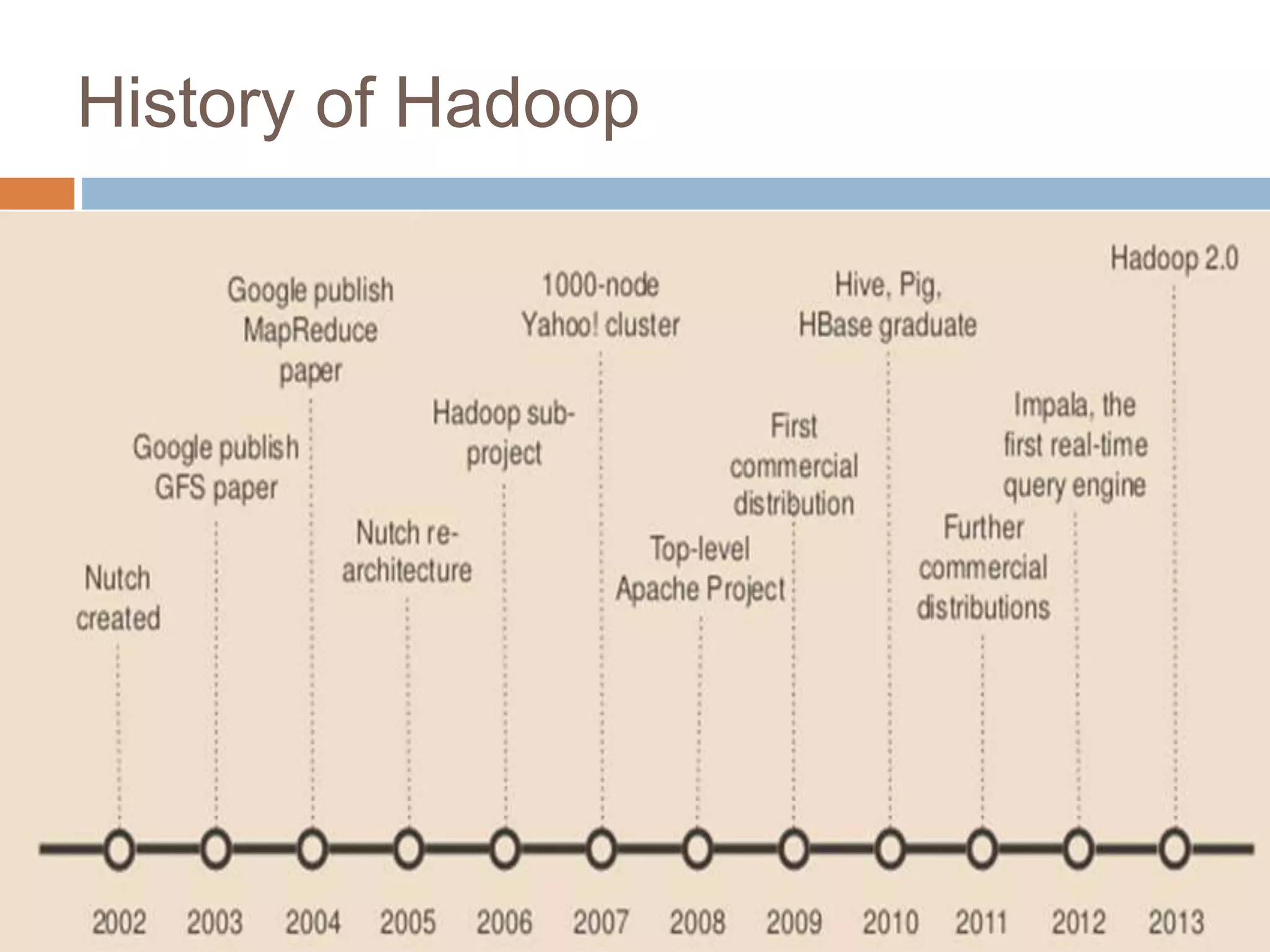
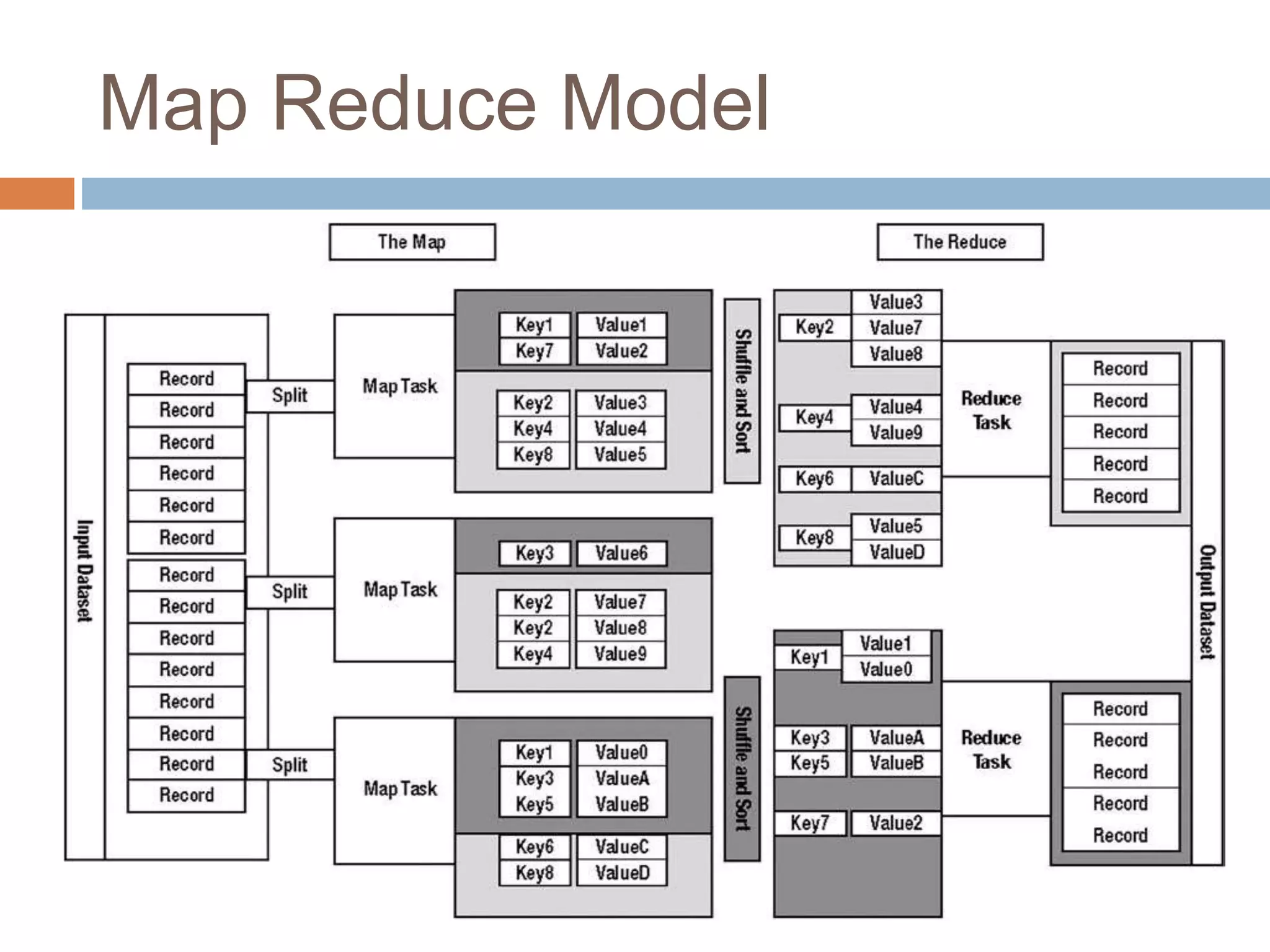
