Download to read offline














![bigdf - details
- open source since Sep 2014
- precedes Spark DataFrame, so built on spark-core
engine
- experimenting with Catalyst using Spark DataFrame
APIs, looks promising
- python and scala APIs
- feature engineering library [not open source :-( ]
- fast CSV reader(and other features) contributed to
spark-csv](https://image.slidesharecdn.com/hadoopatayasdi-150811021234-lva1-app6891/85/Hadoop-at-ayasdi-16-320.jpg)



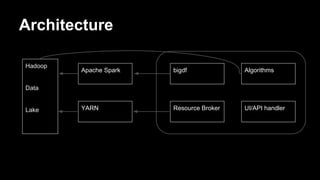
The document provides an overview of Ayasdi's use of Hadoop, highlighting HDFS for storage, YARN for integration, and Parquet as the file format. It discusses the challenges and motivations behind using these technologies, the development of the BigDF framework for feature engineering, and its future direction. Additionally, it addresses the audience's background and experiences with big data tools during an interactive poll.











































































