Büyük Veri Uygulamalarıve Ülkemizden Örnekler,
Güvenlik Analizlerinin Araştırılması
12060382 Hülya Soylu
Akademik Danışman : Doç.Dr Sedat Akleylek
2.
İçerik
1. Büyük Veri(Big Data) Nedir?
2. Büyük Veri (Big Data) Bileşenleri Nelerdir?
3. Büyük Veri'nin Uygulandığı Örnek Alanlar
4. “Big Data” Kullanımına Örnekler
5. Dünyadaki ve Türkiye'deki Büyük Veri (Big Data) Örnek Uygulamaları
6. Big Table(Büyük Tablo)
7. Büyük Veri Teknolojilerinde Beklenen Özellikler
8. Arama Motorunda Big Data'nın Yapay Zeka Sistemleri ile Analizi
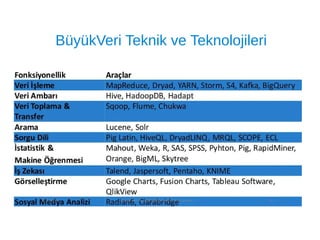
9. Büyük Veri Teknik ve Teknolojileri
10. Hadoop
11. BüyükVeri Teknik ve Teknolojileri
12. NoSQL , MongoDB , Pig,İmpala,
13. Büyük Veri Güvenlik Çözümleri
4.
Büyük Veri
➔ BigData ; şirketlerin büyük veri yığınlarıyla ve verilerin depolanmasıyla
baş etmek için gereksinim duydukları teknolojik araçlar ve süreçlerdir.
[1]
5.
● Büyük veri;Yapılandırılmış (structured) ve Yapılandırılmamış
(unstructured) verilerden meydana gelir.
● Yapılandırılmış veriler: ürün, kategori, müşteri,
fatura, ödeme...
● Yapılandırılmamış veriler: tweet, paylaşım, beğeni
(like), e-posta, video, tıklama...
● Büyük verimiktarları teranyte, petabyte, exabyte, belki zettabyte
seviyesinde bile olabilir.
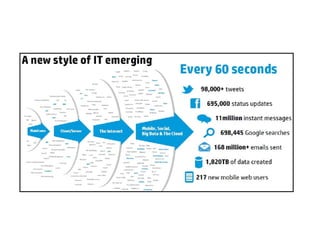
● 2000 yılında tüm dünyada 800,000 petabyte büyüklüğünde veri
saklandı. 2020 yılında bu verinin 35 zetabyte olacağı tahmin ediliyor.
● Örneğin Twitter her gün 7 TB, Facebook 10 TB ve bazı kurumlar her
gün her saat TB’larca veri saklıyor.
8.
Big Data etkinbir şekilde verileri analiz edip işlemek için:
➔ A/B testleri
➔ yapay zeka sistemleri
➔ dil işleme süreçleri
➔ gelişmiş simülasyon
gibi olağanüstü teknolojilere ihtiyaç duymaktadır.
Büyük Veri Bileşenleri
➔
Büyükveri kavramını daha iyi anlamak için 5V şeklinde adlandırılan
bileşenlerini inceleyelim:
➔
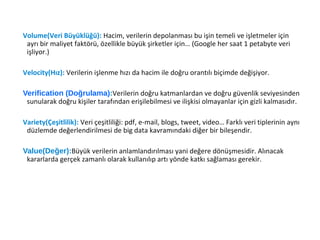
Volume(Veri Büyüklüğü)
➔
Velocity(Hız)
➔
Verification(Doğrulama)
➔
Variety(Çeşitlilik)
➔
Value(Değer)
12.
Volume(Veri Büyüklüğü): Hacim,verilerin depolanması bu işin temeli ve işletmeler için
ayrı bir maliyet faktörü, özellikle büyük şirketler için… (Google her saat 1 petabyte veri
işliyor.)
Velocity(Hız): Verilerin işlenme hızı da hacim ile doğru orantılı biçimde değişiyor.
