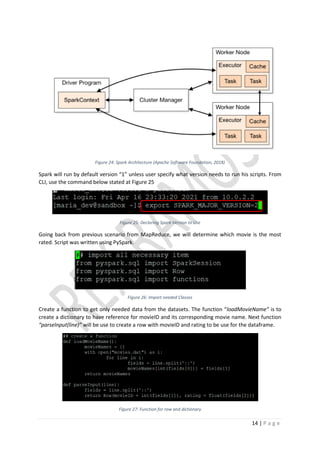
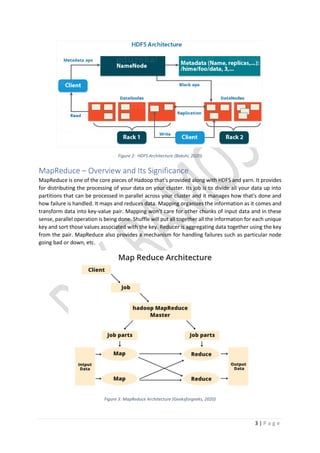
This document provides an overview of Hadoop, including its core components HDFS, MapReduce, and YARN. It describes how HDFS stores and replicates data across nodes for reliability. MapReduce is used for distributed processing of large datasets by mapping data to key-value pairs, shuffling, and reducing results. YARN was introduced to improve scalability by separating job scheduling and resource management from MapReduce. The document also gives examples of using MapReduce on a movie ratings dataset to demonstrate Hadoop functionality and running simple MapReduce jobs via the command line.






![6 | P a g e
Figure 6:Accessing Hadoop Using Putty
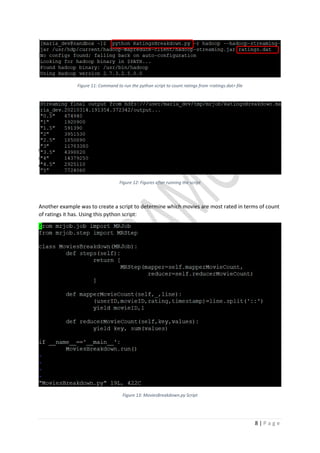
• maria_dev – is the default user name for the Hadoop sandbox we will use
• 127.0.0.1 – address to access Hadoop using Port “2222”
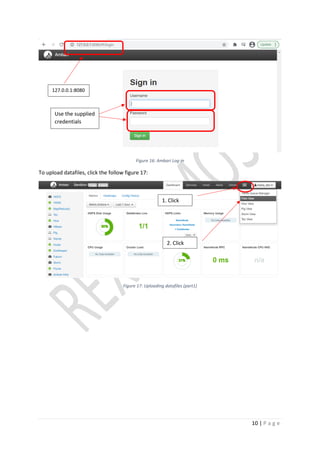
Figure 7: Accessing Hadoop file system
• Use maria_dev as password
• Create a directory to store the dataset inside Hadoop file system [-mkdir <folderName>]
• Get the dataset from source http://files.grouplens.org/datasets/movielens/ml-10m.zip
(Grouplens, 2009)
Password: maria_dev](https://image.slidesharecdn.com/understandinghadoop-210731005221/85/Understanding-hadoop-7-320.jpg)
![7 | P a g e
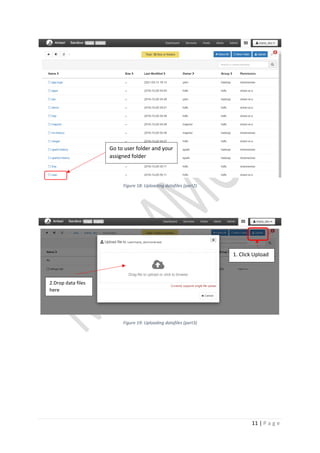
Figure 8: Unzip movie lens dataset
• Unzip is already inherent on this linux distribution, so unzip file the using cmd
[unzip <zipFile>]
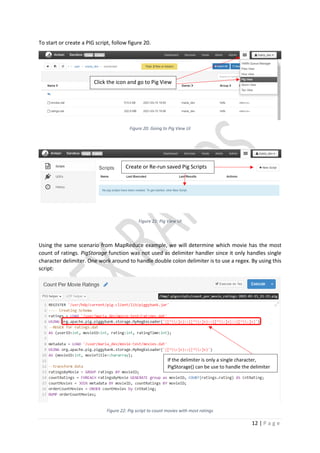
Figure 9:Transfer file from Local source to HDFS
• Transfer file from local source to HDFS file folder
[hadoop fs -copyFromLocal <sourceFile> <destinationFile>]
• Check if transfer of file is successful by checking the destination of the file
[hadoop fs -ls <destinationFile>]
Figure 10: Python script to run count of ratings](https://image.slidesharecdn.com/understandinghadoop-210731005221/85/Understanding-hadoop-8-320.jpg)