Download as PDF, PPTX





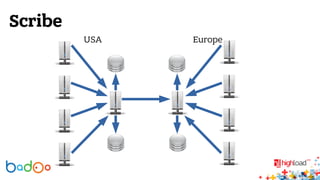
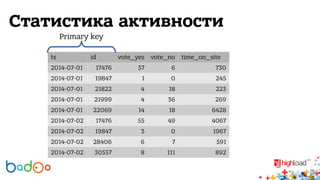





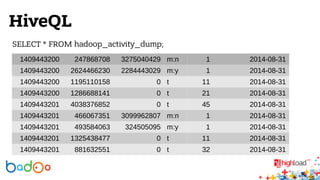


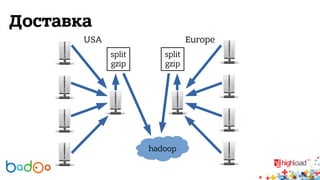

















В докладе Валерия Старинина обсуждается использование Hadoop в компании Badoo для распределенного хранения и обработки статистики от 226 миллионов пользователей. Основное внимание уделено тому, как Hadoop упрощает анализ данных и упрощает хранение событий активности пользователей. Также рассматриваются проблемы с масштабированием базы данных и планы на будущее, включая улучшение технологий и мониторинг серверов.



































































