Chapter 3 –Oracle Instance
Oracle Database Management Best Practice
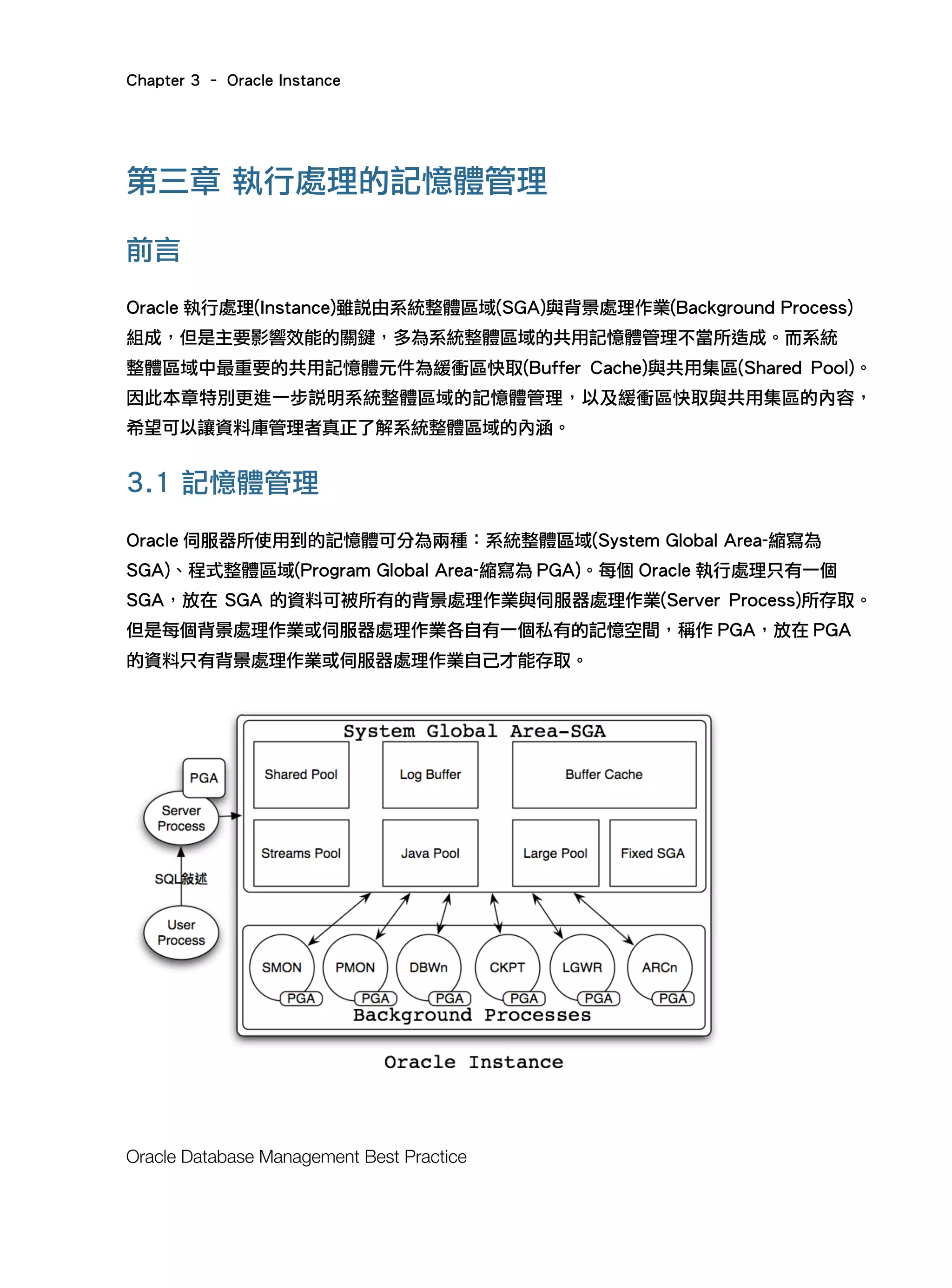
3.1.2 自動共用記憶體管理(Automatic Shared Memory
Management)
在 Oracle Database10g 的時代,雖然沒有自動記憶體管理的功能,但是資料庫管理者可以
使用自動共用記憶體管理(Automatic Shared Memory Management-縮寫為 ASMM)的功能,
讓資料庫管理者僅需設定 SGA 總大小(SGA_TARGET)的值即可,其餘共用記憶體元件的大
小則自動依 Oracle 伺服器狀態自動決定,而且還可以動態地調整共用記憶體元件的大小。
至於自動記憶體管理與自動共用記憶體管理的差異,則在於自動記憶體管理可以同時自動管
理 SGA 與 PGA 的大小。而自動共用記憶體管理只能自動管理 SGA 的大小,不能管理 PGA
的大小。不過自 Oracle Database 9i 開始,資料庫管理者可以藉由設定 PGA 聚總目標
(PGA_AGGREGATE_TARGET)讓 PGA 的管理機制變成自動管理。所以在 Oracle Database
10g 只要啟用(Enable)自動共用記憶體管理與設定 PGA 聚總目標,便可以達到類似 Oracle
Database 11g 自動記憶體管理的效果。
啟用自動共用記憶體管理,只需將 SGA_TARGET 的值設為大於 0 即可 。資料庫管理者可以
透過下列的步驟,啟用自動共用記憶體管理:
1.取得 SYSDBA 的權限。
2.如果是 Oracle Database 11g,需要先停用(Disable)自動記憶體管理。
SQL> SHOW PARAMETER target
NAME TYPE VALUE
------------------------------------------ ---------------- ------------------------------
memory_max_target big integer 544M
memory_target big integer 544M
pga_aggregate_target big integer 0
sga_target big integer 0
SQL> ALTER SYSTEM SET memory_target=0; --停用自動記憶體管理
SQL> SHOW PARAMETER target
NAME TYPE VALUE
------------------------------------------ ----------------------- ----------------------------
pga_aggregate_target big integer 0
sga_target big integer 0
11.
Chapter 3 –Oracle Instance
