Downloaded 42 times














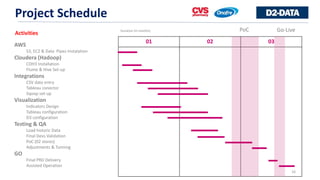




This document discusses a project to implement Hadoop on AWS to provide business analytics for a Brazilian retail pharmacy chain. Key aspects of the project include: - Migrating legacy retail data to AWS for processing using Hadoop and tools like Cloudera, Hive, and Tableau to build interactive dashboards and reports. - The goals are to provide mobile-friendly analytics with up-to-date sales data in under 10 seconds to help with retail decision making. - The architecture proposed utilizes AWS services like S3, EC2, data pipes and Cloudera on EC2 to process petabytes of retail transaction data from physical and e-commerce sources. - Tableau is chosen as the











































































































