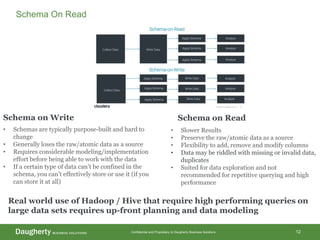
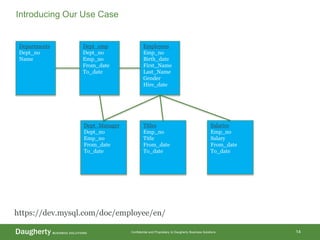
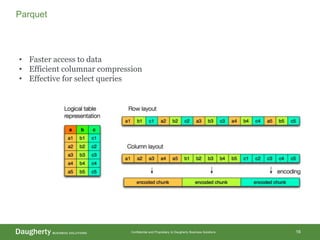
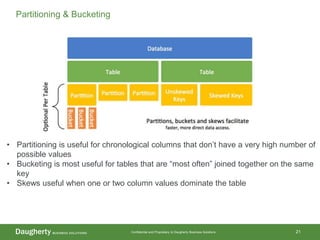
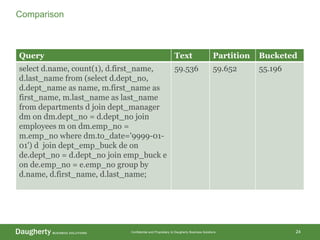
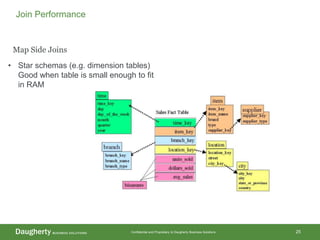
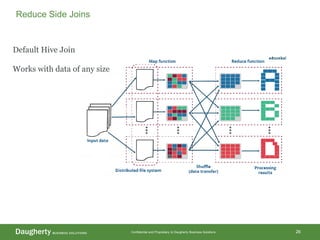
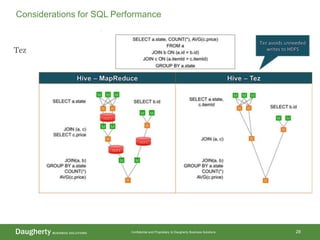
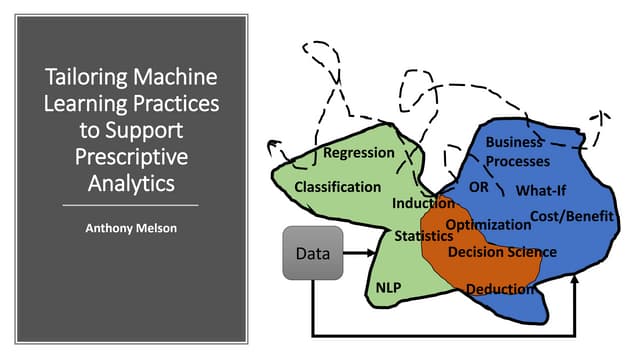
The document discusses Hadoop data modeling, its ecosystem, and the integration of big data technologies such as Spark and cloud-native solutions. It outlines key topics including schema design, data storage considerations, compression formats, and performance optimization techniques for querying data in Hadoop. Additionally, it introduces the St. Louis Big Data Innovation group and emphasizes the role of data engineering and analytics in leveraging big data for business insights.