Oracle Database Management Best Practice
SQL> SHOW PARAMETER pool_size
NAME TYPE VALUE
------------------------------------------ ----------------------- --------------------------
java_pool_size big integer 24M
large_pool_size big integer 0
shared_pool_size big integer 64M
streams_pool_size big integer 0
SQL> SHOW PARAMETER cache_size
NAME TYPE VALUE
------------------------------------------ ---------------------- ---------------------------
db_16k_cache_size big integer 0
db_2k_cache_size big integer 0
db_32k_cache_size big integer 0
db_4k_cache_size big integer 0
db_8k_cache_size big integer 0
db_cache_size big integer 48M
db_keep_cache_size big integer 0
db_recycle_cache_size big integer 0
由以上範例可以得知目前自動共用記憶體管理的功能是停用,因為 SGA_TARGET 的值為 0。
而 SHARED POOL 與 JAVA POOL、DEFAULT BUFFER CACHE 的值為記載於參數檔的
設定。
3.設定 SGA_TARGET 為適當值。
SQL> SHOW PARAMETER sga
NAME TYPE VALUE
---------------------------------------- ------------------------- -----------------
sga_max_size big integer 544M
sga_target big integer 0
/*啟用自動共用記憶體管理時,注意sga_target必須小於等於sga_max_size
若sga_max_size為0,則需要先設定sga_max_size參數,才能設定sga_target參數。可是sga_
max_size為靜態參數,必須使用下面的指令才能設定。
ALTER SYSTEM SET sga_max_size=544M SCOPE=spfile。
並且重新啟動Oracle執行處理,才能生效。*/
SQL> ALTER SYSTEM SET sga_target=300M;
SQL> SHOW PARAMETER sga
NAME TYPE VALUE
12.