Verification (Doğrulama):Verilerin doğru katmanlardan ve doğru güvenlik seviyesinden
sunularak doğru kişiler tarafından erişilebilmesi ve ilişkisi olmayanlar için gizli kalmasıdır.
Variety(Çeşitlilik): Veri çeşitliliği: pdf, e-mail, blogs, tweet, video… Farklı veri tiplerinin aynı
düzlemde değerlendirilmesi de big data kavramındaki diğer bir bileşendir.
Value(Değer):Büyük verilerin anlamlandırılması yani değere dönüşmesidir. Alınacak
kararlarda gerçek zamanlı olarak kullanılıp artı yönde katkı sağlaması gerekir.
13.
Dünyada Kamu BüyükVeri
Uygulamaları
● Trafik Yoğunluğu Takibi
Projesi
Sektör: Ulaştırma
Hollanda'da.
● Sosyal Medya Analizi
Sektör: İletişim
Hollanda'da.
● Akıllı Şebeke Analizi
Sektör: Enerji
Tennessee Valley
Authority
● Proje: Prematüre
Bebek Takibi
Sektör: Sağlık
Ontario Üniversitesi
14.
● Görüntüleme Tanı
HatalarınınAzaltılması
Sektör: Sağlık
Asya Sağlık Bürosu
● Suç Önleme Projesi
Sektör: Güvenlik
New York
● Önleyici Polis
Hizmetleri
Sektör: Güvenlik
Amerika
● Su Kaynaklarının
Takibi
Sektör: Çevre
Beacon Enstitüsü
15.
Türkiye'de Kamu BüyükVeri
Uygulamaları
● Şu an için aktif olarak büyük veri üzerine kurgulanmış bir
Kamu Projesi bulunmamaktadır.
16.
“Big Data” KullanımınaÖrnekler
●
Amazon fiyat sorgulama uygulaması, barkod okuma ve en ucuz fiyatı arama
özelliği olan uygulamayı 2011 sonu kullanıcılara sundu.,
●
NASA İklim Simülasyon Merkezi 32 petabytelık iklim verisi biriktirmiş ve süper
bilgisayarlarla iklim değişikliğinin simülasyonunu yapmaktadır.
●
Facebook veri tabanında 50 milyar kadar fotoğraf bulunmaktadır. Aynı şekilde 1.15 milyar
sosyal medyada veri oluşturan aktif kullanıcısı vardır.
●
Her gün 5 milyar insan arama, mesajlaşma, internette sörf gibi yollarla veri üretmektedir.
●
2012 yılında Obama’nın yeniden seçilmesi için yaptığı kampanyada Big Data analizleri
sonucu elde ettiği verileri kullanmış ve yeniden seçilmiştir
17.
●
Sosyal medya akışınınanaliz edilmesi;
Sosyal medyada dokunulan kişiler hakkında bilgi toplama, doğru
mesajıdoğru müşteriye doğru zamanda iletebilme yönetimi için
kullanılıyor.
●
Fraud;
Devletler ve bankalar kötüye kullanım durumlarının tespiti için
kullanıyorlar.
●
Arama motorları;
Etiketleme işlemiyle arama motorlarında çıkan firmalar bu sayede
detaylı raporlama alarak takip etmek, sonrasında iletişime geçmek
mümkün.
18.
●
Telekom ve iletişimkullanımı;
Mobil telefon kullanımı ile ilgili bir çok veri kullanıcı bazında tutuluyor;
iş geliştirme ve analiz kapsamında kullanılıyor.
●
Güvenlik ve Ceza hukuku uygulamaları;
➔
Bulut bilişim sistemine atanan platform ile tüm hukuki süreç
depolanacak ve suçlu entegre sistemler sayesinde takip edilecek.
➔
Güvenlik platform’u web üzerindeki tüm görselleri inceleyerek, suçluya
benzeyen fotoğraflardan dijital takip sürebilecek.
