Downloaded 49 times









![<name>instance.zookeeper.host</name>
<value>localhost:2181</value>
</property>
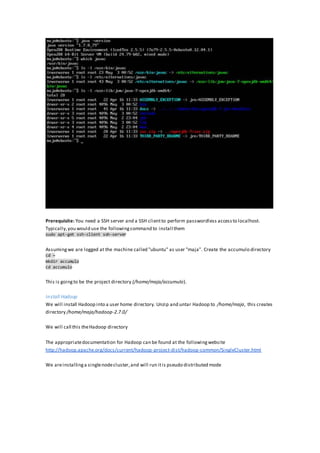
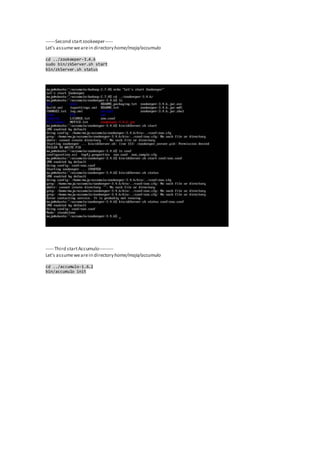
Editbin/start-server.sh (thereis somebug,thatprevents startingthemonitor).After line50 addthe
following:
# ACCUMULO-1985 patch
if [ ${SERVICE} == "monitor" -a ${ACCUMULO_MONITOR_BIND_ALL} == "true" ]; then
ADDRESS = "0.0.0.0"
fi](https://image.slidesharecdn.com/accumulo-150921185830-lva1-app6891/85/Granular-Access-Control-Using-Cell-Level-Security-In-Accumulo-13-320.jpg)





