Download as PDF, PPTX





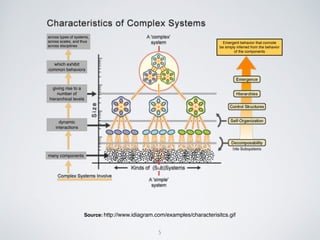





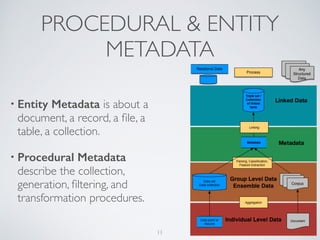
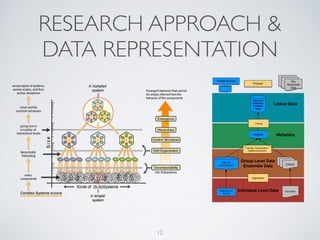
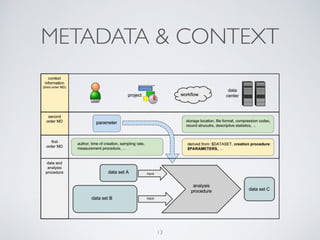
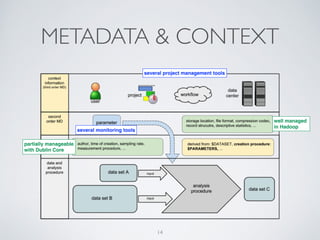




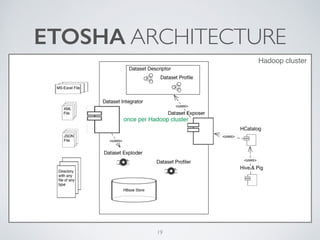
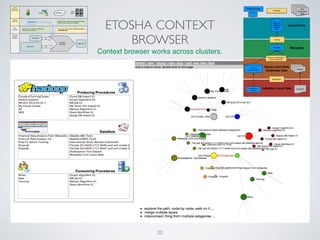



(1) The document discusses challenges of managing large and complex datasets for interdisciplinary research projects. It presents Hadoop and the Etosha data catalog as solutions. (2) Etosha aims to publish and link metadata about datasets to enable discovery and sharing across distributed research clusters. It focuses on descriptive, structural and administrative metadata rather than just technical metadata. (3) Etosha's architecture includes a distributed metadata service and context browser that can query metadata from different Hadoop clusters to support federated querying and subquery delegation.
















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)