Dünyadaki ve Türkiye'dekiBüyük Veri (Big
Data) Örnek Uygulamaları
➔
Google ihtiyacı olan bu teknolojiyi ilk kendisi geliştirdi.
➔
Milyarlarca internet sayfasının verisini Google File System
üzerinde tutuyor.
➔
Veritabanı olarak Big Table(Büyük Tablo) kullanıyor.
➔
Büyük veriyi işlemek için MapReduce kullanıyor.
22.
Big Table(Büyük Tablo)
●
Googletarafından geliştirilen ve arama motoru tasarımında kullanılanılır.
●
Amaç web sayfalarının daha başarılı bir şekilde;
➔
Depolanması (Storing)
➔
Bulunması (Finding)
➔
Güncellenmesi (updating)
●
Google’ın konuya yaklaşımı, ucuz bilgisayarlar tarafından yüksek
miktarda verinin tutulması ve işlenmesi yönündedir.
23.
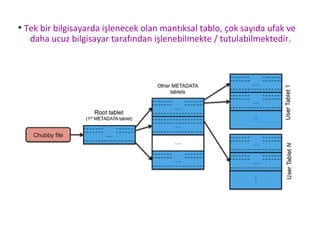
●
Tek bir bilgisayardaişlenecek olan mantıksal tablo, çok sayıda ufak ve
daha ucuz bilgisayar tarafından işlenebilmekte / tutulabilmektedir.
24.
Büyük tablo yaklaşımındaveriler;
➔ Herhangi bir büyük tablo kayıdında, sitenin adresi, sitenin metin kısmı,
sitede bulunan bağlantılar (link, anchor, çapa) ve sitenin başlığı
tutulmaktadır.
25.
Büyük Tablo KullanımınınAvantajları
●
Özel bir sorgulama diline (query language) ihtiyaç duyulmaz ve
dolayısıyla sorgulama dilinin iyileştirilmesi (query optimisation) gibi
özel adımlara gerek yoktur.
●
Sadece satır seviyesinde işlemler gerçekleştirilir. Yani ilişkisel veritabanı
(relational database) tasarımında olduğu üzere, tablolar arasında
birleştirme (join)gibi işlemlere gerek yoktur.
●
Tabletler, bütün büyük tablo (big table) sisteminde bulunan sunucular
tarafından erişilebilir durumda tutulurlar.
26.
●
Ayrıca yapılan herişlem ilave bir işlem kütüğünde (transaction log)
tutulur ve bu kütüğe bütün sunucular erişebilir.
●
Sunuculardan birisinin bozulması durumunda, diğer sunuculardan birisi
bu işlem kütüğüne erişerek bozulan sunucunun görevini üstlenebilir.
●
Satır bazında bir limit yoktur. Yani her kayıt için sınırsız sayıda bağlantı
tutulması gerekebilir.
27.
Büyük Tablo'da KarşılaşılabilecekProblemler
●
Aynı kaydın birden fazla geçmesi
●
Aynı içeriğin internet üzerinde içerik hırsızları tarafından kopyalanması
●
Aynı içeriğin bir kısmının aynı kaldığı yeni sürümlerinin çıkması
●
Çoklu gönderiler (spam, mass message)
●
Aynı içeriğin birden fazla divan (forum) veya tartışma sitelerinde
bulunması
28.
Bu problemin çözümüiçin tekrarların bulunması
gerekir.Tekrar bulma işlemi iki seviyede yapılabilir;
➔
Birincisi tam tekrarın bulunmasıdır ki buradaki amaç, birebir kopyalanan
içerikleri eşleştirmektir.
➔
İkincisi benzerliklerin bulunması ve belirli bir benzerlik seviyesinin
üzerinde olan içeriklerin eşleştirilmesidir.
29.
●
Tam benzerliğin bulunmasıiçin toplam kontrolü (checksum) yöntemleri
kullanılır. Örneğin CRC (cyclic redundancy check) ve benzer
algoritmalar ile sayfaların toplam kontrolü yapılır ve eşleştirilir.
