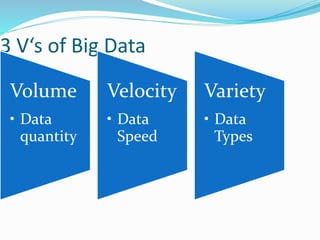
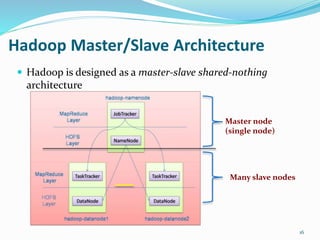
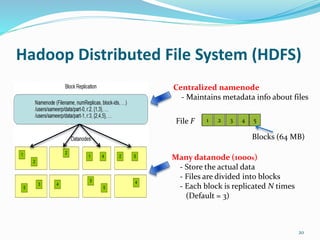
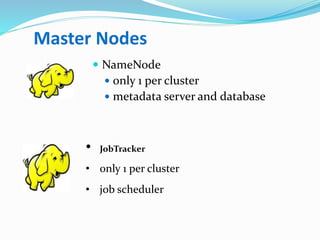
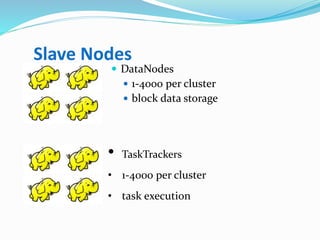
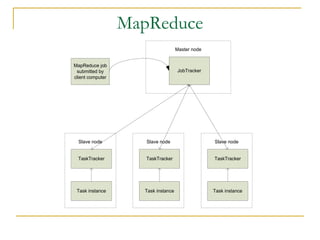
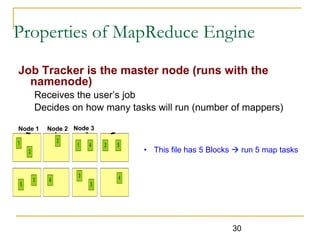
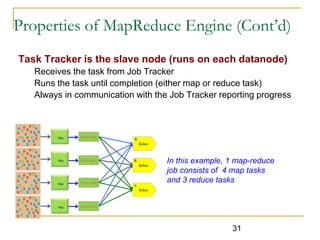
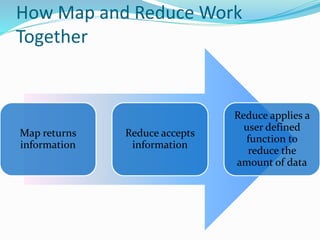
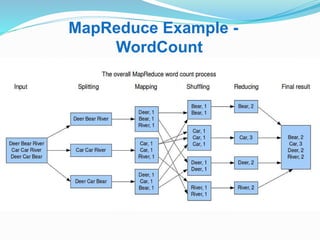
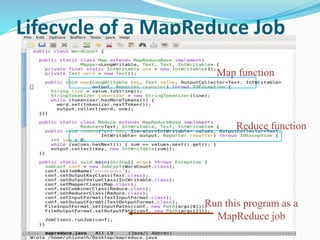
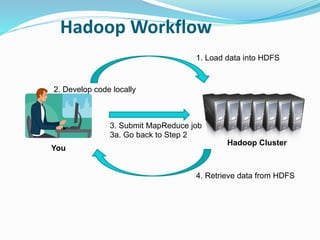
Hadoop is an open-source framework that allows for the distributed processing of large data sets across clusters of computers. It addresses problems like massive data storage needs and scalable processing of large datasets. Hadoop uses the Hadoop Distributed File System (HDFS) for storage and MapReduce as its processing engine. HDFS stores data reliably across commodity hardware and MapReduce provides a programming model for distributed computing of large datasets.