Download as PDF, PPTX



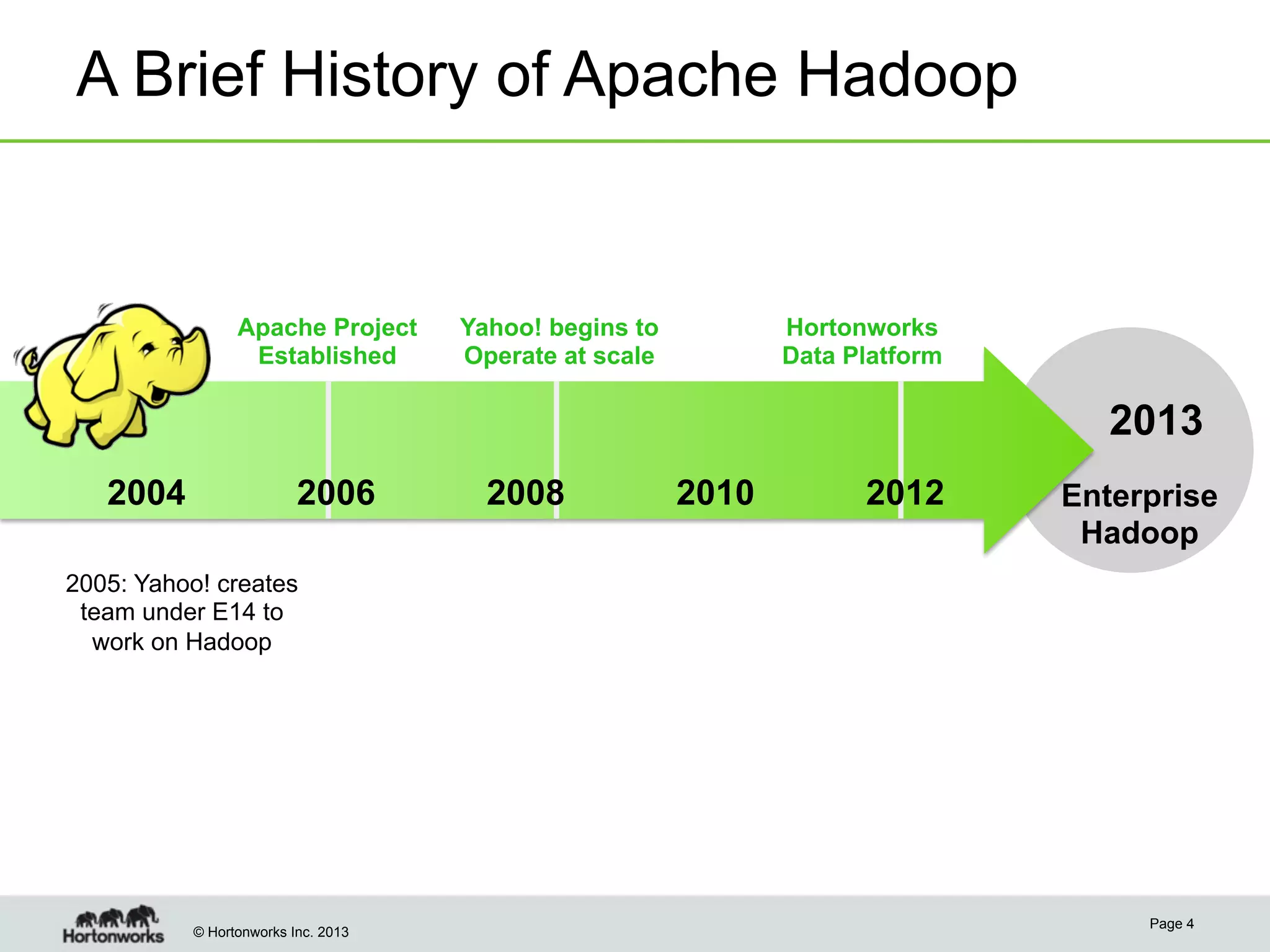