●
Benzer sitelerin bulunması için de geliştirilmiş algoritmalar vardır.
Örneğin SimHash algoritması (benzerlik özeti) google tarafından da
kullanılmaktadır.
30.
●
Amazon verilerini DynamoDBüzerinde tutuyor.
●
Facebook, Twitter, Linkedin gibi firmalar dev veri için
geliştirdikleri projeleri açık kaynaklı olarak yayınlıyorlar.
●
Açık kaynak olarak yayınlanan örnek projeler;
➔
Cassandra
➔
Hive
➔
Pig
➔
Voldemort
➔
Storm
➔
IndexTank
GittiGidiyor’da Büyük Veri
➔
Pazarlama
Detaylıkullanıcı profilleri
Hedef kitle belirleme
➔
Segmentasyon
Alışveriş geçmişi
Ziyaret geçmişi
➔
Raporlama
Veriambarı, Analitik Verileri, A/B Testleri
Özel raporlar
Büyük Veri TeknolojilerindeBeklenen
Özellikler
●
Esnek
➔
Her türlü veriyi işleyebilmeli
●
Ölçeklenebilir
➔
İhtiyaca göre genişleyebilmeli
●
Veri Garantili
➔
Veriler yedekli ve erişilebilir olmalı
●
Düşük Maliyetli
➔
Açık kaynaklı projeler
36.
Arama Motorunda BigData'nın Yapay Zeka
Sistemleri ile Analizi
●
Sınıflandırma (Classification)
Hatalı kategorilerin tespiti
Dolandırıcılıkla mücadele
Duygu analizi
●
Kümeleme (Clustering)
Kullanıcıların kümelenmesi
Ürünlerin gruplanması
●
Öneri sistemleri (Recommendation)
İçerik tabanlı
Kullanıcı / Ürün tabanlı
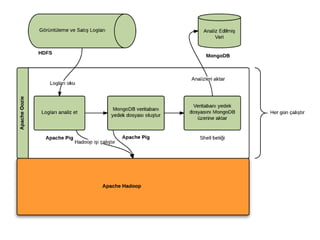
Hadoop
➔
Açık kaynak kodlu(opensource), dağıtık(distributed),
ölçeklenebilir(scalable),hata dayanıklı(fault tolerant) Apache projesidir.
➔
Map-Reduce işlemlerini hedef almaktadır.
➔
Büyük ölçekteki işlemleri ve hesaplamaları hedefler(very lage database
(VLDB)).
➔
Büyük Veri (Big Data) dünyasında düşük maliyetli ve verimli çözümler
üretir.
39.
Hadoop Tarihçesi
●
Çıkış Amacı: “Kabul edilebilir zaman ve maliyetle nasıl büyük veri
üzerinde işlem yapılabilir?” sorusuna cevap bulmaktır.
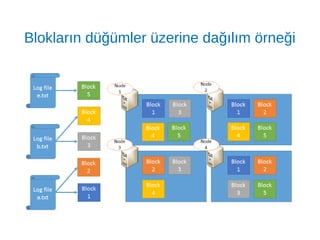
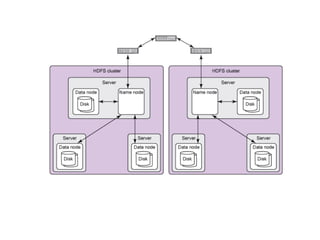
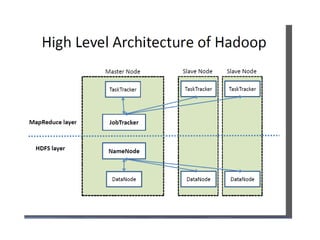
Hadoop Distributed FileSystem (HDFS)
➔
Büyük miktardaki veriye yüksek iş/zaman oranı (throughput) ile erişim
sağlayan Dağıtık Dosya Yönetim Sistemidir.
➔
Veriyi 64MB ya da 128MB'lık bloklar halinde saklar.
➔
Her blok küme içerisinde farklı düğümlere dağıtılır.
