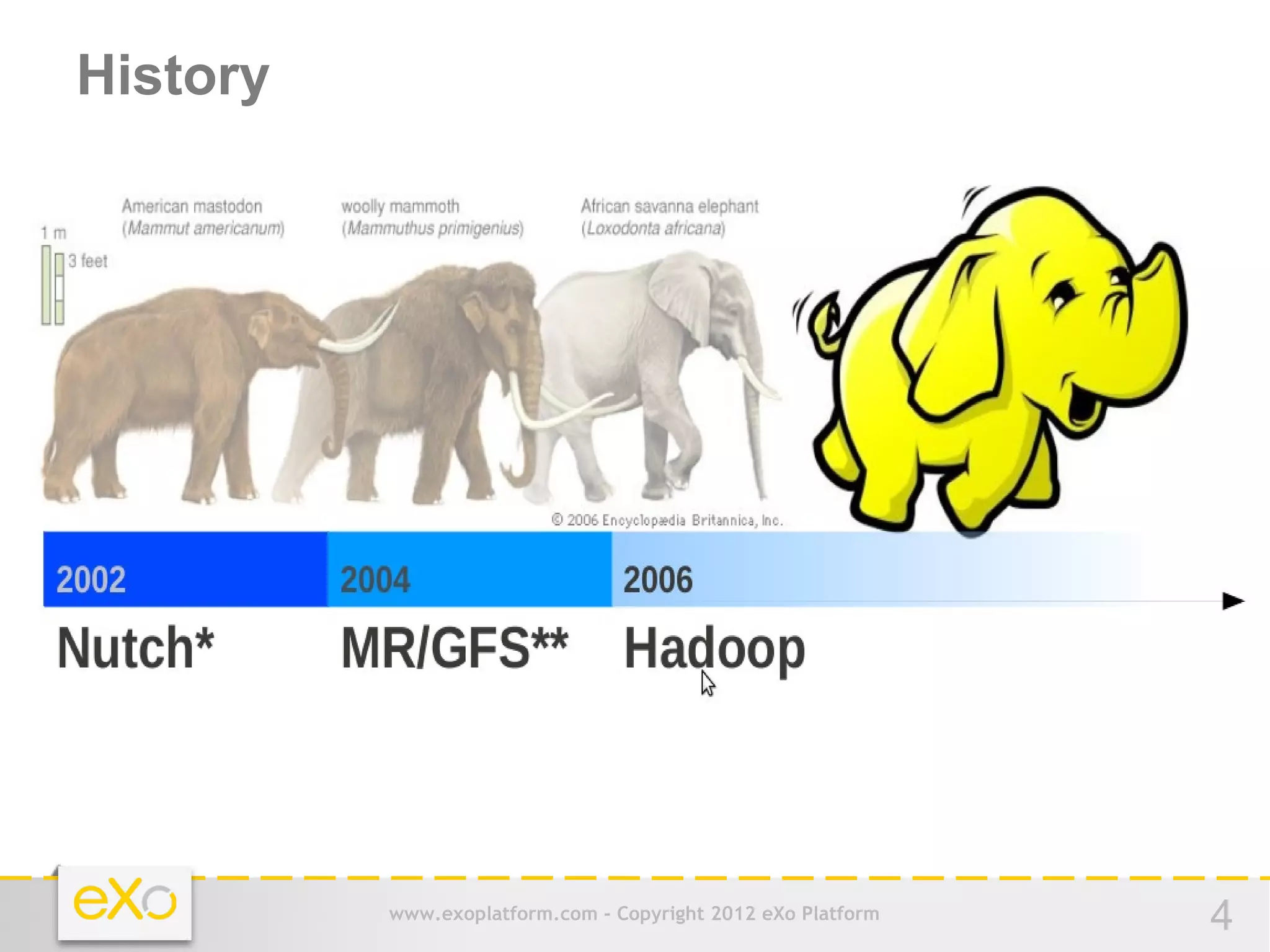
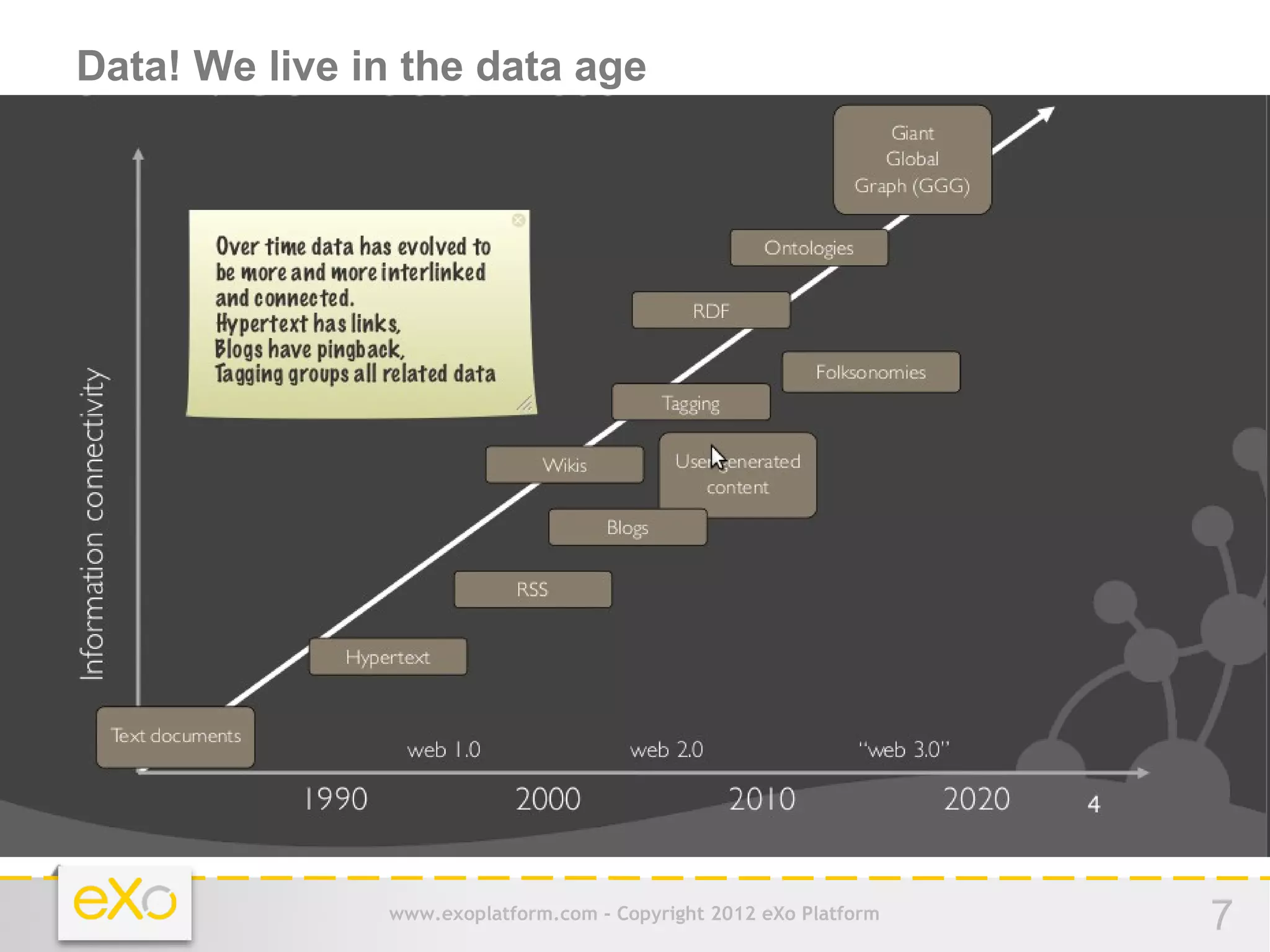
