Download as PDF, PPTX










































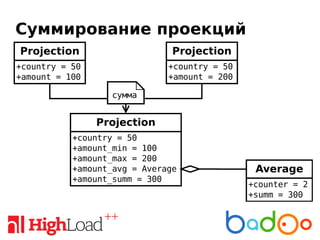















Документ обсуждает near-realtime аналитику событий на платформе Badoo, охватывая технические метрики, сбор данных, проблемы с разнородными событиями и инструменты для их обработки. В качестве решения предлагается unified data stream (uds) и использование Apache Spark для эффективной обработки и агрегации данных. Кроме того, подчеркивается важность инновационных подходов и простых инструментов для решения сложных аналитических задач.





















