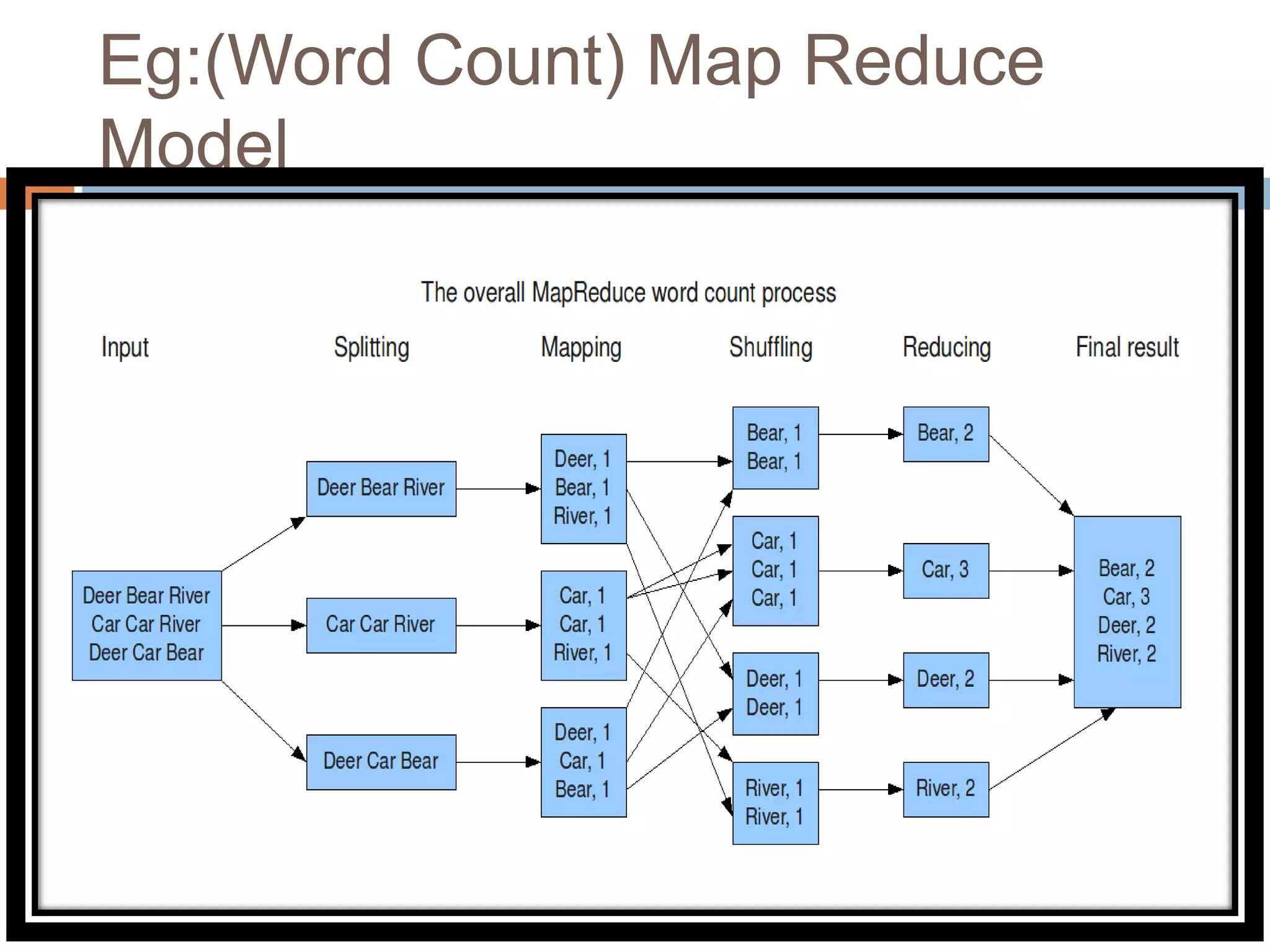
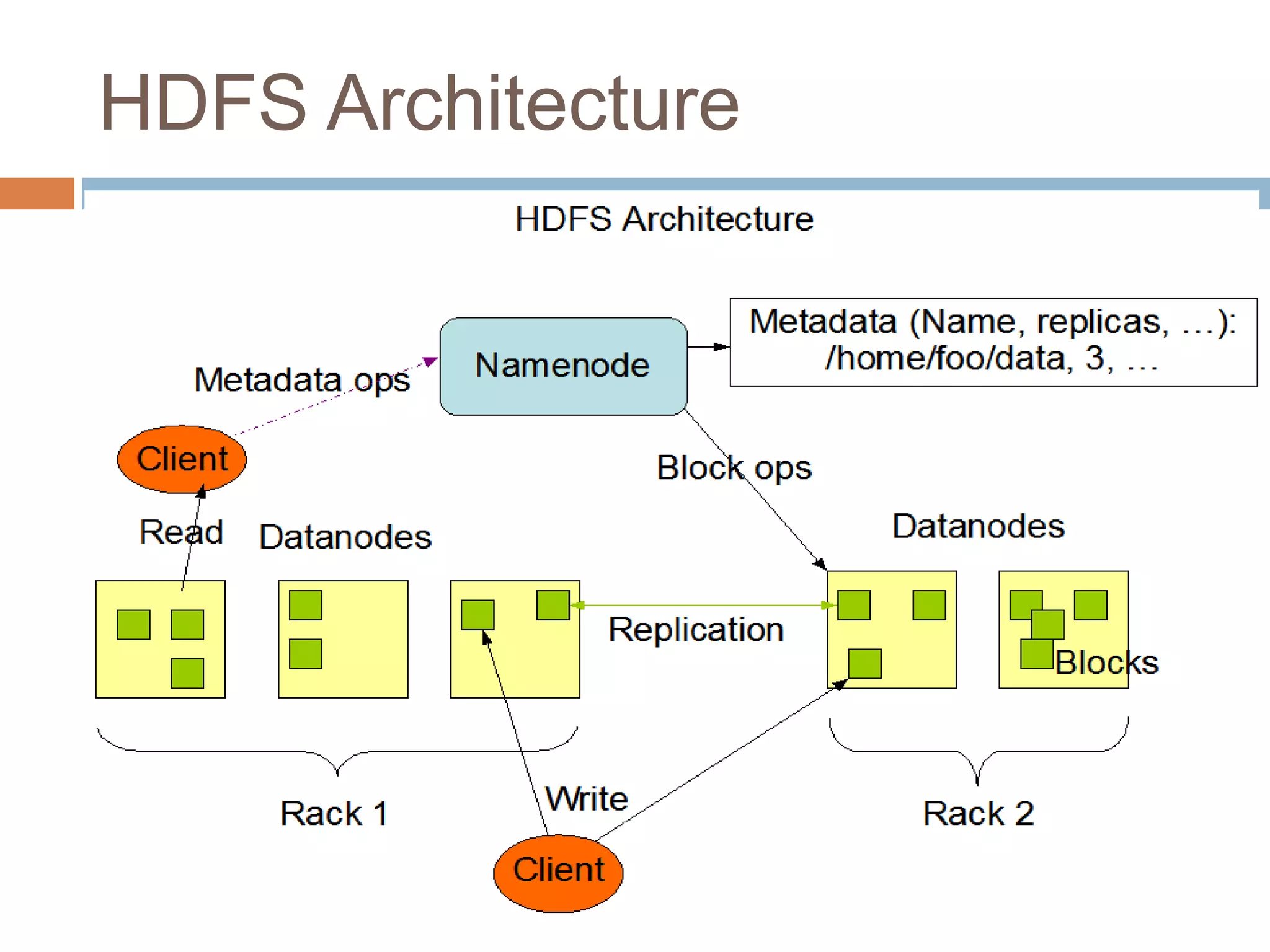
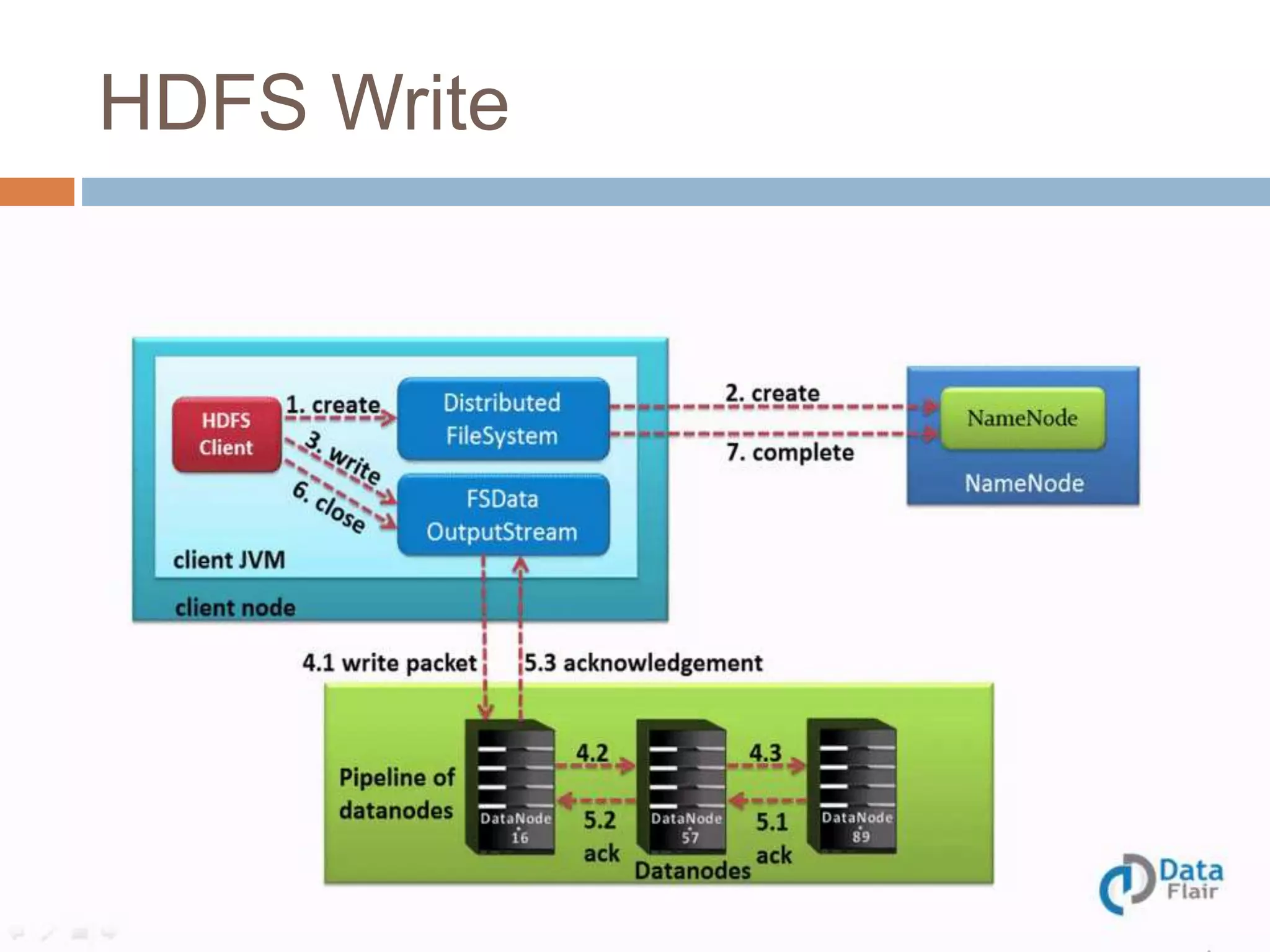