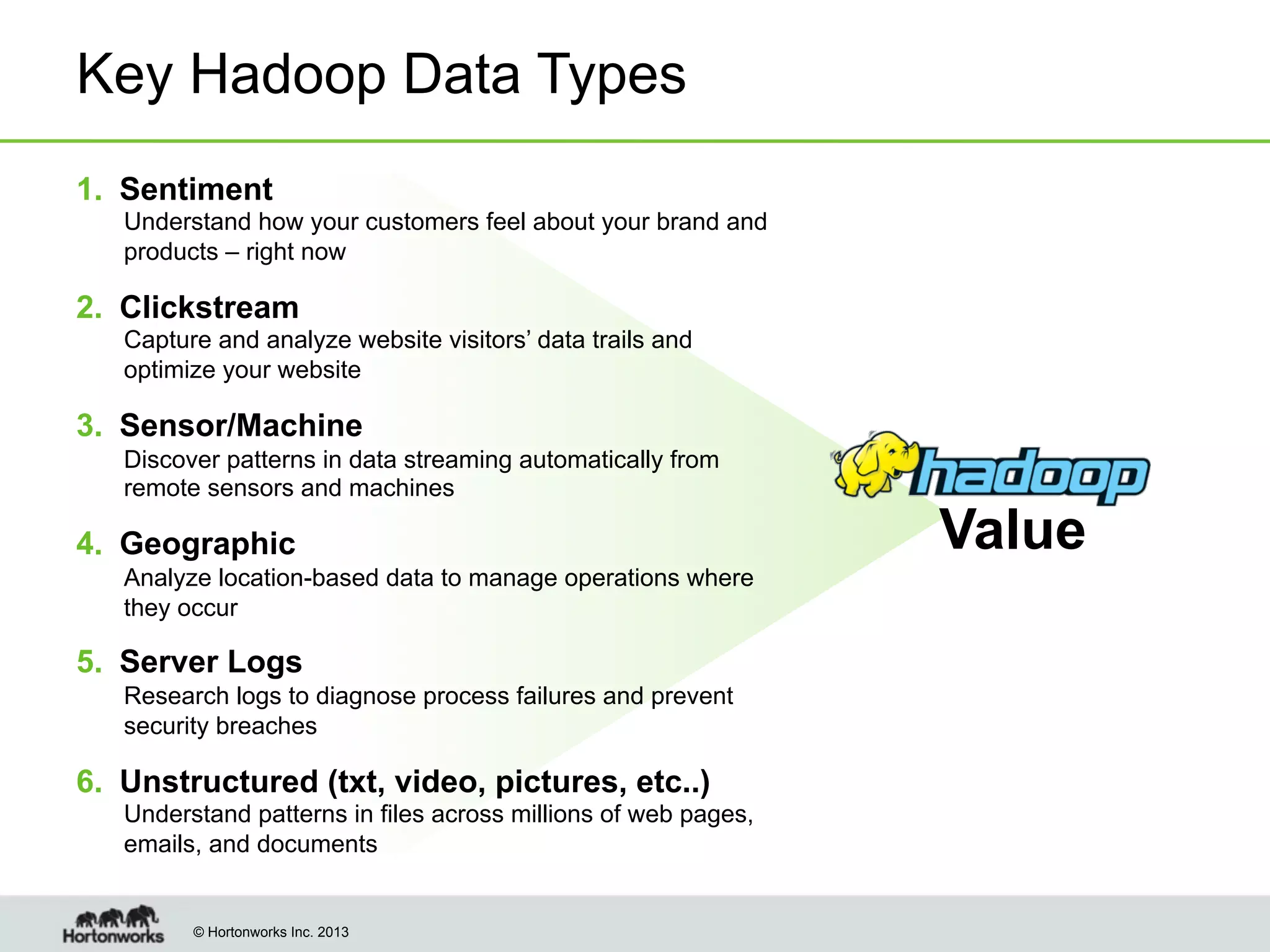