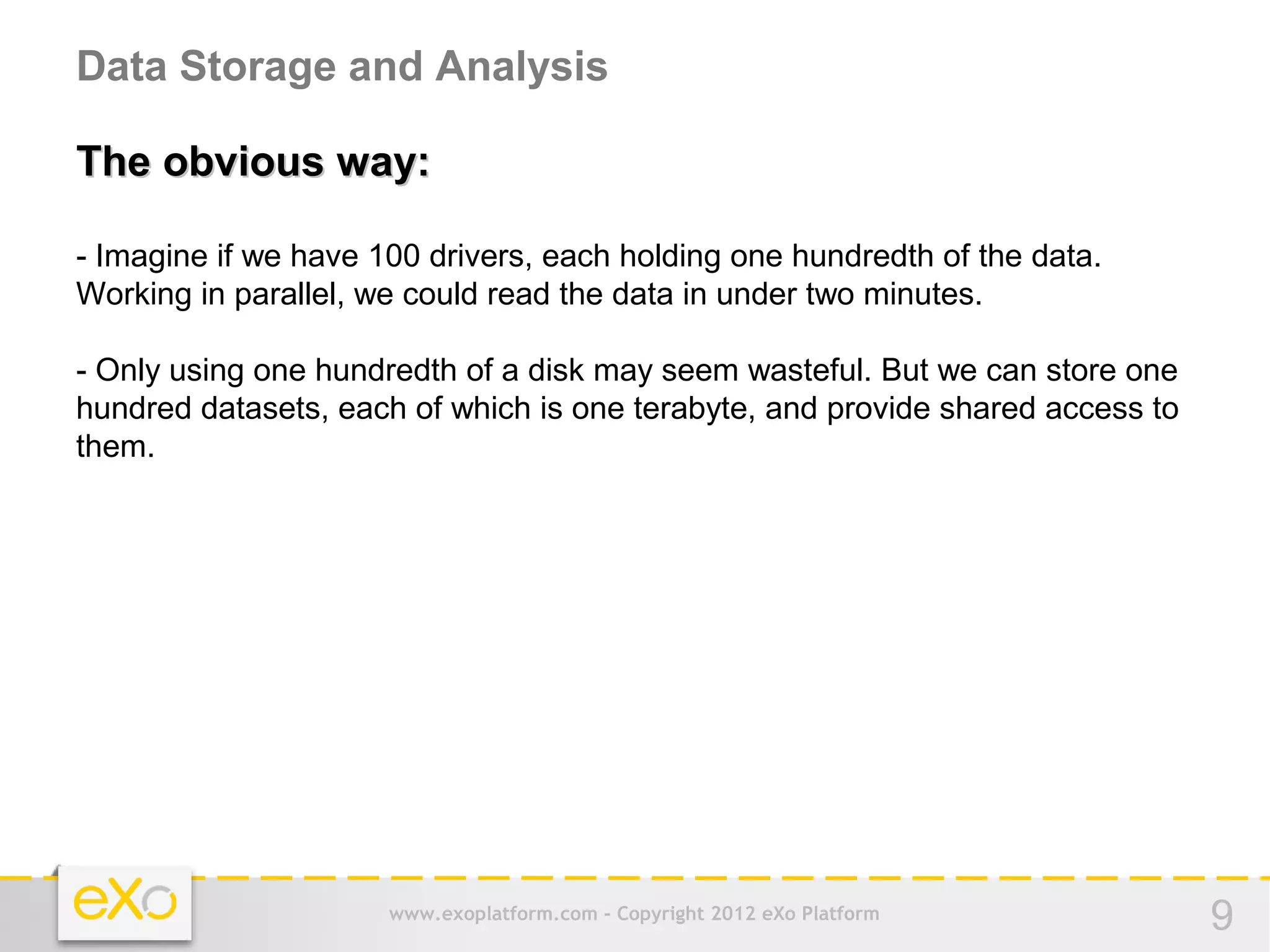
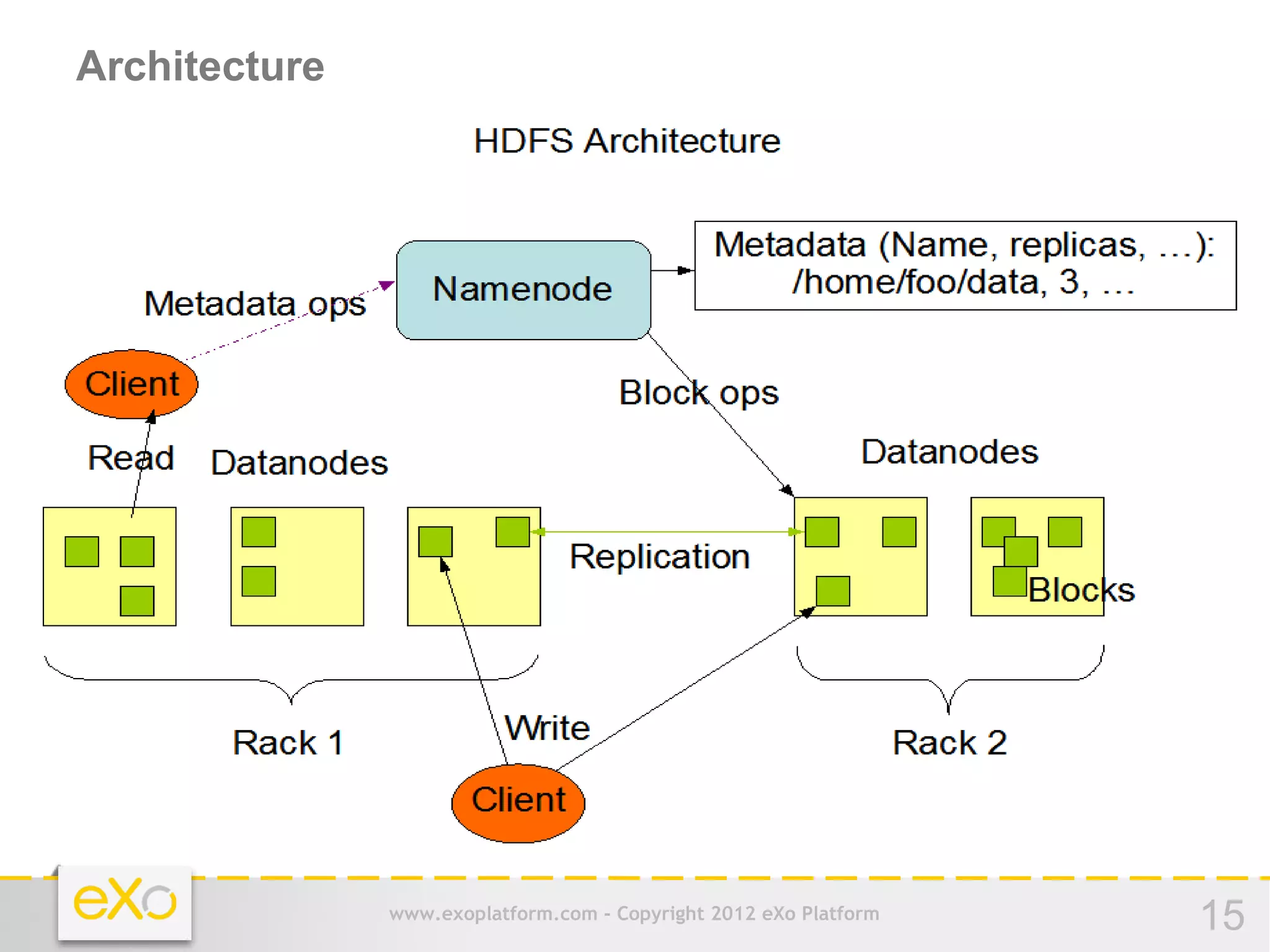
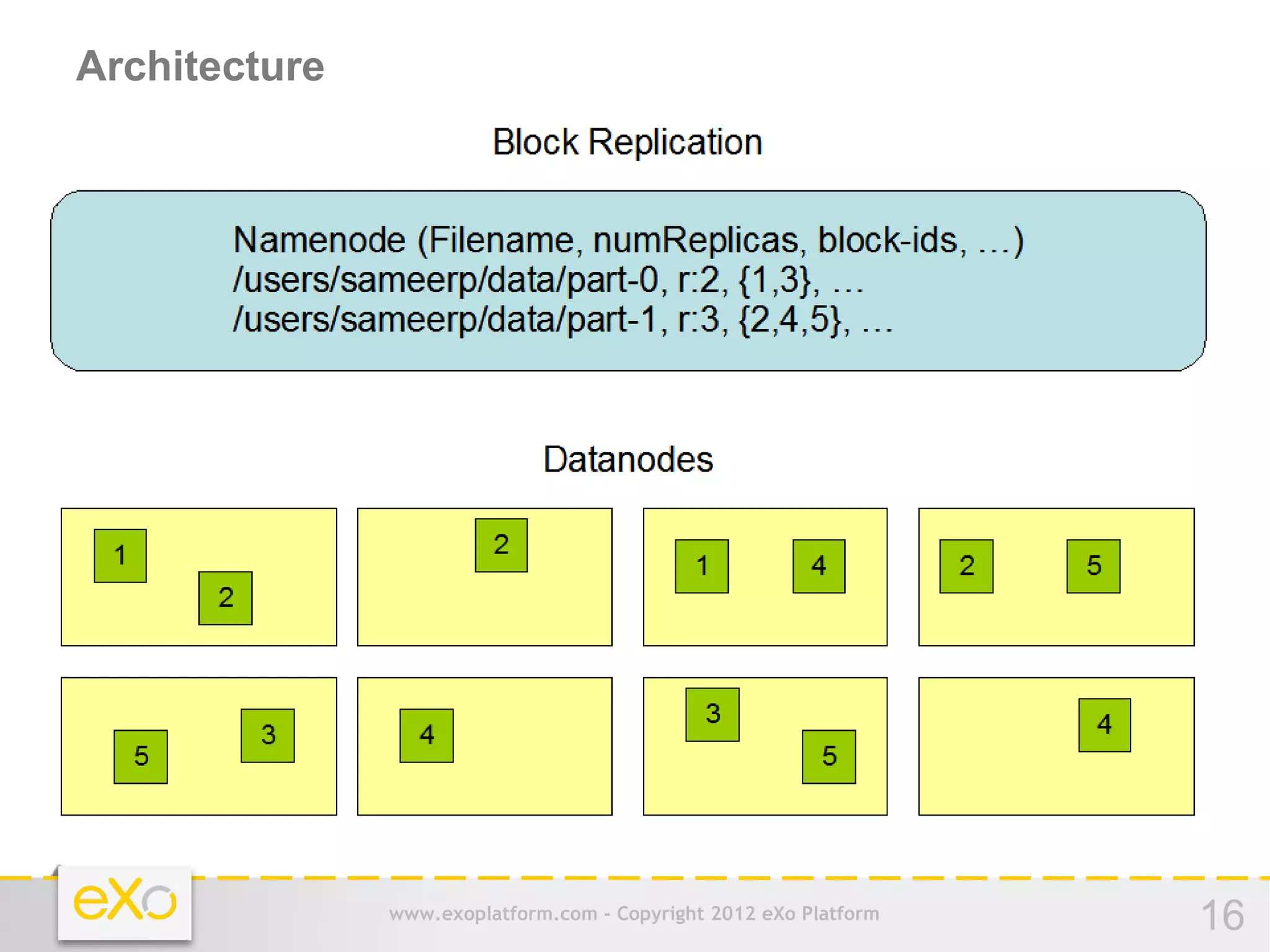
