Downloaded 16 times









![Dataframe benefits
• Lazy evaluation
• Domain specific language for distributed data manipulation
• Automatic parallelization and cluster distribution
• Integration with pipeline API for Mllib
• Query structured data with SQL (using SQLContext)
• Integration with Pandas Dataframes (and other Python data libraries)
from pyspark.sql import SQLContext
sqlContext = SQLContext(sc)
df = sqlContext.read.json("data.json")
df.show()
df.select(“id”).show()
df.filter(df[”id”] > 10).show()
from pyspark.sql import SQLContext
sqlContext = SQLContext(sc)
df = sqlContext.read.json("data.json")
df.registerTempTable(“data”)
results = sqlContext.sql(“SELECT * FROM data WHERE id > 10”)](https://image.slidesharecdn.com/meetup-bigdataalatiupraksi-151224135433/85/Big-Data-tools-in-practice-18-320.jpg)
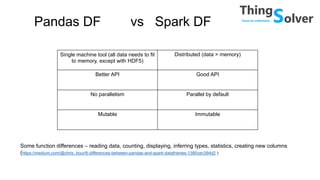
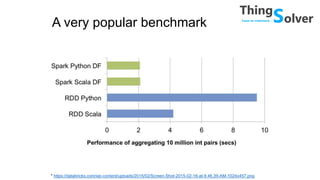


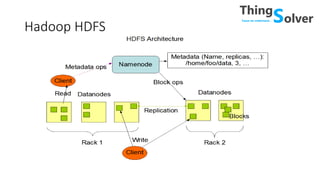
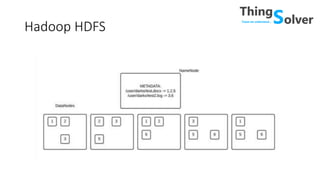
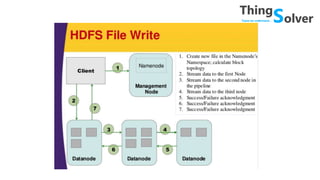
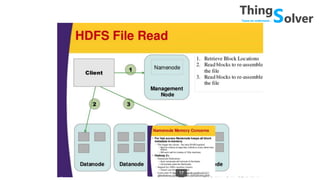
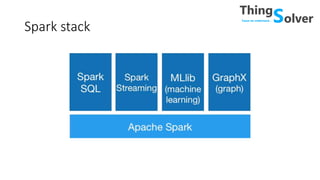
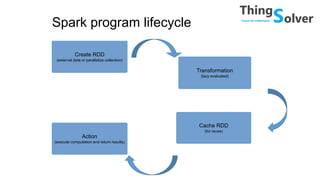
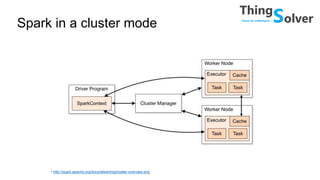
The document discusses and compares popular big data tools Hadoop, Spark, and PySpark. It provides overviews of the pros and cons of Hadoop and Spark, describing Hadoop as providing linear scalability on commodity hardware for distributed processing of large data sets, while Spark is 100x faster using in-memory computation. It also summarizes Resilient Distributed Datasets (RDDs), Spark's programming model, and how Spark and PySpark can be used with DataFrames and SQL for structured data processing.












































































