Download as PDF, PPTX








![14 | © Copyright Zilliz
14
Semantic Similarity
Image from Sutor et al
Woman = [0.3, 0.4]
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Woman = [0.3, 0.4]
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Man = [0.5, 0.2]
Queen - Woman + Man = King
Queen = [0.3, 0.9]
- Woman = [0.3, 0.4]
[0.0, 0.5]
+ Man = [0.5, 0.2]
King = [0.5, 0.7]
Man = [0.5, 0.2]](https://image.slidesharecdn.com/06-20-2024-aicampmeetup-unstructureddataandvectordatabases-240620160248-1964efbc/85/06-20-2024-AI-Camp-Meetup-Unstructured-Data-and-Vector-Databases-14-320.jpg)
![15 | © Copyright Zilliz
15
Vector Similarity Measures: L2 (Euclidean)
Queen = [0.3, 0.9]
King = [0.5, 0.7]
d(Queen, King) = √(0.3-0.5)2
+ (0.9-0.7)2
= √(0.2)2
+ (0.2)2
= √0.04 + 0.04
= √0.08 ≅ 0.28](https://image.slidesharecdn.com/06-20-2024-aicampmeetup-unstructureddataandvectordatabases-240620160248-1964efbc/85/06-20-2024-AI-Camp-Meetup-Unstructured-Data-and-Vector-Databases-15-320.jpg)
![16 | © Copyright Zilliz
16
Vector Similarity Measures: Inner Product (IP)
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Queen · King = (0.3*0.5) + (0.9*0.7)
= 0.15 + 0.63 = 0.78](https://image.slidesharecdn.com/06-20-2024-aicampmeetup-unstructureddataandvectordatabases-240620160248-1964efbc/85/06-20-2024-AI-Camp-Meetup-Unstructured-Data-and-Vector-Databases-16-320.jpg)
![17 | © Copyright Zilliz
17
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Vector Similarity Measures: Cosine
𝚹
cos(Queen, King) = (0.3*0.5)+(0.9*0.7)
√0.32
+0.92
* √0.52
+0.72
= 0.15+0.63 _
√0.9 * √0.74
= 0.78 _
√0.666
≅ 0.03](https://image.slidesharecdn.com/06-20-2024-aicampmeetup-unstructureddataandvectordatabases-240620160248-1964efbc/85/06-20-2024-AI-Camp-Meetup-Unstructured-Data-and-Vector-Databases-17-320.jpg)




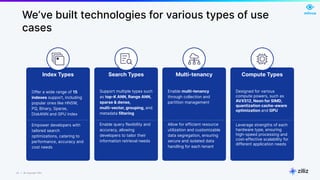
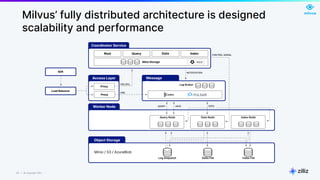
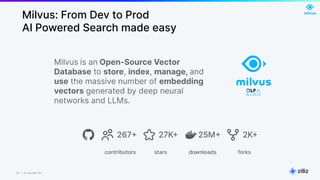
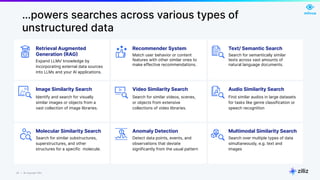
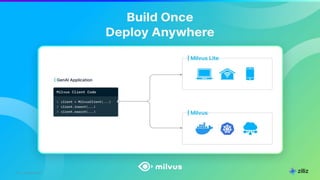
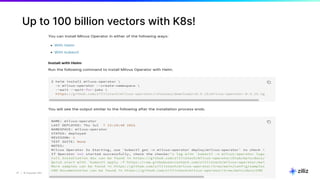






















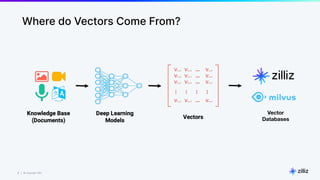
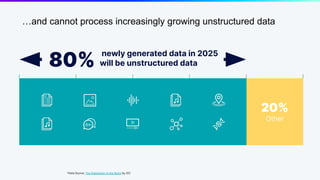
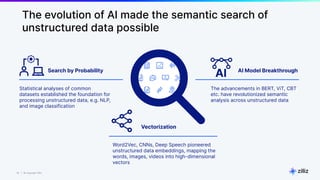
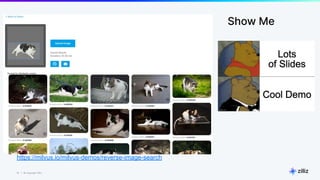
The document discusses unstructured data and the role of vector databases, specifically Milvus, in processing it effectively. It highlights the limitations of traditional databases in handling unstructured data and presents Milvus as a scalable solution optimized for high-performance vector embedding storage and querying. The content also covers various use cases, advancements in AI, and the unique architecture of Milvus that enhances its operational capabilities.























































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)