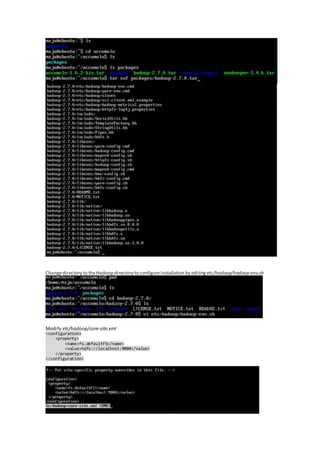
![4.0 Demo and Working Code
4.1 Java Code:
import org.apache.accumulo.core.cli.BatchWriterOpts;
import org.apache.accumulo.core.cli.ClientOnRequiredTable;
import org.apache.accumulo.core.client.AccumuloException;
import org.apache.accumulo.core.client.AccumuloSecurityException;
import org.apache.accumulo.core.client.BatchWriter;
import org.apache.accumulo.core.client.Connector;
import org.apache.accumulo.core.client.MultiTableBatchWriter;
import org.apache.accumulo.core.client.MutationsRejectedException;
import org.apache.accumulo.core.client.TableExistsException;
import org.apache.accumulo.core.client.TableNotFoundException;
import org.apache.accumulo.core.data.Mutation;
import org.apache.accumulo.core.data.Value;
import org.apache.hadoop.io.Text;
import org.apache.accumulo.core.security.ColumnVisibility;
import java.util.Random;
import java.util.GregorianCalendar;
/**
* Inserts 10K rows (50K entries) into accumulo with each row having 5
entries.
*/
public class InsertWithBatchWriter {
public static void main(String[] args) throws AccumuloException,
AccumuloSecurityException, MutationsRejectedException,
TableExistsException,
TableNotFoundException {](https://image.slidesharecdn.com/accumulo-150921185830-lva1-app6891/85/Granular-Access-Control-Using-Cell-Level-Security-In-Accumulo-20-320.jpg)
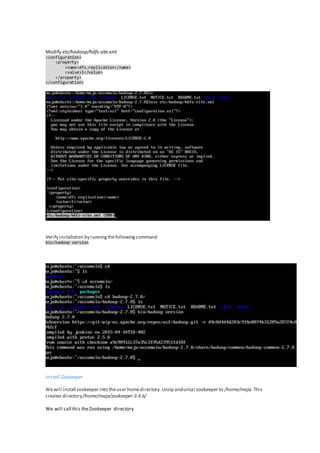
![// public static void main(String[] args) {
ClientOnRequiredTable opts = new ClientOnRequiredTable();
BatchWriterOpts bwOpts = new BatchWriterOpts();
opts.parseArgs(InsertWithBatchWriter.class.getName(), args, bwOpts);
Connector connector = opts.getConnector();
MultiTableBatchWriter mtbw =
connector.createMultiTableBatchWriter(bwOpts.getBatchWriterConfig());
if (!connector.tableOperations().exists(opts.tableName))
connector.tableOperations().create(opts.tableName);
BatchWriter bw = mtbw.getBatchWriter(opts.tableName);
int maxProc=20;
String[] proc=new String[maxProc+1];
for(int i=0;i<maxProc;i++) {
proc[i]=randomString(5);
}
BatchWriter ibw=mtbw.getBatchWriter("insurers");
Text coli=new Text("insurer");
int maxIns=50;
String[] insurer=new String[maxIns+1];
for(int i=0;i<maxIns;i++) {
insurer[i]=randomString(5);
System.out.println("Generating Insurer "+i+insurer[i]);
Mutation mi = new Mutation(new Text(String.format("ins_%d",i)));
long ts=System.currentTimeMillis();
ColumnVisibility colVisAdmin = new ColumnVisibility("Admin");
mi.put(coli, new Text("name"), colVisAdmin, ts, new
Value(insurer[i].getBytes()));
int rank=rnd.nextInt( 10 );
// System.out.println("rank=" + rank);
mi.put(coli, new Text("rank"), colVisAdmin, ts, new
Value((Integer.toString(rank)).getBytes()));
ibw.addMutation(mi);
}
int maxPro=50;
String[] provider=new String[maxPro+1];
for(int i=0;i<maxPro;i++) {
provider[i]=randomString(5);
}
Text colf = new Text("colfam");
System.out.println("writing ...");
for (int i = 0; i < 1000000; i++) {
Mutation m = new Mutation(new Text(String.format("id_%d", i)));
long timestamp=System.currentTimeMillis();
int ppi=rnd.nextInt( maxIns );
// System.out.println("insurer #=" + ppi);
String ins=insurer[ ppi ];
// System.out.println("insurer=" + ins);
String dd=randomDate();
ColumnVisibility colVisPublic = new ColumnVisibility("public");
m.put(colf, new Text("date"), colVisPublic, timestamp, new
Value(dd.getBytes()));
ColumnVisibility colVis = new ColumnVisibility( ins );
String cl=randomString(8);
// System.out.println("client=" + cl);
m.put(colf, new Text("client"), colVis, timestamp, new
Value(cl.getBytes()));
ppi=rnd.nextInt( maxProc );](https://image.slidesharecdn.com/accumulo-150921185830-lva1-app6891/85/Granular-Access-Control-Using-Cell-Level-Security-In-Accumulo-21-320.jpg)
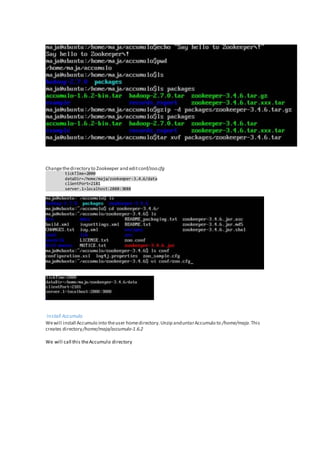
![// System.out.println("procedure #=" + ppi);
String pp=proc[ ppi ];
// System.out.println("procedure=" + pp);
m.put(colf, new Text("procedure"), colVisPublic, timestamp, new
Value(pp.getBytes()));
m.put(colf, new Text("insurer"), colVis, timestamp, new
Value(ins.getBytes()));
ppi=rnd.nextInt( maxPro );
// System.out.println("provider #=" + ppi);
String pro=provider[ ppi];
// System.out.println("provider=" + pro);
m.put(colf, new Text("provider"), colVis, timestamp, new
Value(pro.getBytes()));
int amt=rnd.nextInt( 10000 );
// System.out.println("amount=" + amt);
m.put(colf, new Text("amount"), colVis, timestamp, new
Value((Integer.toString(amt)).getBytes()));
bw.addMutation(m);
if (i % 100 == 0)
System.out.println(i);
}
mtbw.close();
}
static final String AB="0123456789ABCDEFGIJKLMNOPQRSTUVWXYZ";
static Random rnd=new Random();
static String randomString( int len ) {
StringBuilder sb = new StringBuilder( len );
for( int i=0;i<len; i++ )
sb.append( AB.charAt( rnd.nextInt(AB.length())));
return sb.toString();
}
static String randomDate() {
GregorianCalendar gc=new GregorianCalendar();
int year=randomBetween(1900,2015);
gc.set(gc.YEAR, year);
int dayOfYear = randomBetween(1,gc.getActualMaximum(gc.DAY_OF_YEAR));
gc.set(gc.DAY_OF_YEAR, dayOfYear);
String yymmdd=gc.get(gc.YEAR)+"-"+gc.get(gc.MONTH)+"-
"+gc.get(gc.DAY_OF_MONTH);
// System.out.println( "date="+yymmdd);
return yymmdd;
}
private static int randomBetween(int start, int end) {
return start+(int)Math.round(Math.random() * (end-start));
}
}
Pleasenote that this code generates the randomized claims processordata thatis used in the demo. Each
clienthas an identifier,the procedure they got, the year and the insurer through which the clientgot paid
through. When Accumulo is up and running,the Java scriptis then run and the data is populated and used
for further demonstration.
4.2 Demo
Now let’s demonstrate the different visibility settings we have once the code has generated our
randomized data. We have two tables produced, records and insurer. Based on which table we are](https://image.slidesharecdn.com/accumulo-150921185830-lva1-app6891/85/Granular-Access-Control-Using-Cell-Level-Security-In-Accumulo-22-320.jpg)






The document discusses the implementation of granular access control in Apache Accumulo, addressing the challenges of privacy and data security in big data environments. It emphasizes the importance of a cell-level security model that allows flexible data sharing without compromising secrecy. The paper outlines installation steps, issues encountered, and lessons learned while configuring Accumulo on a local machine to demonstrate its capabilities.



































