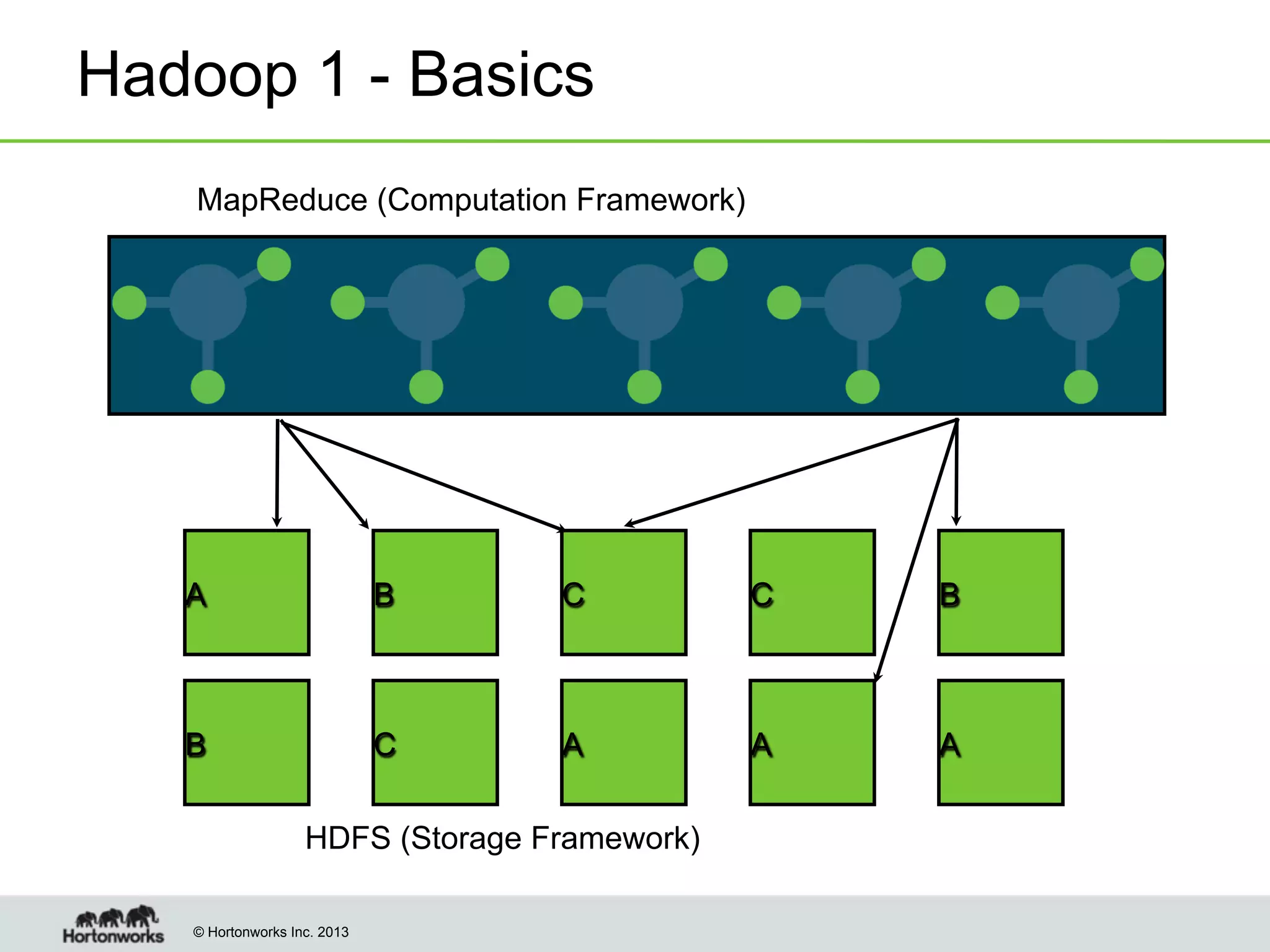
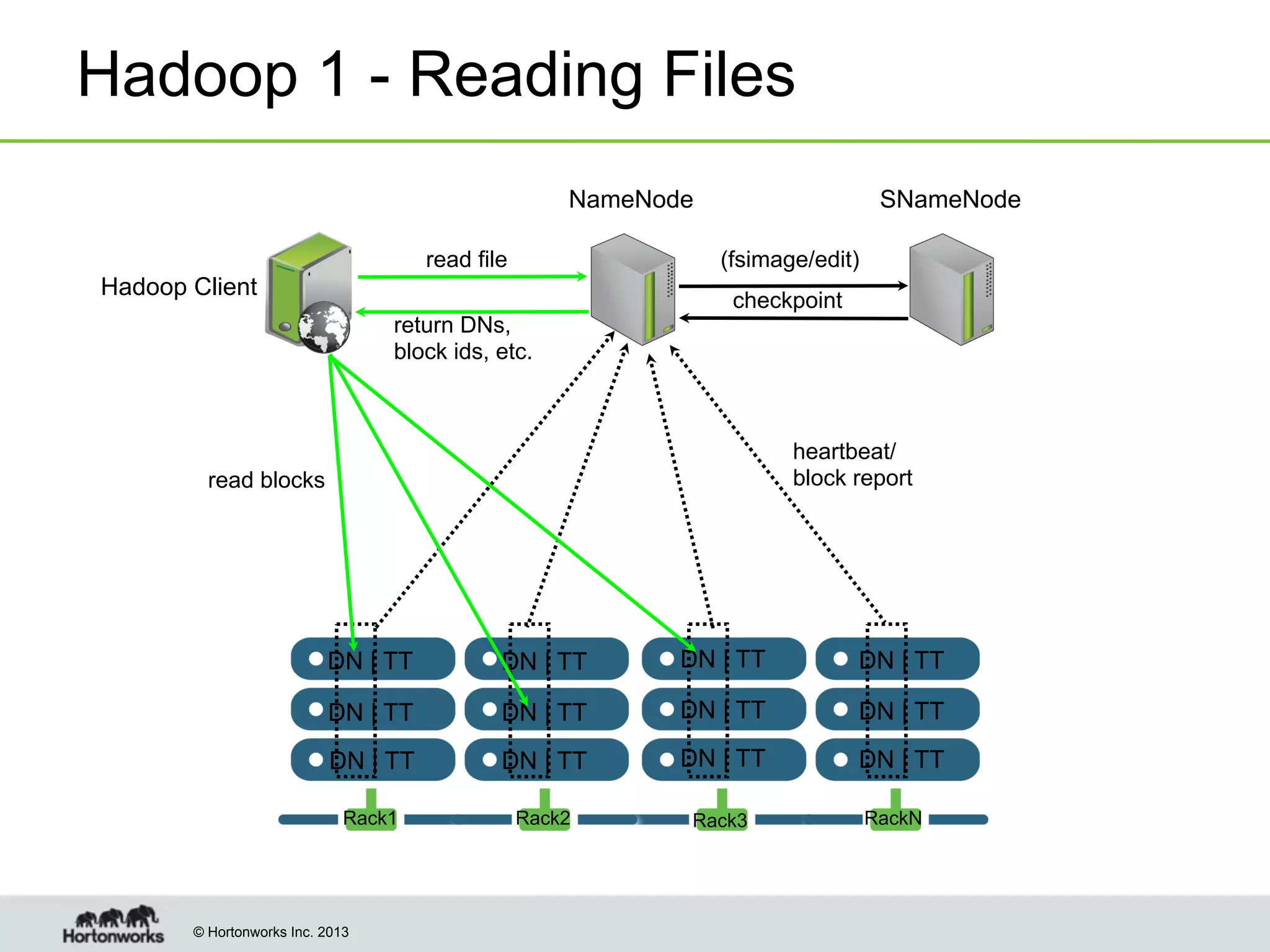