➔
Her bloğun varsayılan 3 kopyası tutulur böylece RAID benzeri bir yapıyla
yedeklenir.
➔
Bu sayede verinin erişilebilirliği ve güvenilirliği
sağlanmış olur.
➔
Aynı dosyaya ait bloklar farklı düğümlerde olabilir.
➔
Ayrıca HDFS çokbüyük boyutlu dosyalar üzerinde okuma işlemi
(streaming) imkanı sağlar, ancak rastlantısal erişim (random access)
özelliği bulunmaz.
➔
HDFS, NameNode ve DataNode süreçlerinden (process) oluşmaktadır.
44.
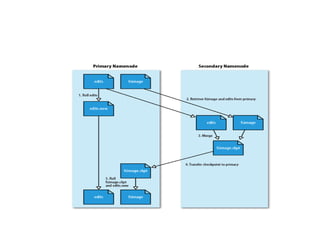
NameNode
●
NameNode ana (master)süreç olarak blokların sunucular
üzerindeki;dağılımınından,yaratılmasından,silinmesinden bir blokta
sorun meydana geldiğinde yeniden oluşturulmasından her türlü dosya
erişiminden sorumludur.
●
Kısacası HDFS üzerindeki tüm dosyalar hakkındaki bilgiler (metadata)
NameNode tarafından saklanır ve yönetilir.
●
Her kümede yalnızca bir adet NameNode olabilir.
46.
DataNode
●
DataNode ise işleviblokları saklamak olan slave (köle) süreçtir.
●
Her DataNode kendi yerel diskindeki veriden sorumludur.
●
Ayrıca diğer DataNode’lardaki verilerin yedeklerini de barındırır.
●
DataNode’lar küme içerisinde birden fazla olabilir.
49.
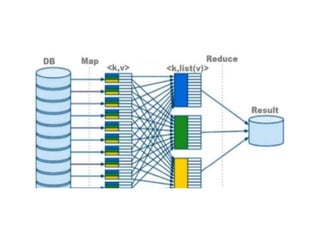
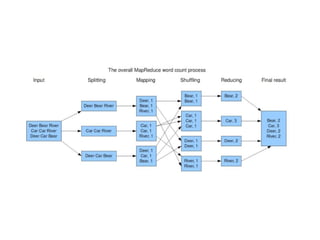
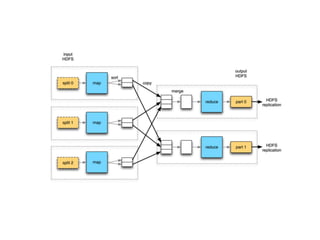
Hadoop MapReduce
●
HDFS üzerindekibüyük dosyaları verileri işleyebilmek amacıyla kullanılan
yöntemdir.
●
Map fonksiyonu ile veri içerisinden istenilen veriler anahtar-değer
formatında seçilir.
●
Reduce fonksiyonu ile de seçilen bu veriler üzerinde işlem yapılır , sonuç
yine anahtar-değer olarak iletilir.
51.
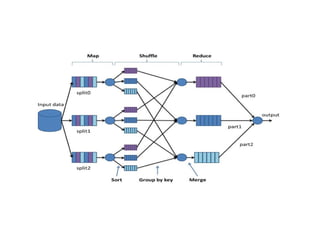
➔ Map veReduce arasında Shuffle ve Sort aşamaları vardır.
➔ Benzetme yapılırsa;
➔ WHERE ile yapılan filtreleme gibi Map aşamasında
sadece ihtiyacımız olan veriler seçilir.
➔ Reduce aşamasında ise SUM, COUNT, AVG gibi
birleştirme işlemleri yapılır
54.
➔Hadoop’un gücü;
İşlenen dosyalarınher zaman ilgili düğümün (node) yerel
diskinden okunması ağ trafiğini meşkul etmemesi birden
fazla işi aynı anda işleyerek doğrusal olarak
ölçeklenmesinden geliyor.
