Downloaded 70 times



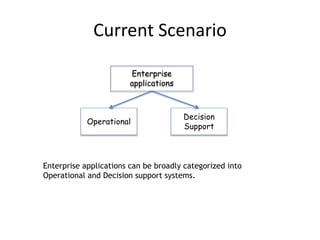
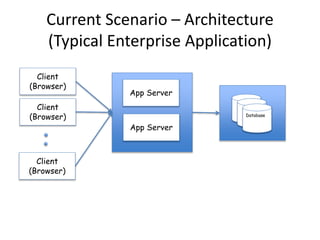

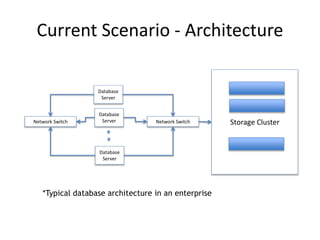


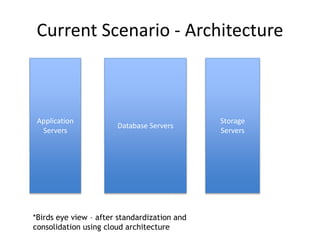

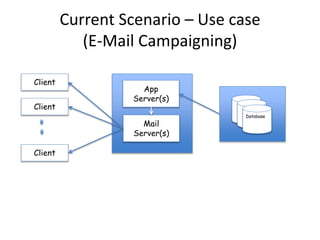

















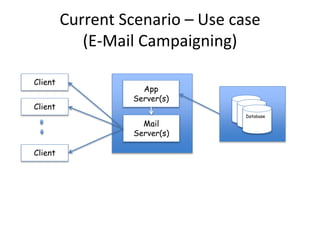


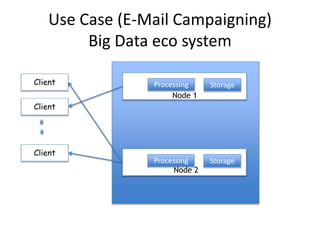


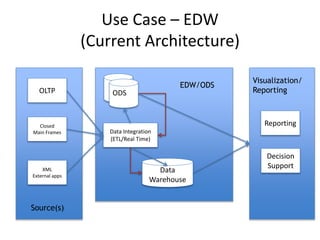

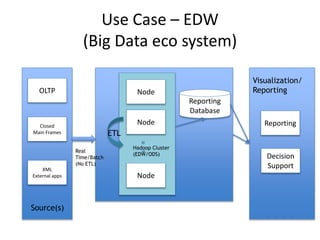
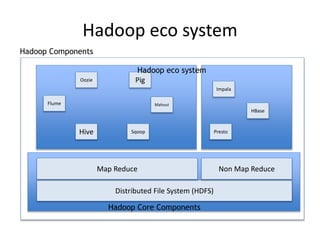
















The document discusses the evolution and current state of big data ecosystems, highlighting architectural trends, challenges, and use cases involving batch and operational systems. It elaborates on various technologies like Hadoop and NoSQL, explaining their characteristics, advantages, and specific applications in areas such as customer analytics and enterprise data warehousing. Additionally, it touches on the job roles within the big data domain and industry reactions to the technology's advancement.









































