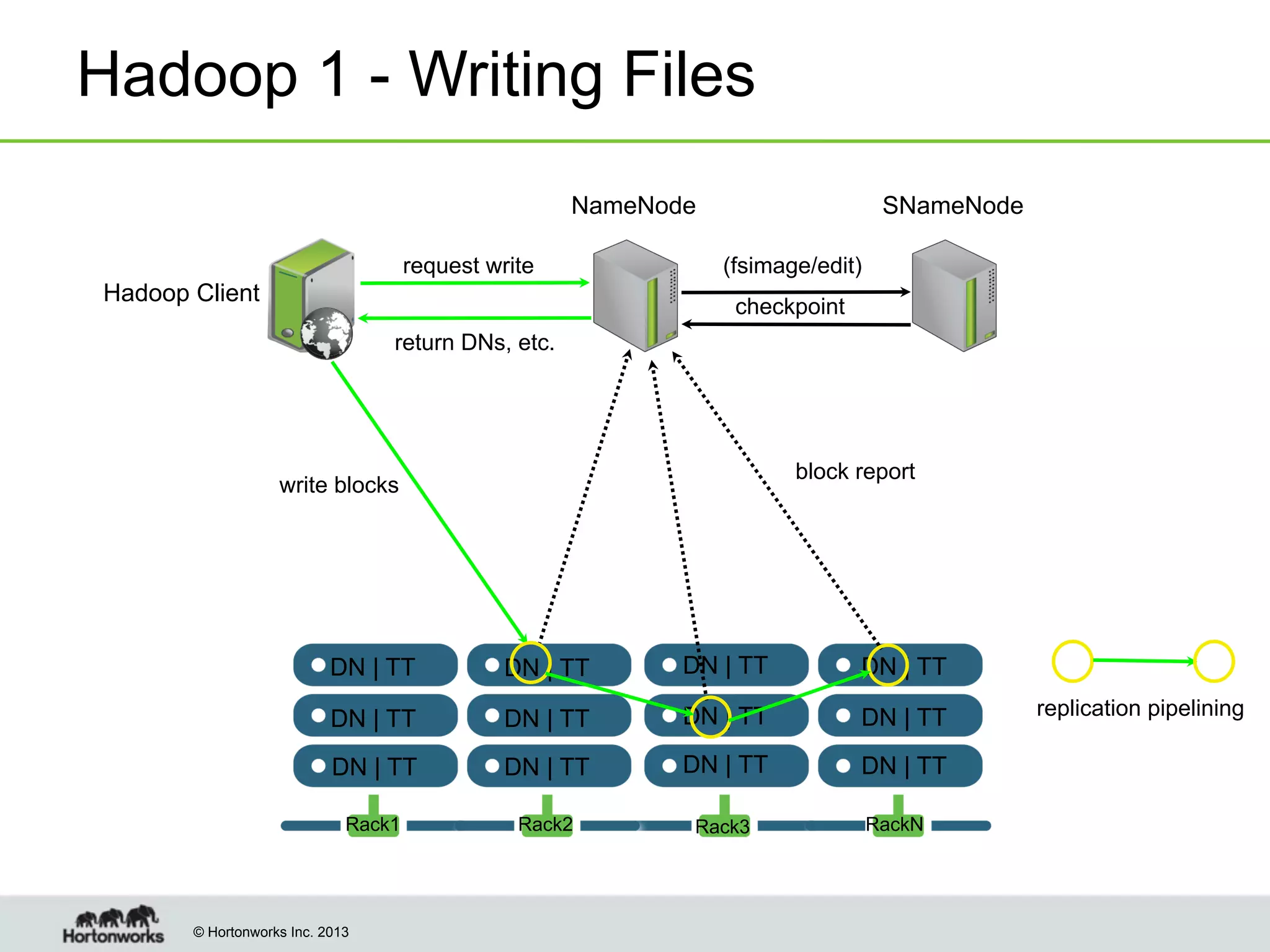