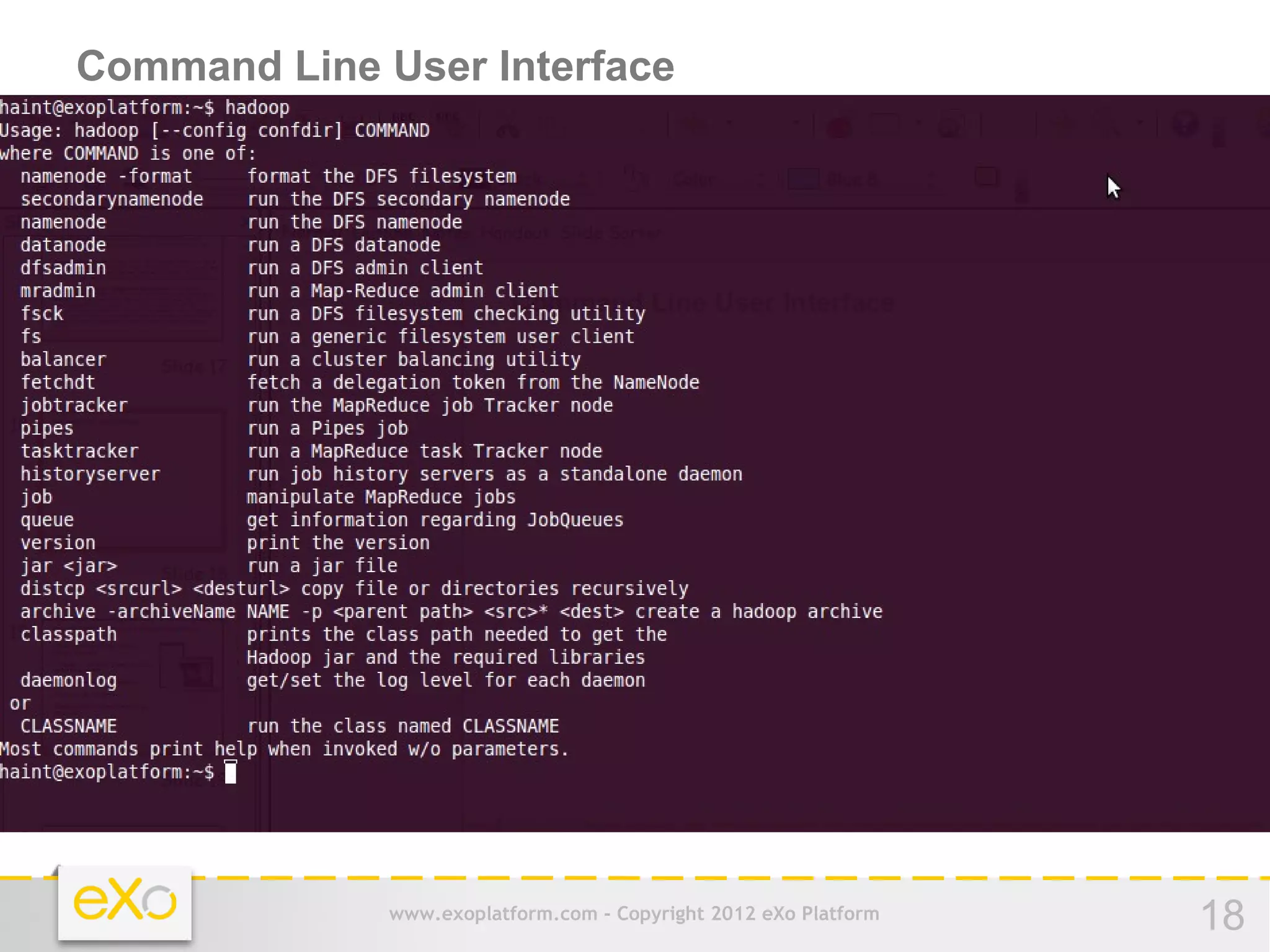
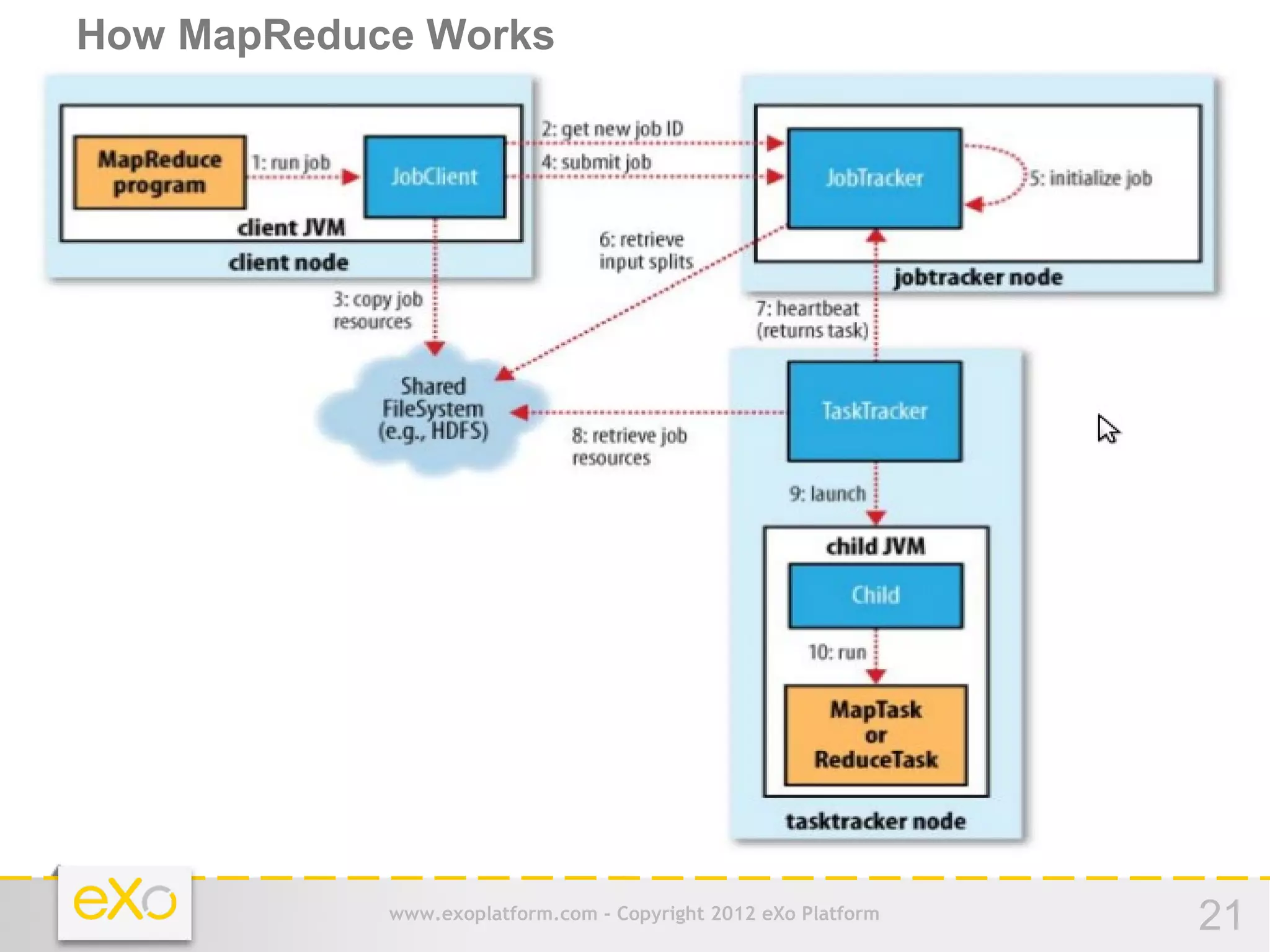