Chapter 3 –Oracle Instance
Oracle Database Management Best Practice
---------------------------------------- ------------------------- -----------------
sga_max_size big integer 544M
sga_target big integer 300M
SQL> SHOW PARAMETER pool_size
NAME TYPE VALUE
---------------------------------------- ------------------------ -----------------
java_pool_size big integer 0
large_pool_size big integer 0
shared_pool_size big integer 0
streams_pool_size big integer 0
SQL> SHOW PARAMETER cache_size
NAME TYPE VALUE
---------------------------------------- ------------------ -----------------
db_16k_cache_size big integer 0
db_2k_cache_size big integer 0
db_32k_cache_size big integer 0
db_4k_cache_size big integer 0
db_8k_cache_size big integer 0
db_cache_size big integer 0
db_keep_cache_size big integer 0
db_recycle_cache_size big integer 0
由上面的範例結果來看,可以看到 SGA_TARGET 為 300M,而其他組成 SGA 的共用記憶體
元件都沒有明確設定其大小,則那些共用記憶體元件的大小則由 Oracle 伺服器依整體的狀態
來決定。
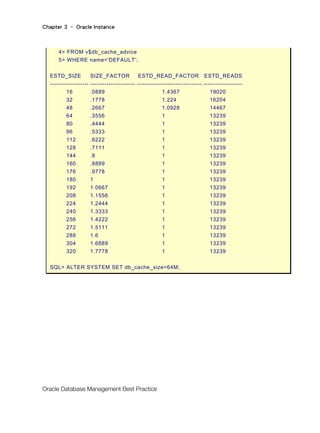
但是目前 SGA_TARGET 設定為 300M 到底夠不夠用?管理者可已由 V$
SGA_TARGET_ADVICE 得知,若加大 SGA_TARGET 的值是否有好處?反之若減少
SGA_TARGET 的值是否影響整體的效能?
SQL> SELECT sga_size,sga_size_factor size_factor,
2> estd_db_time_factor time_factor,estd_physical_reads phy_reads
3> FROM v$sga_target_advice;
SGA_SIZE SIZE_FACTOR TIME_FACTOR PHY_READS
--------------------------- ------------------------ ------------------- ---------------------
300 1 1 12970
225 .75 1.0429 12970
375 1.25 1 12970
13.
Chapter 3 –Oracle Instance
Oracle Database Management Best Practice
450 1.5 .7786 9604
525 1.75 .7786 9604
600 2 .7786 9604
--如果有足夠的Free Memory
SQL> SELECT * FROM v$sga_dynamic_free_memory;
CURRENT_SIZE
----------------------
255852544 --尚有244M的可用記憶體空間
SQL> ALTER SYSTEM SET sga_target=450M;
--如果目前的Free Memory不足
SQL> SELECT * FROM v$sga_dynamic_free_memory;
CURRENT_SIZE
----------------------
0
/*沒有多餘的可用記憶體,因此必須同步增加sga_max_size2的值,但是sga_max_size為靜態
參數,必須先設定到參數檔,等執行處理重新啟動後,才會生效。*/
SQL> ALTER SYSTEM SET sga_max_size=450M SCOPE=spfile;
SQL> ALTER SYSTEM SET sga_target=450M SCOPE=spfile;
--重新啟動執行處理,讓新的sga_max_size與sga_target設定生效
Chapter 3 –Oracle Instance
Oracle Database Management Best Practice
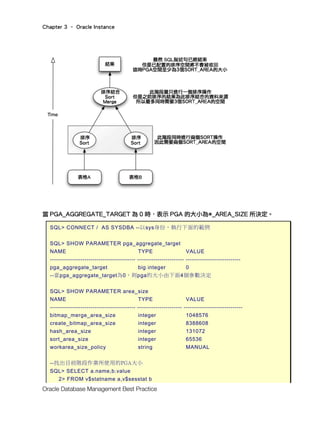
當 PGA_AGGREGATE_TARGET 為 0 時,表示 PGA 的大小為*_AREA_SIZE 所決定。
SQL> CONNECT / AS SYSDBA --以sys身份,執行下面的範例
SQL> SHOW PARAMETER pga_aggregate_target
NAME TYPE VALUE
------------------------------------------ ----------------------- ---------------------------
pga_aggregate_target big integer 0
--當pga_aggregate_target為0,則pga的大小由下面4個參數決定
SQL> SHOW PARAMETER area_size
NAME TYPE VALUE
------------------------------------------ ---------------------- -----------------------------
bitmap_merge_area_size integer 1048576
create_bitmap_area_size integer 8388608
hash_area_size integer 131072
sort_area_size integer 65536
workarea_size_policy string MANUAL
--找出目前階段作業所使用的PGA大小
SQL> SELECT a.name,b.value
2> FROM v$statname a,v$sesstat b
26.