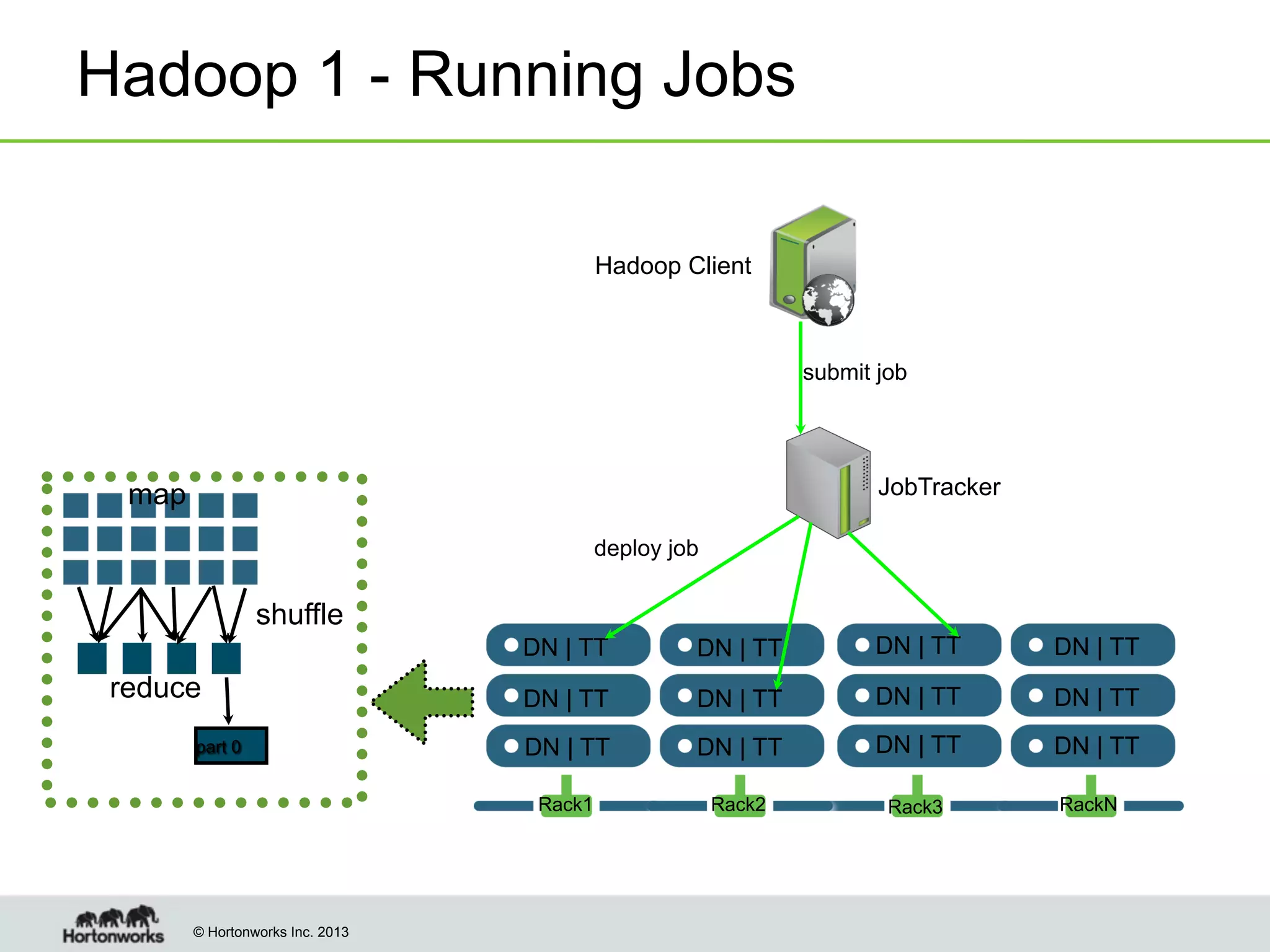
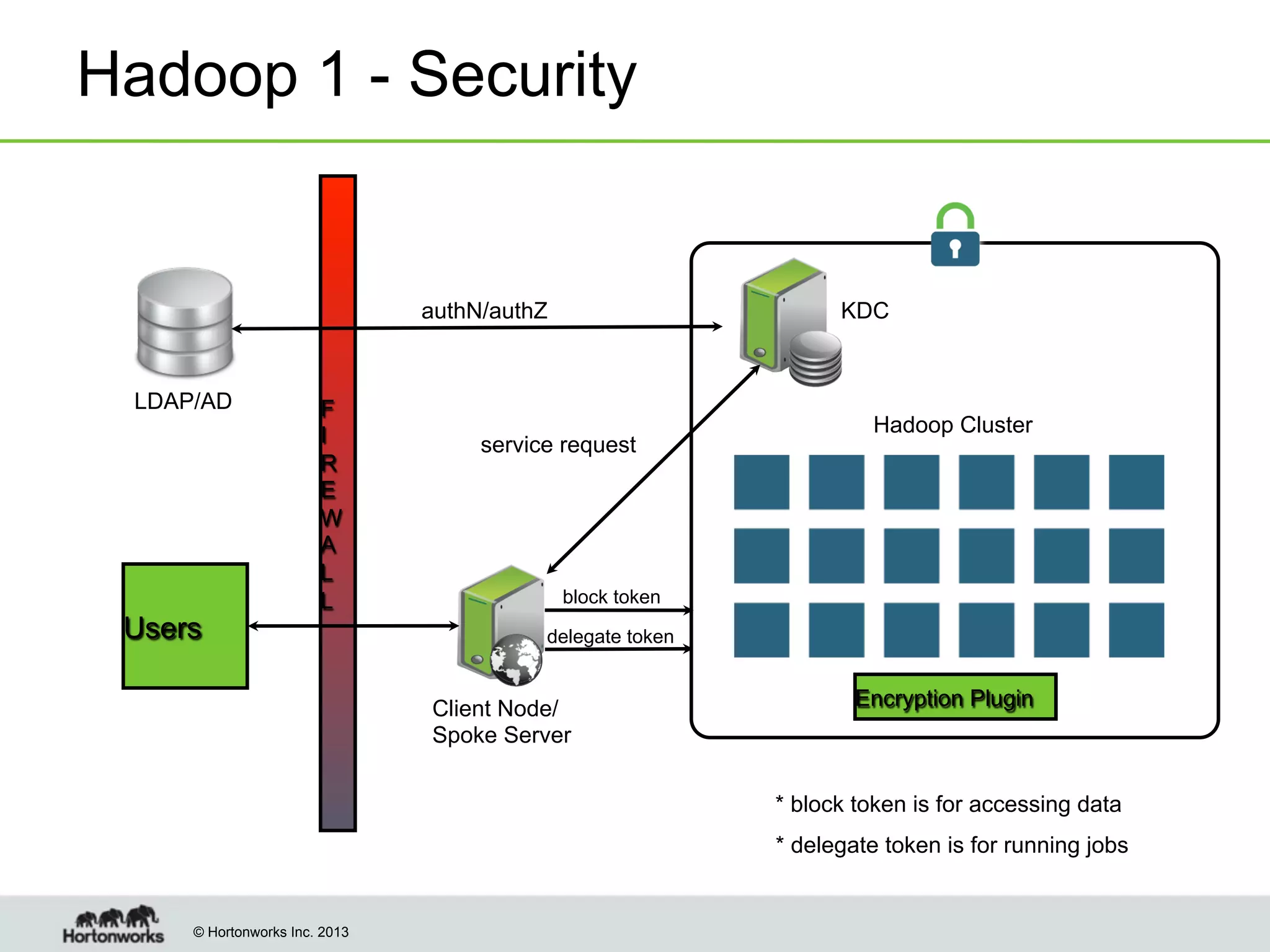