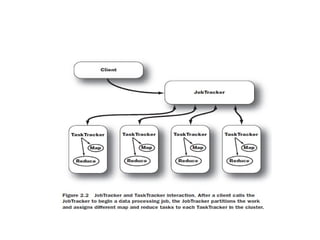
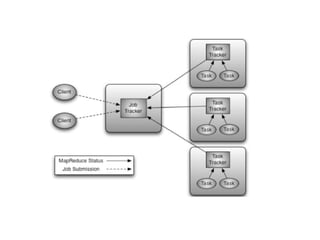
JobTracker
●
JobTracker yazılan MapReduceprogramının küme üzerinde dağıtılarak
çalıştırılmasından sorumludur.
●
Ayrıca dağıtılan iş parçacıklarının çalışması sırasında oluşabilecek
herhangi bir problemde;
●
O iş parçacığının sonlandırılması ya da yeniden başlatılması da
JobTracker’ın sorumluluğundadır.
60.
TaskTracker
➔
TaskTracker, DataNode’ların bulunduğusunucularda çalışır.
➔
JobTracker’dan tamamlanmak üzere iş parçacığı talep eder.
➔
JobTracker, NameNode’un yardımıyla DataNode’un lokal diskindeki
veriye göre en uygun Map işini TaskTracker’a verir.
➔
Bu şekilde verilen iş parçacıkları tamamlanır .
➔
Sonuç çıktısı yine HDFS üzerinde bir dosya olarak yazılırak program
sonlanır.
62.
MongoDB
● NoSQL veritabanı
çözümlerindenbir
tanesi.
● Açık kaynak.
● MongoDB doküman
bazlı bir veritabanıdır.
● Büyük miktardaki
veriye hızlı bir şekilde
erişmeye olanak
sağlar.
64.
Pig
● Yahoo tarafındangeliştirilmiştir.
● MapReduce yazmak için "DataFlow" dili olarak
adlandırılan, SQL'den farklı kendine özgü PigLatin
dili kullanılır.
● Join destekler, daha kolay ve performanslı
MapReduce programaları yazmayı sağlar.
65.
Hive
● Facebook tarafındangeliştirilmiştir.
● SQL benzeri HiveQL dili ile Java kullanmadan
MapReduce uygulamaları yazılmasını sağlar.
● Öncelikle HDFS üzerindeki dosyalar tablo
olarak tanıtılır.
● Daha sonra bu sanal tablolar sorgulanabilir.
66.
İmpala
● Google Dremel(2010) projesinden
esinlenmiştir.
● Cloudera tarafından geliştirilmiştir.
● MapReduce yapmadan verilere direkt erişir.
● HiveQL destekler, 7-45 kat daha hızlı çalışır.
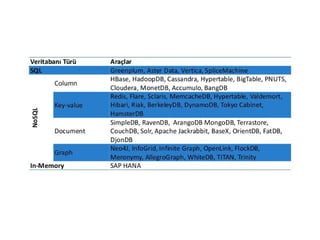
HadoopDatabase(HBase)
●
Hadoop üzerinde çalışanNoSQL veritabanıdır
●
Google Big Table örnek alınarak geliştirilmiştir
●
Esnek şema yapısı ile binlerce kolon, petabyte'larca satırdan oluşan
veriyi saklayabilir.
●
HDFS üzerinde çalıştığından MapReduce destekler.
70.
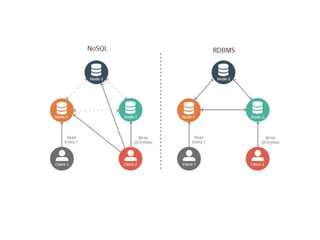
NoSQL
➔
NoSQL veritabanları;büyük verilerinhızlı işlenmesi ve
ölçeklendirilmesi (scalability) amacıyla geliştirilmiş
sistemlerdir.
➔
Big Table ve DynamoDB yıllardır Google ve Amazon
tarafından kullanılan NoSQL sistemlerdir.