Chapter 3 –Oracle Instance
Oracle Database Management Best Practice
3> WHERE a.statistic#=b.statistic#
4> AND (a.name LIKE 'session%ga memory%%' OR a.name LIKE '%direct temp%')
5> AND sid=(SELECT distinct sid FROM v$mystat);
NAME VALUE
------------------------------------------------------------------ ----------
session uga memory 170876
session uga memory max 236340
session pga memory 473472 --目前使用量
session pga memory max 539008 --最大值
physical reads direct temporary tablespace 0
physical writes direct temporary tablespace 0
-- 建立一個測試表格
SQL> CREATE TABLE t1 AS SELECT * FROM dba_objects;
--收集表格的統計資料
SQL> EXECUTE DBMS_STATS.GATHER_TABLE_STATS(‘SYS’,’T1’);
--啟動自動追蹤觀察,並僅顯示所使用的資源數量
SQL> SET AUTOTRACE TRACEONLY STATISTICS;
SQL> SELECT * FROM t1 ORDER BY 1;
Statistics
----------------------------------------------------------
12 recursive calls
265 db block gets
1018 consistent gets
3080 physical reads
0 redo size
3880633 bytes sent via SQL*Net to client
50932 bytes received via SQL*Net from client
4594 SQL*Net roundtrips to/from client
0 sorts (memory)
1 sorts (disk) --當sort_area_size=64K時,需要進行磁碟排序
68888 rows processed
--將SORT_AREA_SIZE增加為10M
SQL> ALTER SESSION SET sort_area_size=10240000;
SQL> SELECT * FROM t1 ORDER BY 1;
Statistics
27.
Chapter 3 –Oracle Instance
Oracle Database Management Best Practice
----------------------------------------------------------
10 recursive calls
9 db block gets
1018 consistent gets
1036 physical reads
0 redo size
3224976 bytes sent via SQL*Net to client
50932 bytes received via SQL*Net from client
4594 SQL*Net roundtrips to/from client
0 sorts (memory)
1 sorts (disk) --當sort_area_size=10M時,還是需要進行磁碟排序
68888 rows processed
--繼續增加SORT_AERA_SIZE的值到64M
SQL> ALTER SESSION SET sort_area_size=65536000;
SQL> SELECT * FROM t1 ORDER BY 1;
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
1018 consistent gets
0 physical reads
0 redo size
3226404 bytes sent via SQL*Net to client
50932 bytes received via SQL*Net from client
4594 SQL*Net roundtrips to/from client
1 sorts (memory) --只需進行記憶體排序即可
0 sorts (disk) --當sort_area_size=64M時,不需要進行磁碟排序
68888 rows processed
SQL> SET AUTOTRACE OFF --關閉自動追蹤
SQL> SELECT a.name,b.value
2> FROM v$statname a,v$sesstat b
3> WHERE a.statistic#=b.statistic#
4> AND (a.name LIKE 'session%ga memory%%' OR a.name LIKE '%direct temp%')