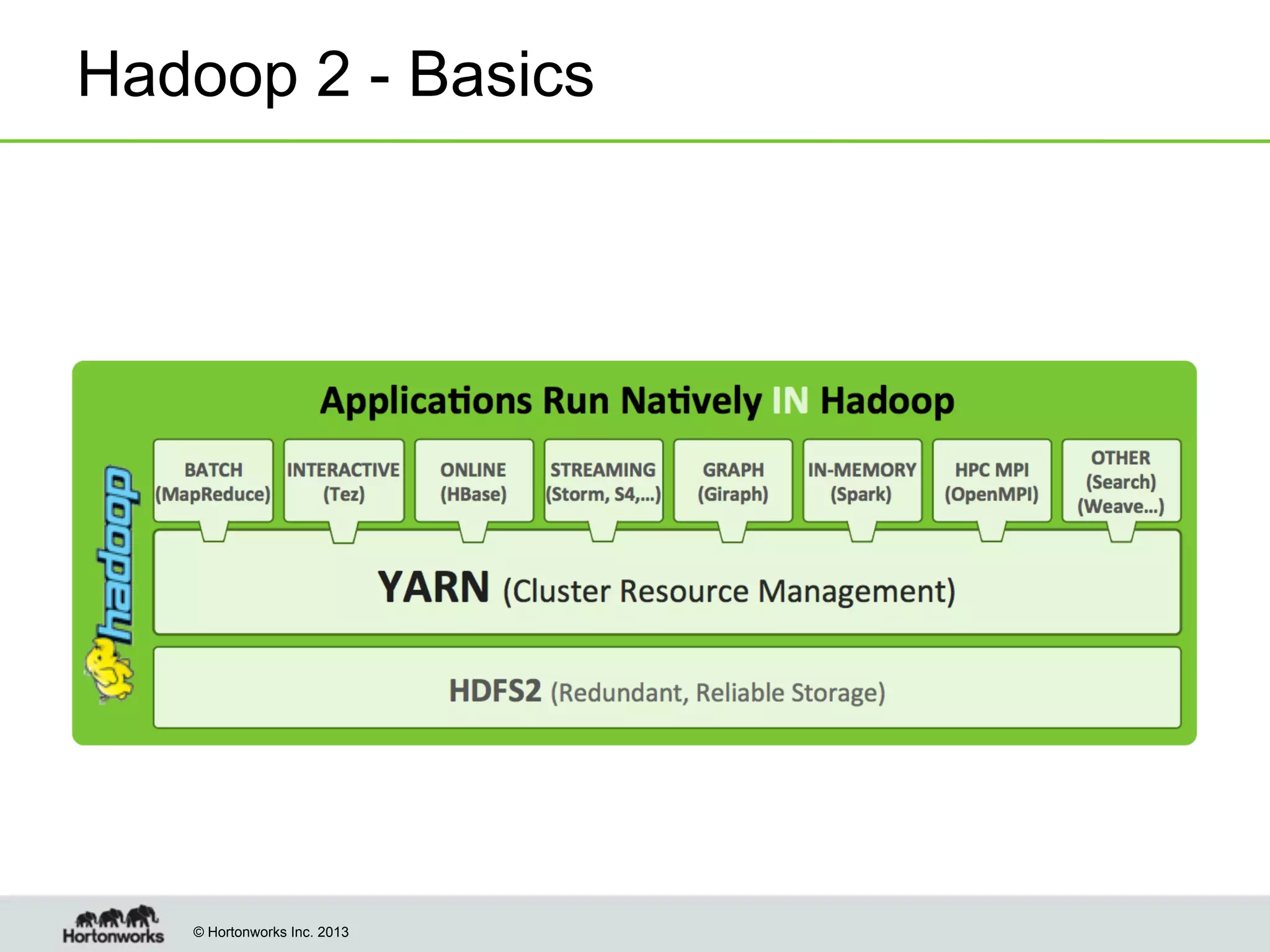
