Download as PDF, PPTX




















![gevent
def
print_head(url):
print('Starting
%s'
%
url)
data
=
urlopen(url).read()
print('%s:
%s
bytes:
%r'
%
(url,
len(data),
data[:50]))
jobs
=
[gevent.spawn(print_head,
url)
for
url
in
urls]
gevent.wait(jobs)](https://image.slidesharecdn.com/hrrirmxgrgm4ofx3ft7a-signature-7134faf9f05d0ef5212b275a81430256dd086c86b6aea38660bb833736495c3a-poli-141103032512-conversion-gate01/85/HighLoad-2014-26-320.jpg)



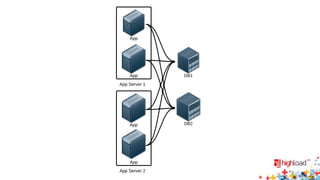
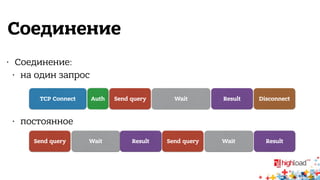
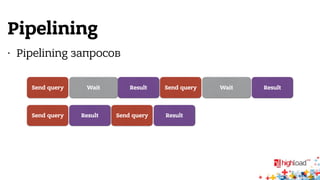
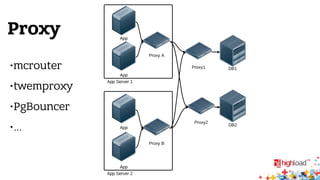












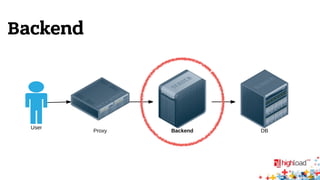
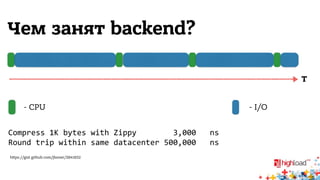
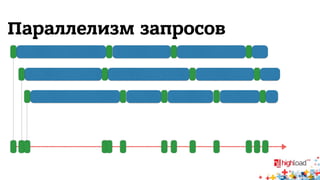
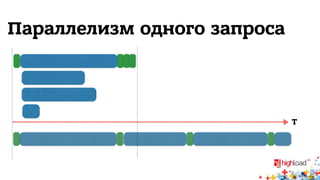
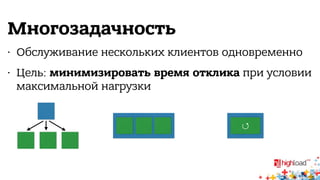
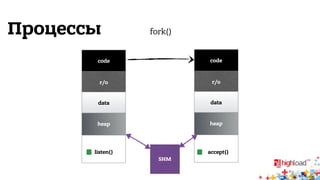
Документ описывает внутреннюю структуру и функции веб-сервиса 2.0, focusing on backend processes, включая обработку входящих запросов, различные методы многозадачности и оптимизации производительности. Он также обсуждает важность асинхронного ввода-вывода и предоставляет примеры реализации в популярных языках программирования, таких как JavaScript, PHP и Python. В завершение документ подчеркивает сложность современной архитектуры backend через сервис-ориентированные модели.



























































