










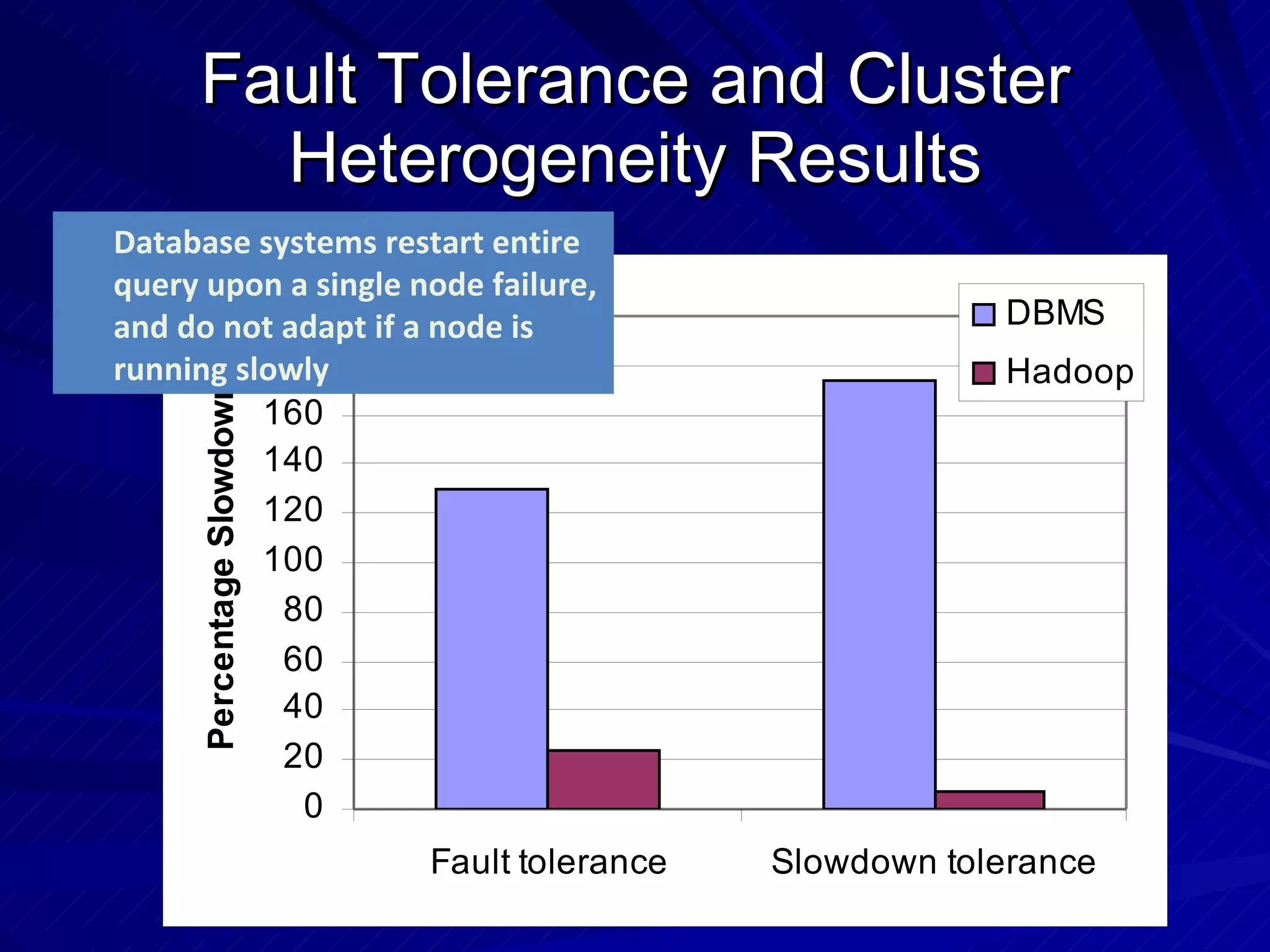


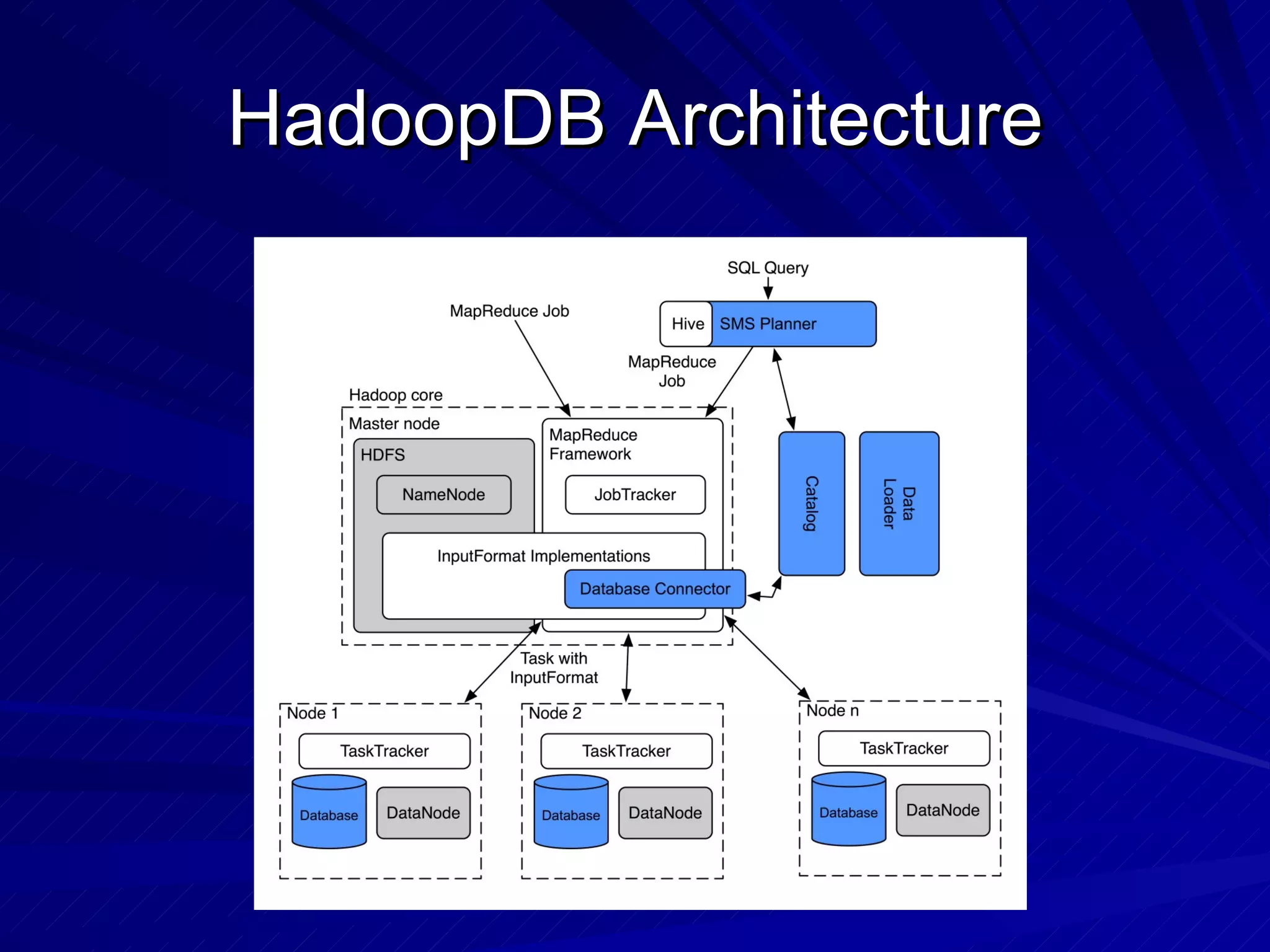
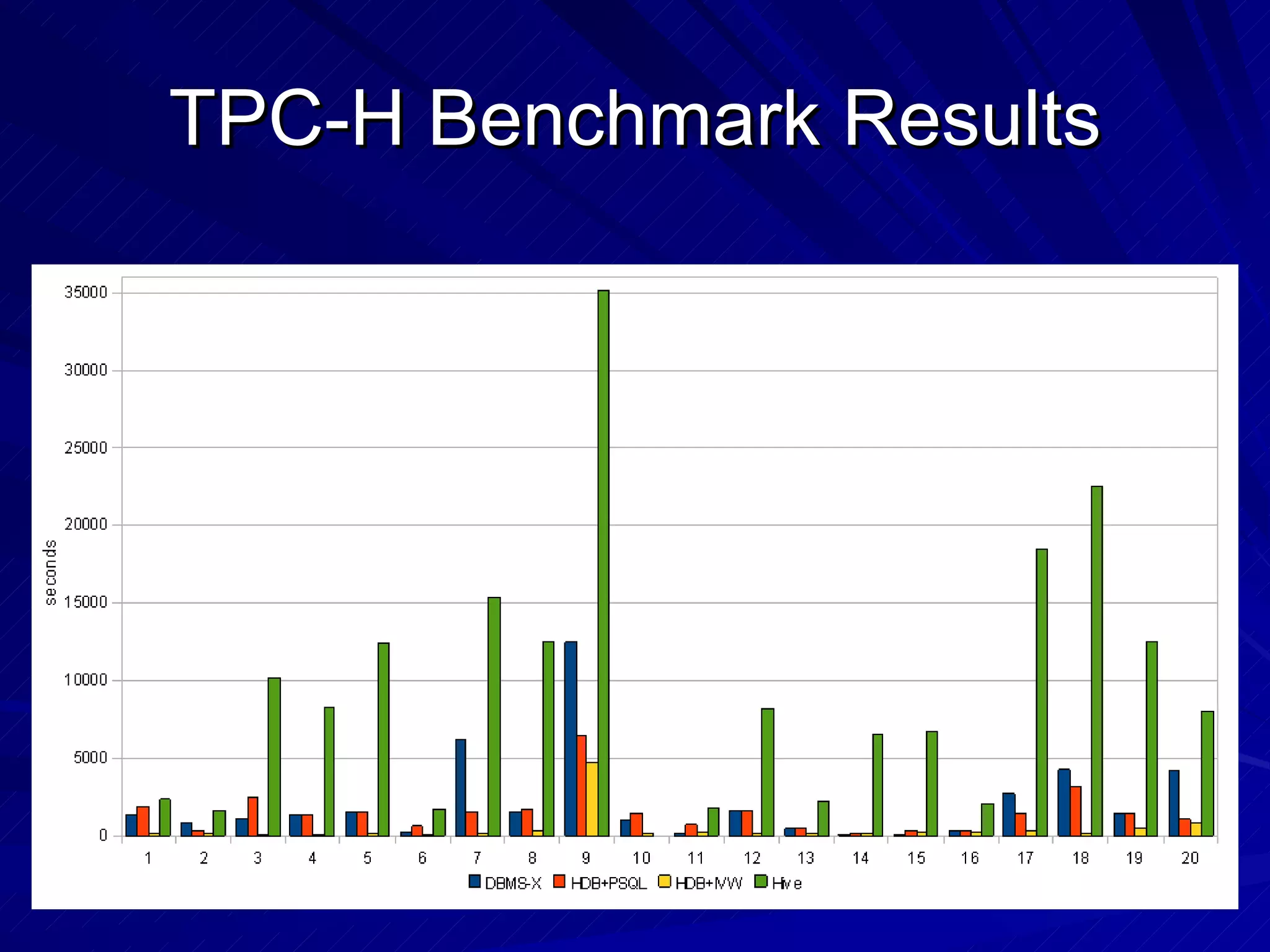
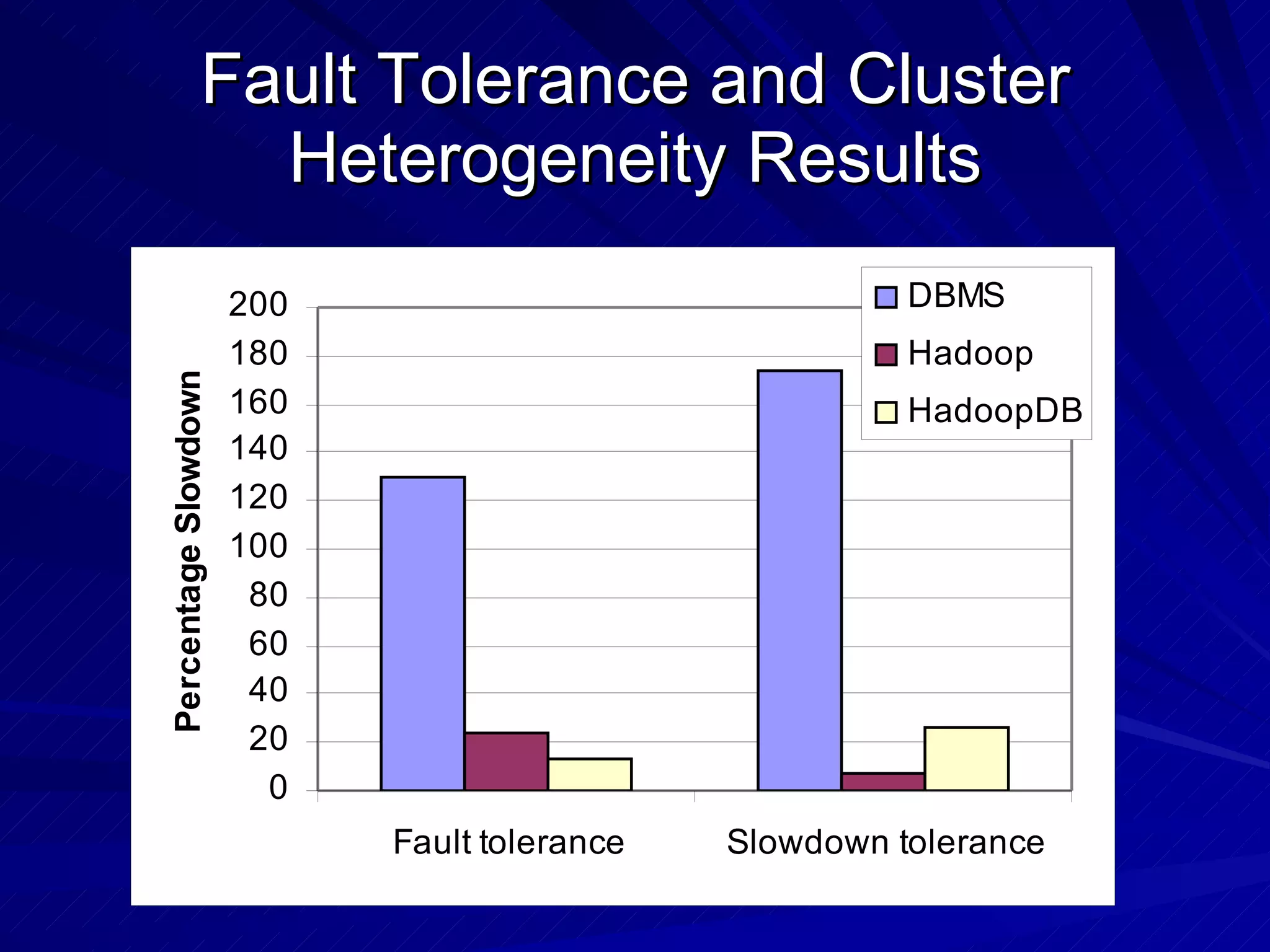




The document discusses the relationship between MapReduce systems like Hadoop and parallel database systems. It summarizes the history of MapReduce and describes benchmarks comparing Hadoop to parallel databases. While Hadoop has advantages for unstructured data processing, databases are better for structured queries. However, Hadoop is improving and being used more widely for data warehousing. HadoopDB is introduced as a way to use Hadoop for coordination while running queries on independent database systems for better performance.




































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


