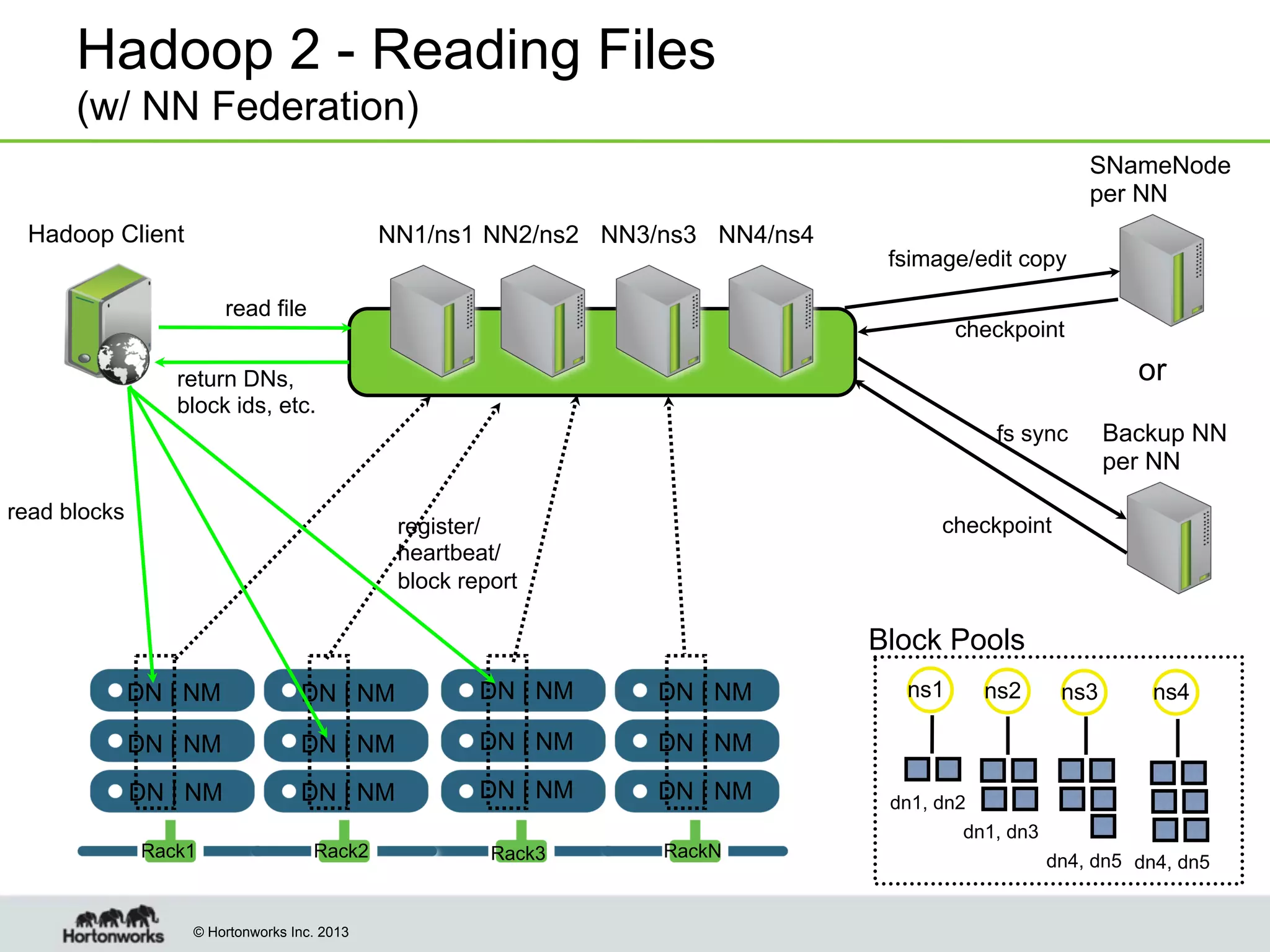
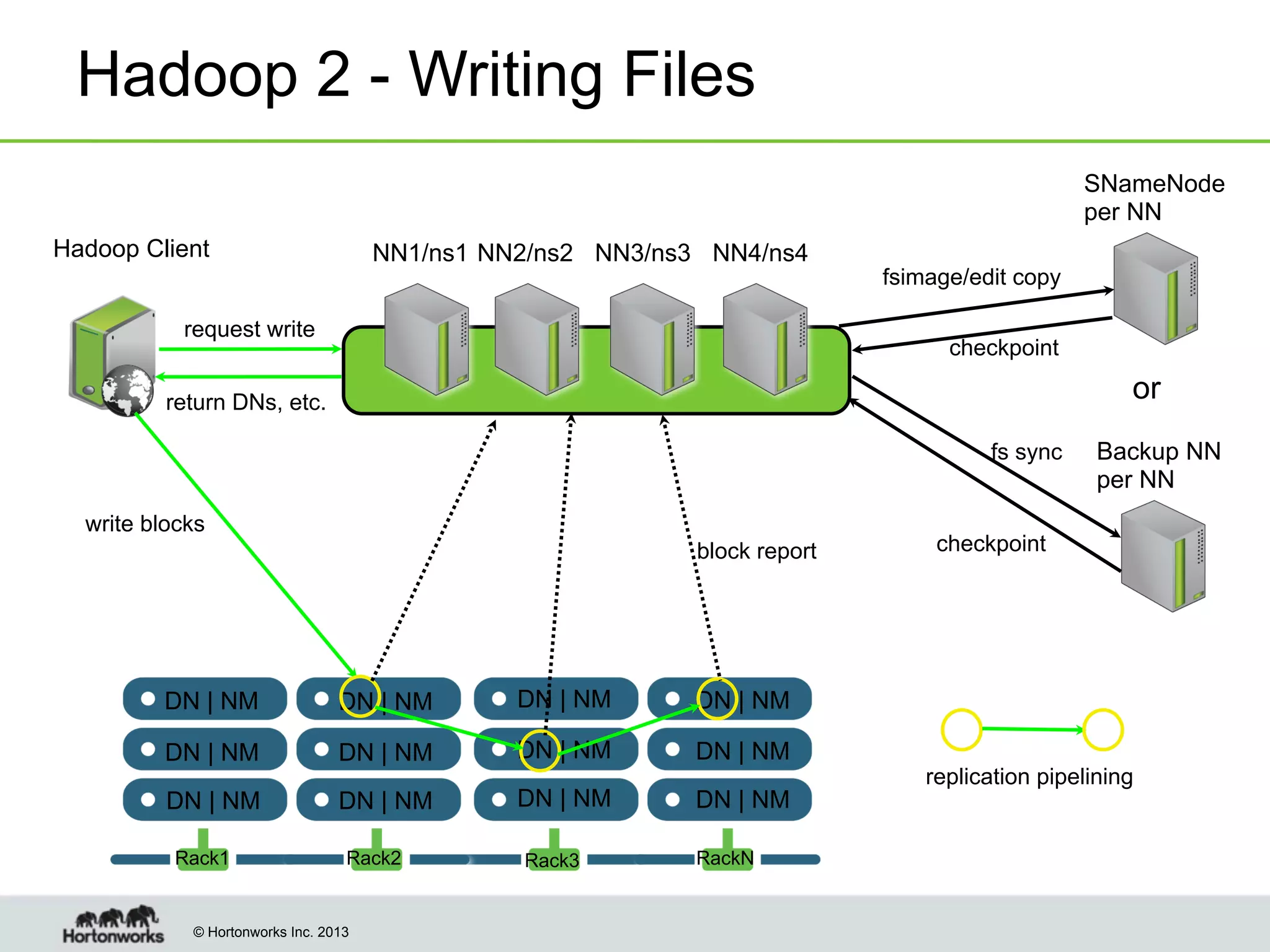
