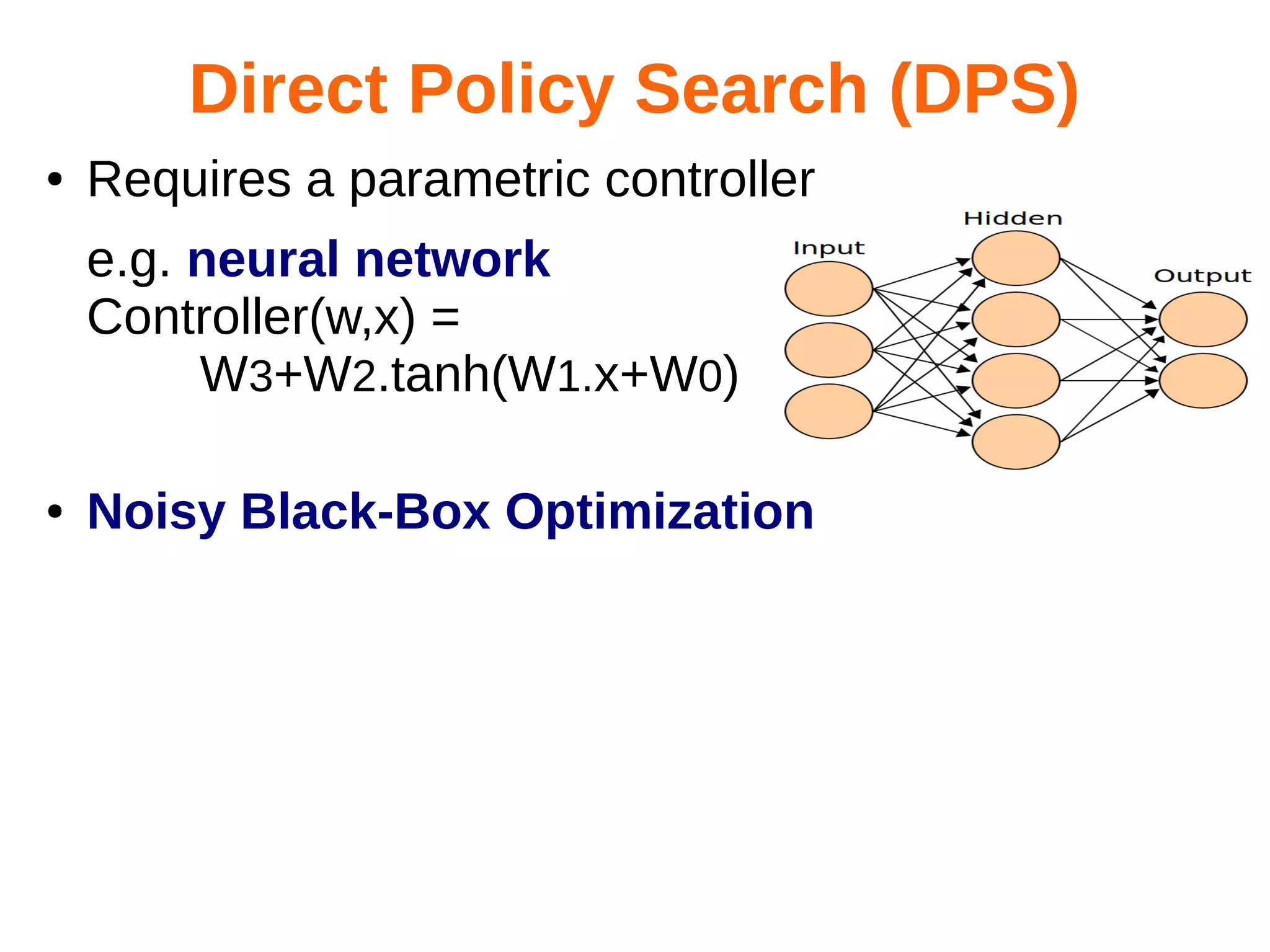
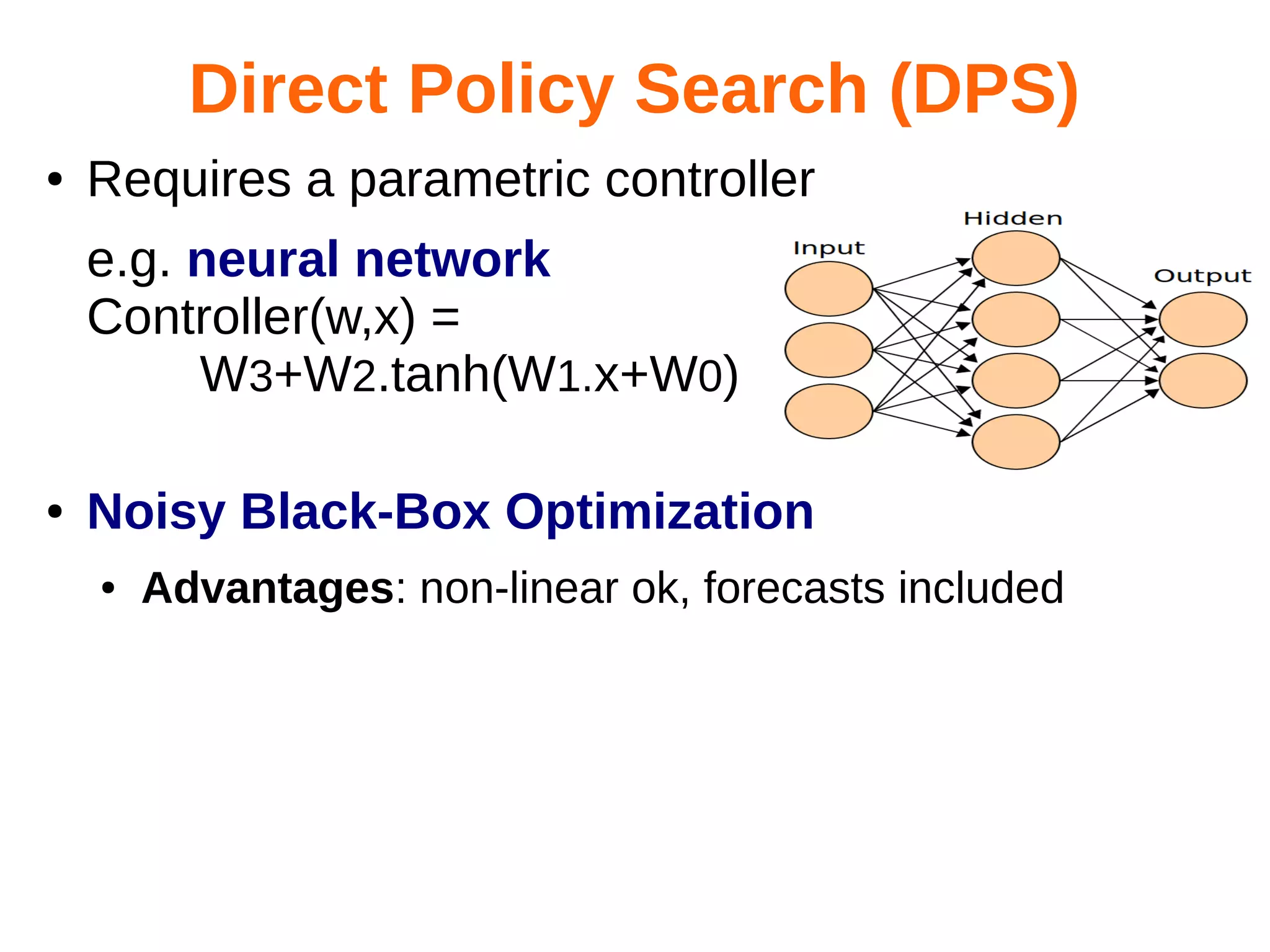


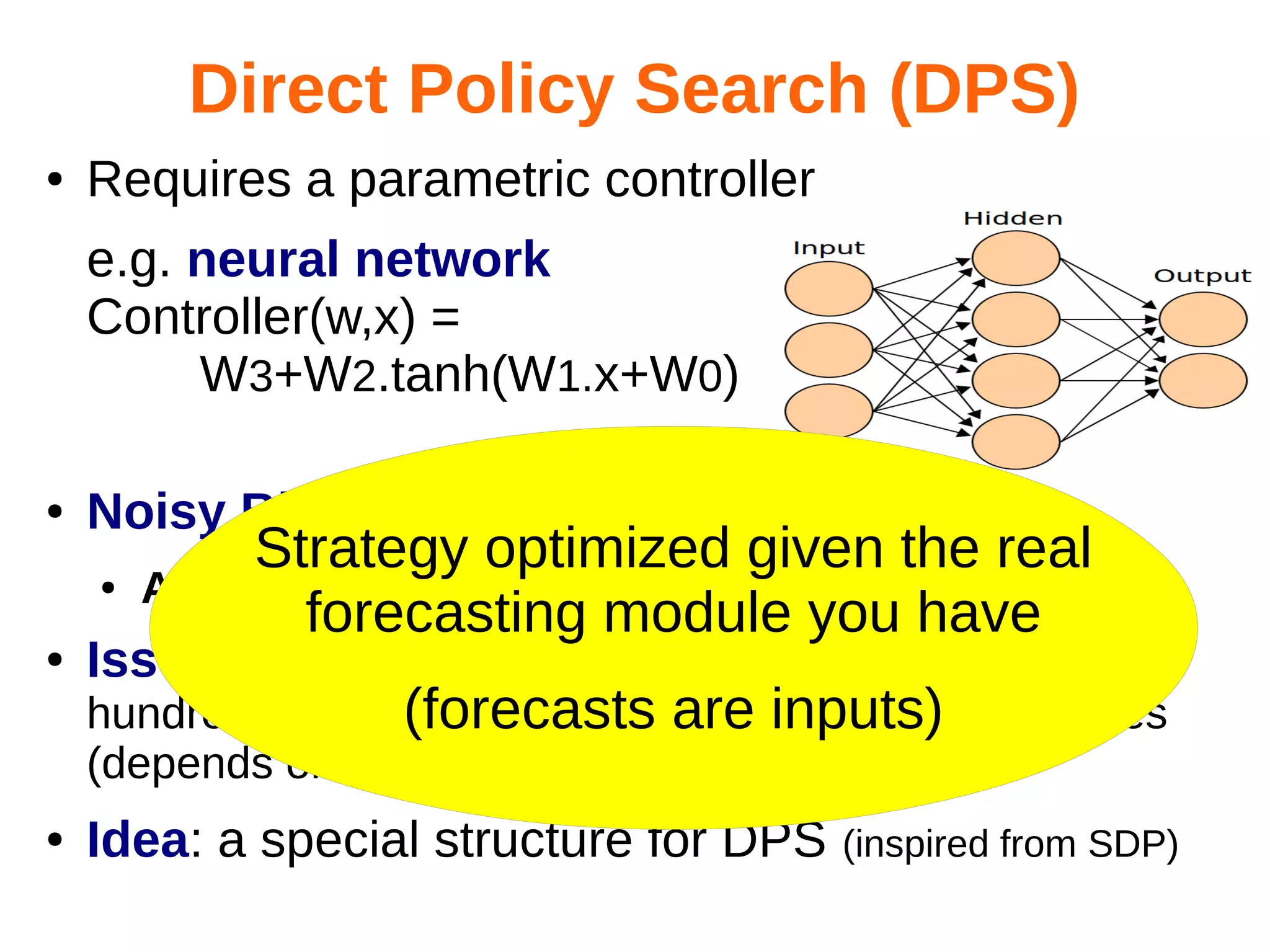





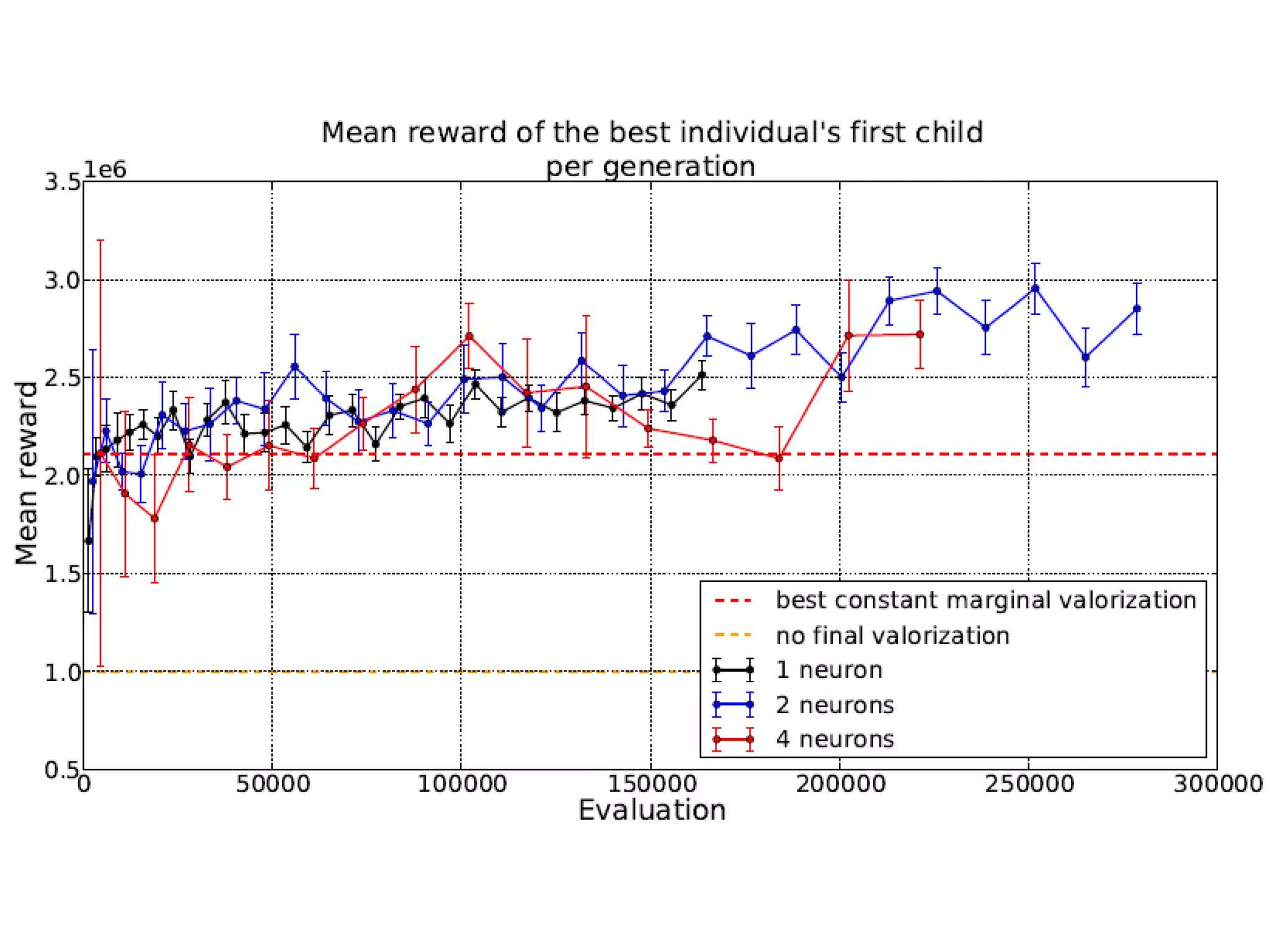
