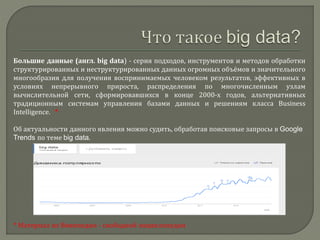
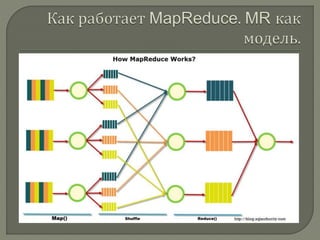
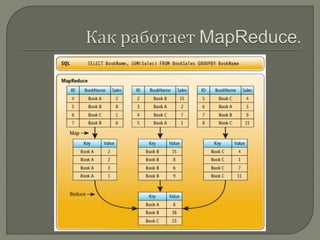
Документ представляет обширное введение в понятие больших данных (big data) и технологии их обработки, включая принципы работы с NoSQL базами данных и модель MapReduce, разработанную Google. Он описывает ключевые аспекты масштабируемости, отказоустойчивости и локальности данных, а также различия между традиционными реляционными базами данных и NoSQL системами. Основные компоненты обработки больших данных и различные типы хранилищ данных подчеркивают значимость технологий для анализа и хранения больших объемов информации.





















![В качестве значений в JSON используются структуры:
Объект - это неупорядоченное множество пар ключ:значение, заключённое в фигурные
скобки «{ }». Ключ описывается строкой, между ним и значением стоит символ «:». Пары
ключ-значение отделяются друг от друга запятыми.
Массив (одномерный) - это упорядоченное множество значений. Массив заключается в
квадратные скобки «[ ]». Значения разделяются запятыми.
Значение может быть строкой в двойных кавычках, числом, объектом, массивом, одним из
литералов: true, false или null.
Строка - это упорядоченное множество из нуля или более символов юникода, заключенное в
двойные кавычки. Символы могут быть указаны с использованием последовательностей,
начинающихся с обратной косой черты «».
JSON XML](https://image.slidesharecdn.com/random-151216065951/85/DBD-lection-4-Big-Data-NoSQL-In-Russian-25-320.jpg)