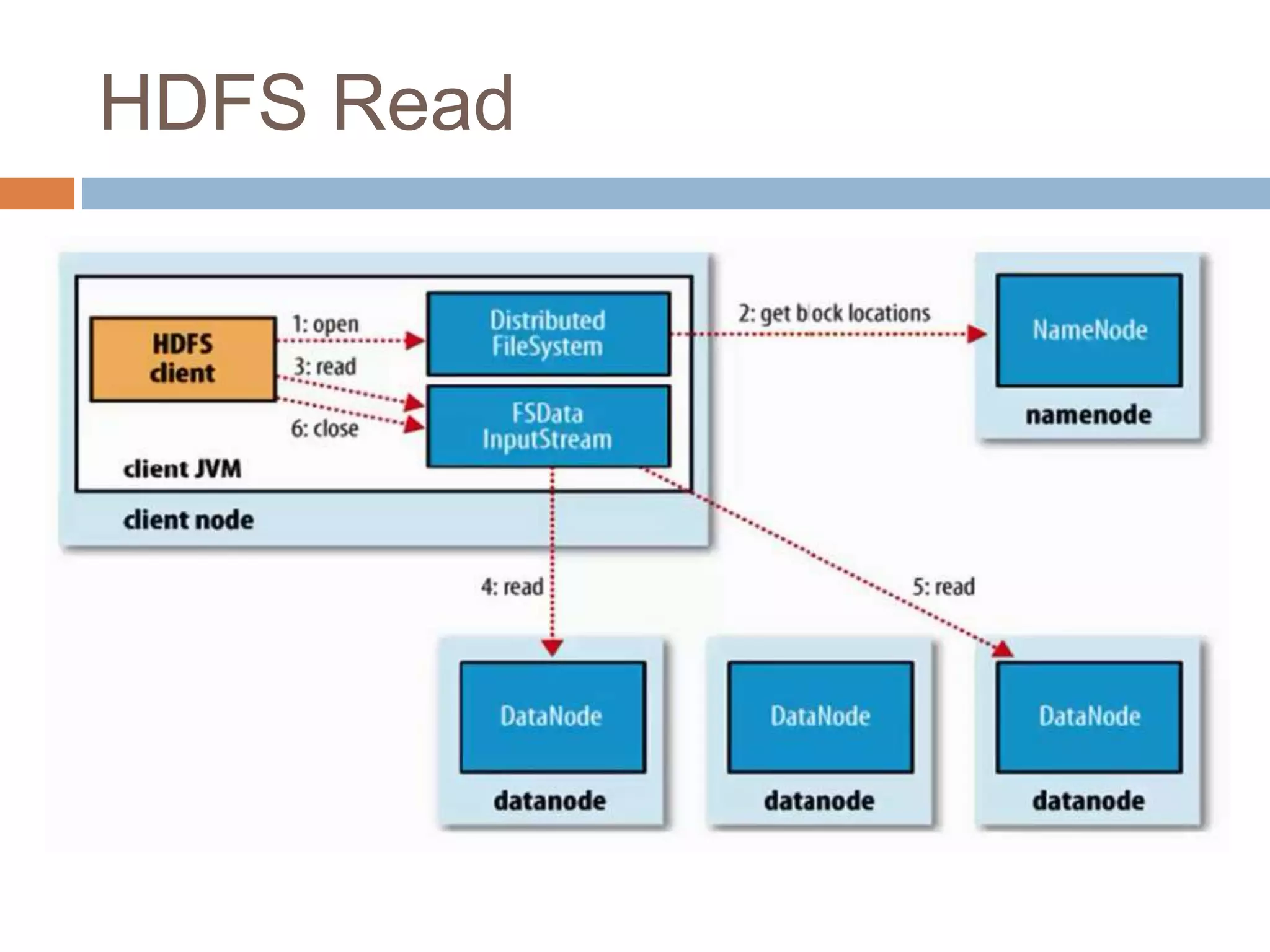
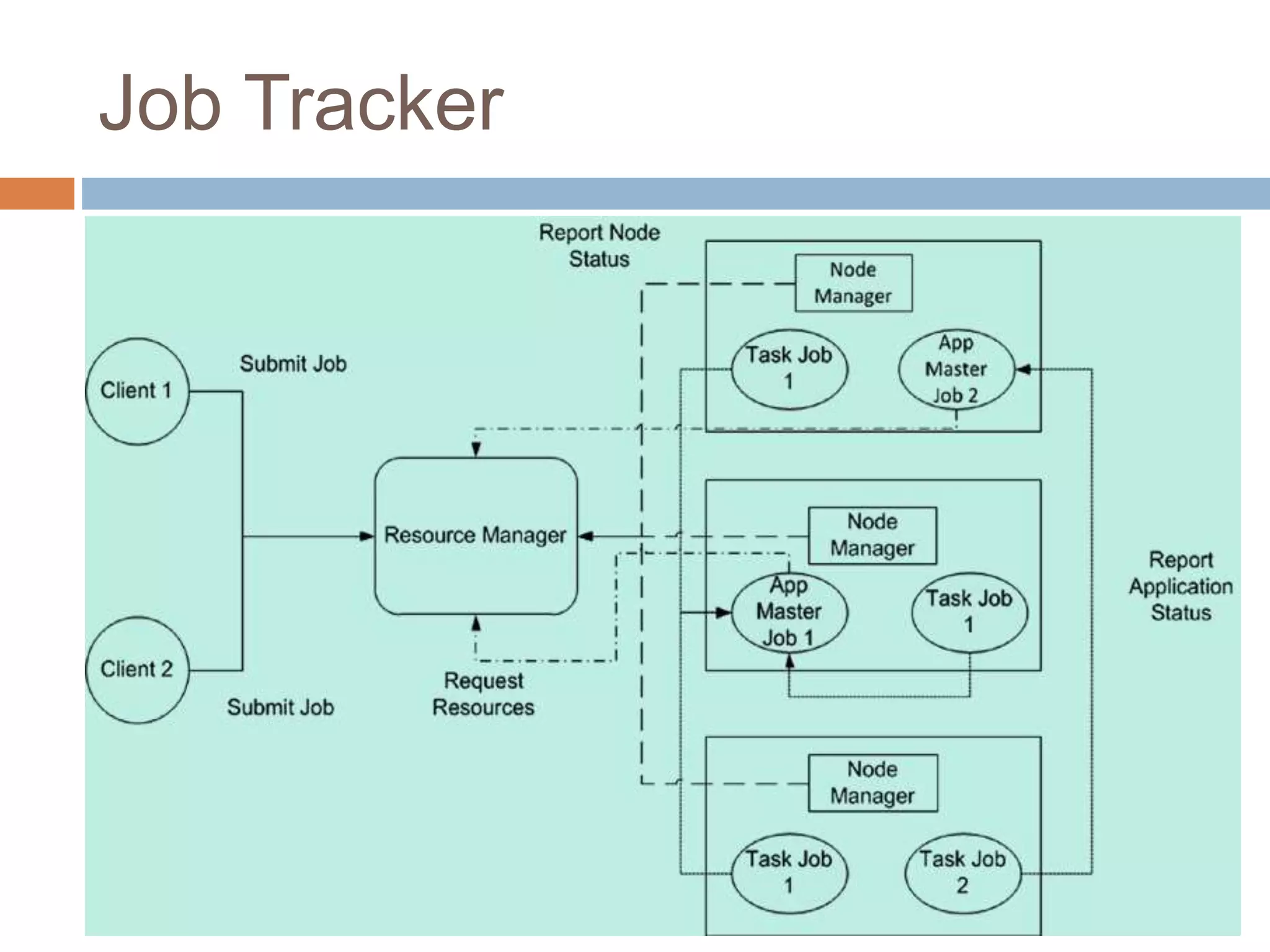
Hadoop is an open-source software platform for distributed storage and processing of large datasets across clusters of computers. It was created to enable applications to work with data beyond the limits of a single computer by distributing workloads and data across a cluster. Key components of Hadoop include HDFS for distributed storage, MapReduce for distributed processing, and YARN for distributed resource management.