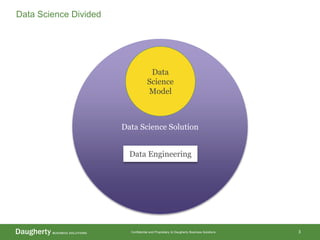
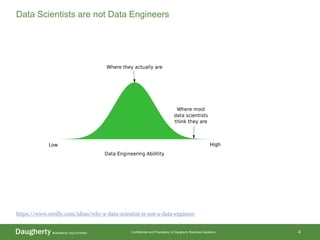
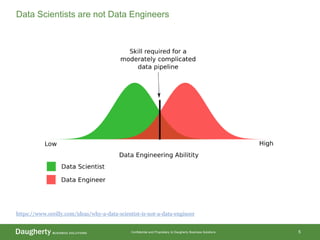
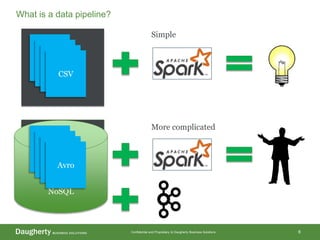
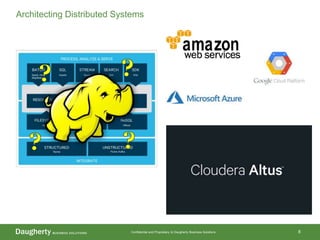
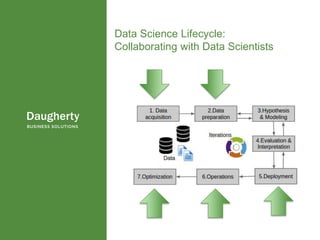
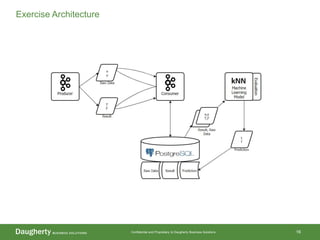
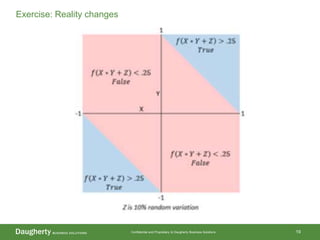
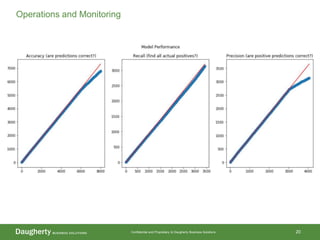
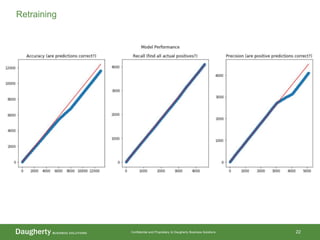
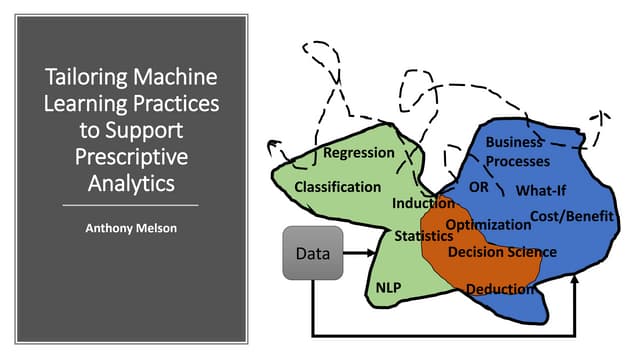
The document discusses the distinctions between data scientists and data engineers, emphasizing that data scientists require support from data engineers to create reliable data pipelines. It outlines the data science lifecycle, including steps such as hypothesis formation, model training, evaluation, and retraining to adjust for model drift. The content also highlights the importance of architecture in data storage and processing to ensure systems are robust and performant.