NoSql Avantajları
➔
Yüksek erişilebilirlik
➔
Okumave yazma performansı
➔
Yatay olarak genişletilebilirlik
➔
Binlerce sunucu birarada çalışabilir
➔
Çok büyük veri üzerinde işlem yapabilirler.
➔
Programlama ve bakımı kolay
➔
Maliyet açısından avantajlı
➔
Kullanımı kolay ve esnek nesne yönelimli programlama.
74.
NoSql Dezavantajları
➔
Veri güvenliğikonusunda da RDBMS’ler kadar gelişmiş özelliklere henüz sahip değiller.
➔
RDBMS sistemlerini kullanan uygulamaların NoSQL sistemlere taşınması zordur.
➔
RDBMS sistemlerinin NoSQL sistemlere taşınması sırasında veri kaybı sözkonusu olabilir.
➔
İlişkisel veritabanı yönetim sistemlerindeki işlem hareketleri (transaction) kavramı,
NoSQL veritabanı sistemlerinde bulunmadığı için veri kaybı söz konusu olabilmektedir.
➔
İlişkisel veritabanı yönetim sistemlerindeki sorgu tabanlı veri erişimi yerine NoSQL
sistemlerdeki anahtar tabanlı veri erişimi sağlamak gerekmektedir.
77.
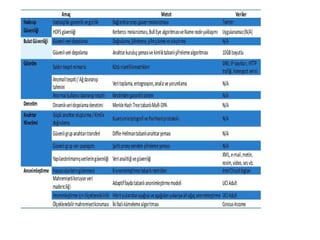
Büyük Veri GüvenlikÇözümleri
Apache Sentry kullanarak hadoop ekosistemin de rol bazlı
yetkilendirme ile pekçok Büyük Veri aracı arasında güvenli
iletişim sağlanabilir.
78.
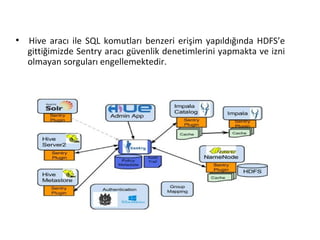
●
Hive aracı ileSQL komutları benzeri erişim yapıldığında HDFS’e
gittiğimizde Sentry aracı güvenlik denetimlerini yapmakta ve izni
olmayan sorguları engellemektedir.
80.
KAYNAKLAR
●● [1]Ayhan Önder,BigData CTP
● [2]Big Data Security- Joey Echeverria
● [3]Kamuda Büyük Veri ve Uygulamaları- Doç.Dr.İzzet Gökhan
ÖZBİLGİN
● [4]Büyük Veri Analitiği ve Güvenliği- Prof.Dr. Şeref SAĞIROĞLU
● [5]devveri.com




![Büyük Veri
➔ Big Data ; şirketlerin büyük veri yığınlarıyla ve verilerin depolanmasıyla
baş etmek için gereksinim duydukları teknolojik araçlar ve süreçlerdir.
[1]](https://image.slidesharecdn.com/bykveribigdata-160524171801/85/Buyuk-veri-bigdata-4-320.jpg)




















































![KAYNAKLAR
●● [1]Ayhan Önder, BigData CTP
● [2]Big Data Security- Joey Echeverria
● [3]Kamuda Büyük Veri ve Uygulamaları- Doç.Dr.İzzet Gökhan
ÖZBİLGİN
● [4]Büyük Veri Analitiği ve Güvenliği- Prof.Dr. Şeref SAĞIROĞLU
● [5]devveri.com](https://image.slidesharecdn.com/bykveribigdata-160524171801/85/Buyuk-veri-bigdata-80-320.jpg)



































