5> AND sid=(SELECT distinct sid FROM v$mystat);
NAME VALUE
------------------------------------------------------------------ ----------
session uga memory 170876

![Chapter 3 – Oracle Instance
Oracle Database Management Best Practice
3.1.1 自動記憶體管理(Automatic Memory Management)
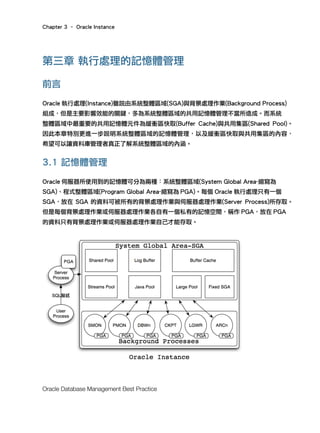
Oracle Database 11g 的自動記憶體管理(Automatic Memory Management-縮寫為 AMM)讓
資料庫管理者只需指定整個 Oracle 伺服器所能使用的最大記憶體空間,不需個別設定 SGA
或 PGA 的大小,之後 Oracle 執行處理自動依 Oracle 伺服器狀態調整 SGA 與 PGA 的大小,
以及 SGA 的其他共用記憶體元件的大小(緩衝區快取、共用集區、大型集區、Java 集區、
Streams 集區)。
當執行處理剛啓動時,SGA 佔記憶體目標的 60%,而 PGA 佔 40%,之後隨著 Oracle 伺服
器狀態,由背景處理作業 Memory Management(MMAN)動態地調整兩者的比率以達到
Oracle 伺服器的最佳效能。資料庫管理者如果想要啓用(Enable)自動記憶體管理機制,可以
藉由設定 MEMORY_MAX_TARGET 與 MEMORY_TARGET 這兩個參數來啟動。需要注意的
事為 MEMORY_TARGET 必須小於 MEMORY_MAX_TARGET。
啟動自動記憶體管理
1.取得 SYSDBA 的權限。
在 SQL*PLUS 環境下執行”SHOW USER”指令,出現的使用者若為 SYS 即表示此階段作
業已經取得 SYSDBA 權限。因為從 Oracle Database 9i 開始,使用者 SYS 只能使用
SYSDBA 或 SYSOPER 身分登入。
[ora11g@elinux5 ~]$ export $ORACLE_SID=ora11g /*設定執行處理的名字*/
[ora11g@elinux5 ~]$ sqlplus / AS SYSDBA /*以OS驗證,取得SYSDBA權限*/
SQL> SHOW USER
USER is “SYS”
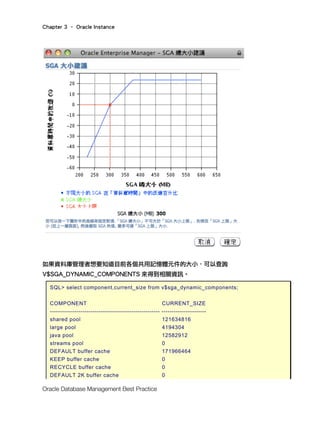
2.是否啓用自動記憶體管理。執行”SHOW PARAMETER target”來查看,若
MEMORY_TARGET 值為 0,表示尚未啓動自動記憶體管理。若 MEMORY_TARGET 值大於
0,則表示已經使用自動記憶體管理。
SQL> SHOW PARAMETER target
NAME TYPE VALUE
------------------------------------------ ---------------- ------------------------------
memory_max_target big integer 0 --記憶體最大目標
memory_target big integer 0 --記憶體目標
pga_aggregate_target big integer 100M --PGA聚總目標](https://image.slidesharecdn.com/bookchapter3-190515023831/85/Oracle-SGA-3-320.jpg)


![Chapter 3 – Oracle Instance
Oracle Database Management Best Practice
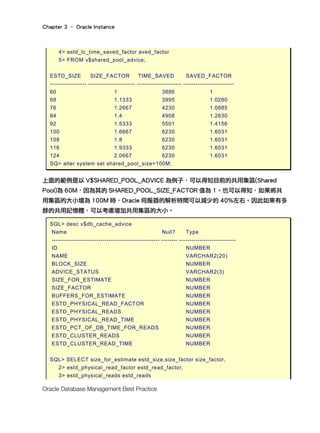
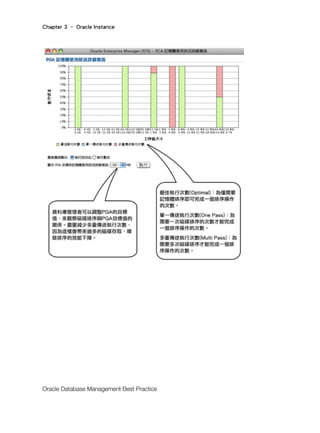
由上面的範例可以看到目前的 MEMORY_TARGET 為 544M,因為
MEMORY_SIZE_FACTOR 為 1。同時可以得知,即使將 MEMORY_TARGET 增加為 816M,
可以減少一些 DB_TIME,但是差距實在太小,以比率而言也只有 0.0017。這時資料庫管理
者便不應該將 SGA_TARGET 設為 816M,因為只有浪費記憶體而已。如果資料庫管理者這
時將 MEMORY_TARGET 設為 272M,DB_TIME 沒有明顯的增加,而 Oracle 伺服器所佔用
的記憶體卻可以大幅下降,而節省下來的記憶體空間可以給作業系統的其他服務使用,這些
其他服務當然也包含其他的 Oracle 伺服器。那麼資料庫管理者何樂不為呢?那為何不選擇
408M 呢?因為 MEMORY_TARGET 設為 408M,得到]DB_TIME 卻與設為 272M 相同,這
樣只有浪費不必要的記憶體,並沒有其他的好處。所以依範例的結果來看,
MEMORY_TARGET 降為 272M 是最好的選擇。](https://image.slidesharecdn.com/bookchapter3-190515023831/85/Oracle-SGA-6-320.jpg)