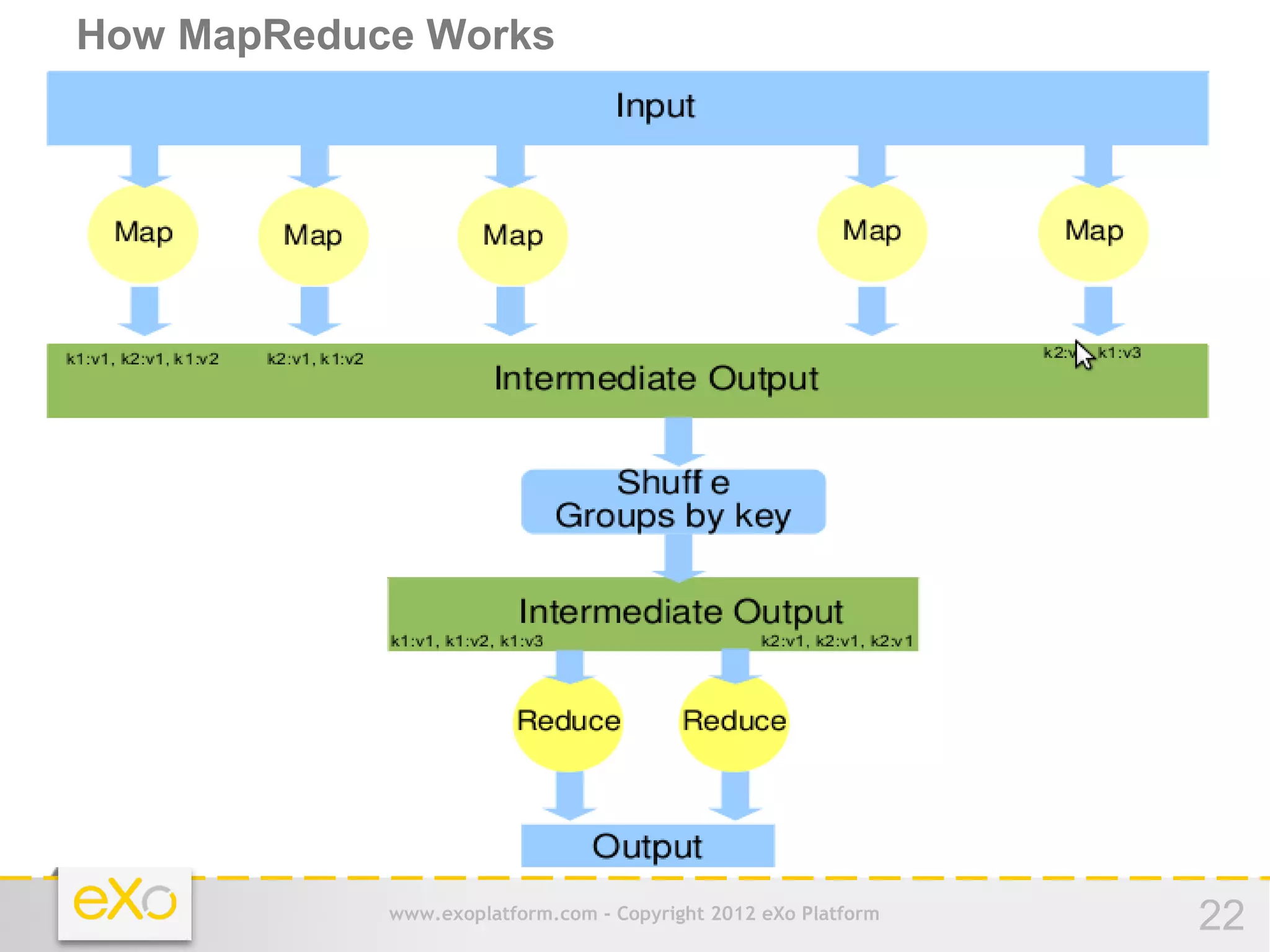
This document provides an agenda for a presentation on Hadoop. It begins with an introduction to Hadoop and its history. It then discusses data storage and analysis using Hadoop and what Hadoop is not suitable for. The remainder of the document outlines the Hadoop Distributed File System (HDFS), MapReduce framework, and concludes with a practice section involving a demo and discussion.

















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










