Downloaded 15 times






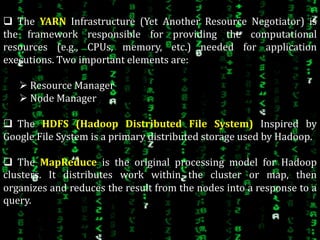


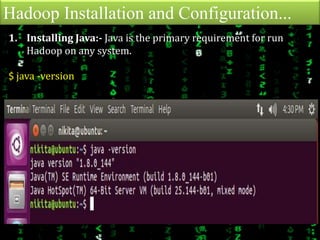
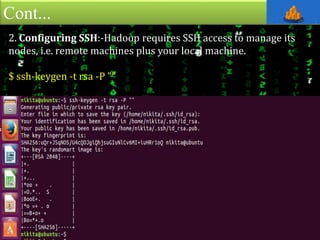





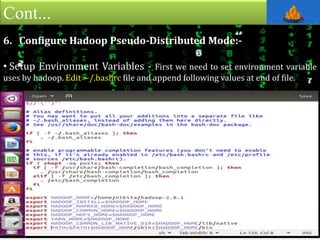


















This document provides an overview of Apache Hadoop, an open-source framework for distributed storage and processing of large datasets across clusters of computers. It discusses what Hadoop is, why it is useful for big data problems, examples of companies using Hadoop, the core Hadoop components like HDFS and MapReduce, and how to install and run Hadoop in pseudo-distributed mode on a single node. It also includes an example of running a word count MapReduce job to count word frequencies in input files.



































