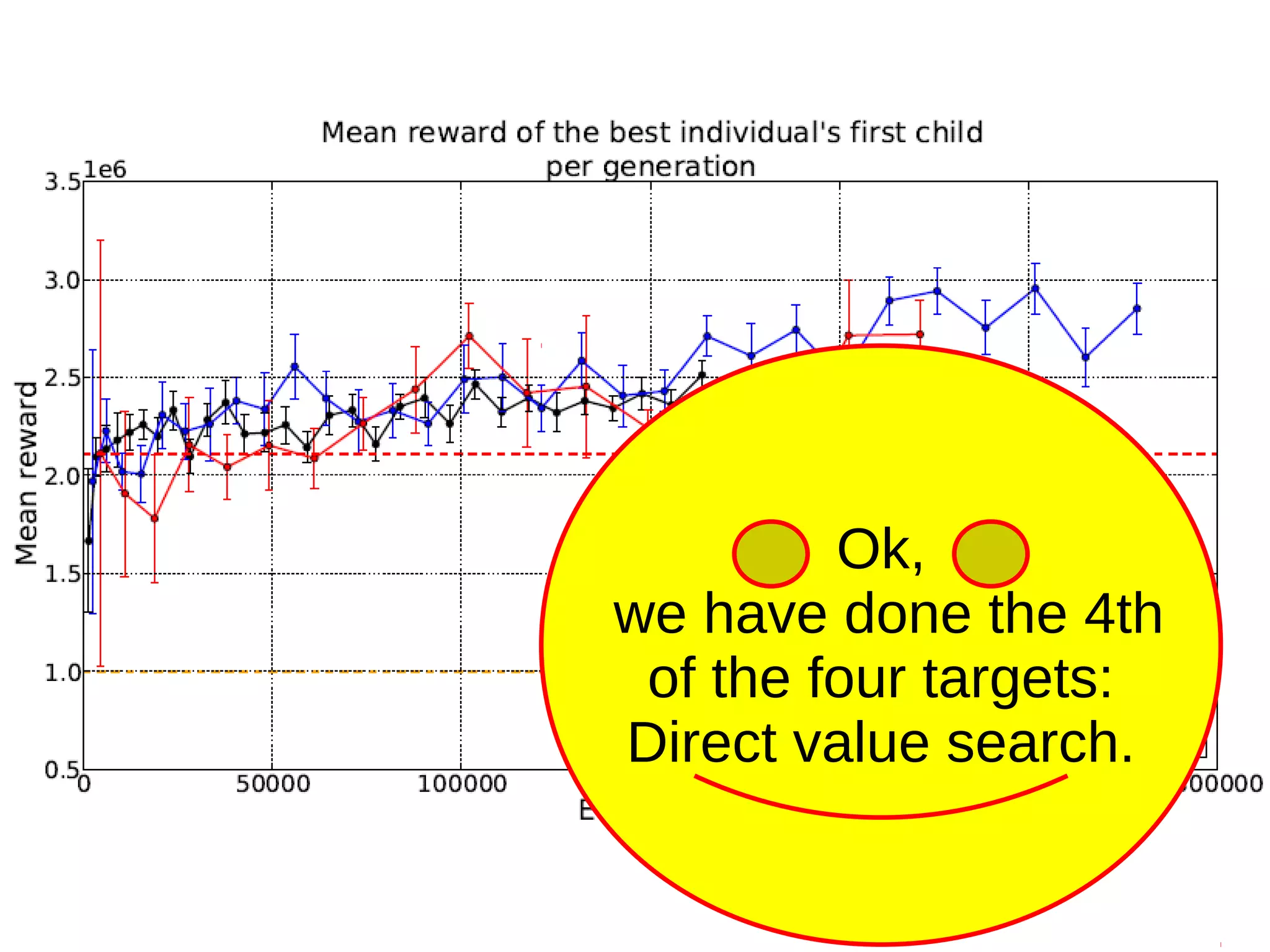







The document discusses the challenges and methodologies in optimizing power systems, particularly focusing on simulation and decision-making in strategic and tactical levels. It highlights the use of machine learning and mathematical programming to enhance predictions and policies related to energy management, while also addressing stochastic uncertainties and the need for direct policy search approaches. The research involves collaboration with various institutions and emphasizes a balance between theoretical modeling and practical applications in real-world scenarios.





















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