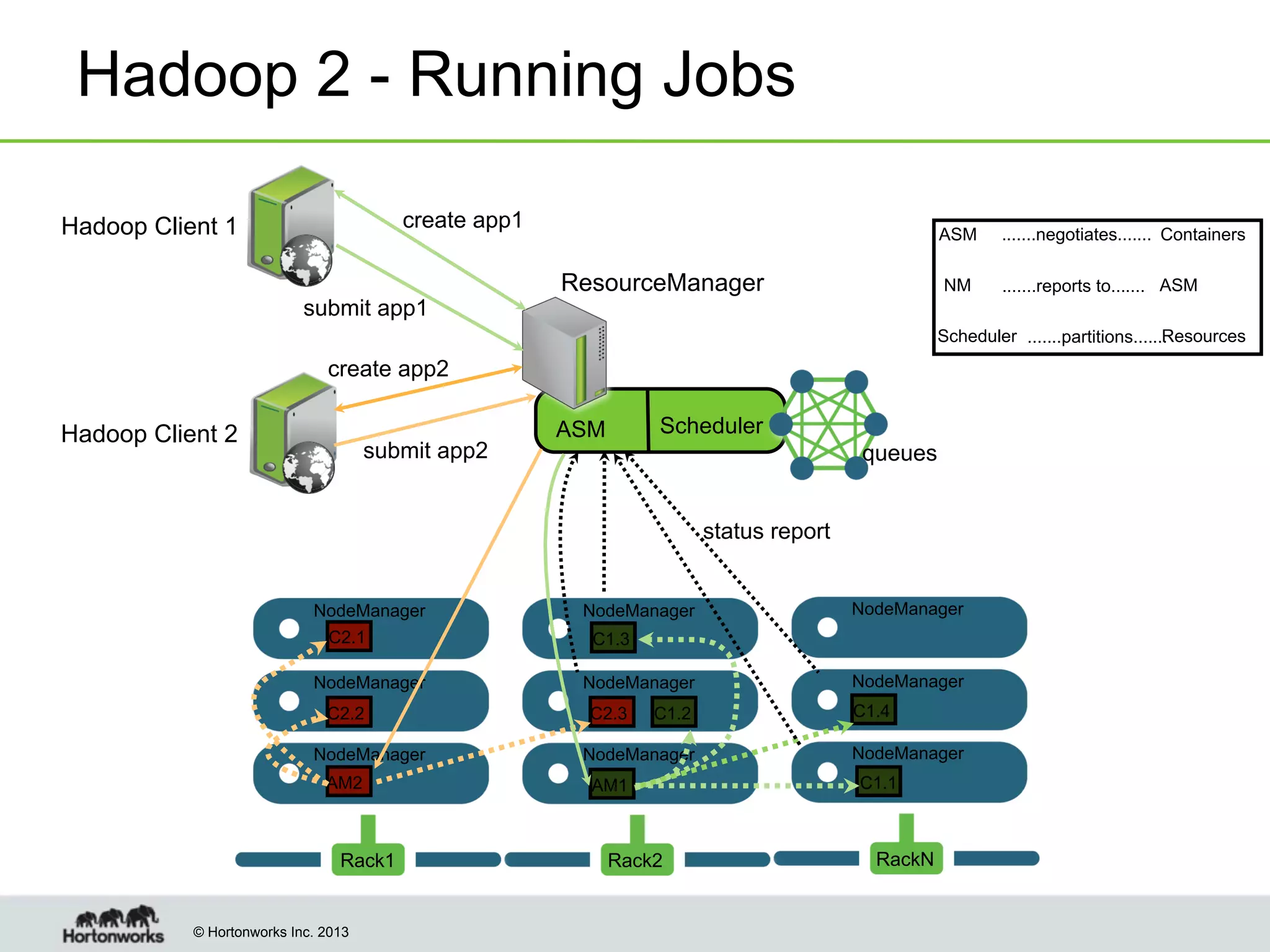
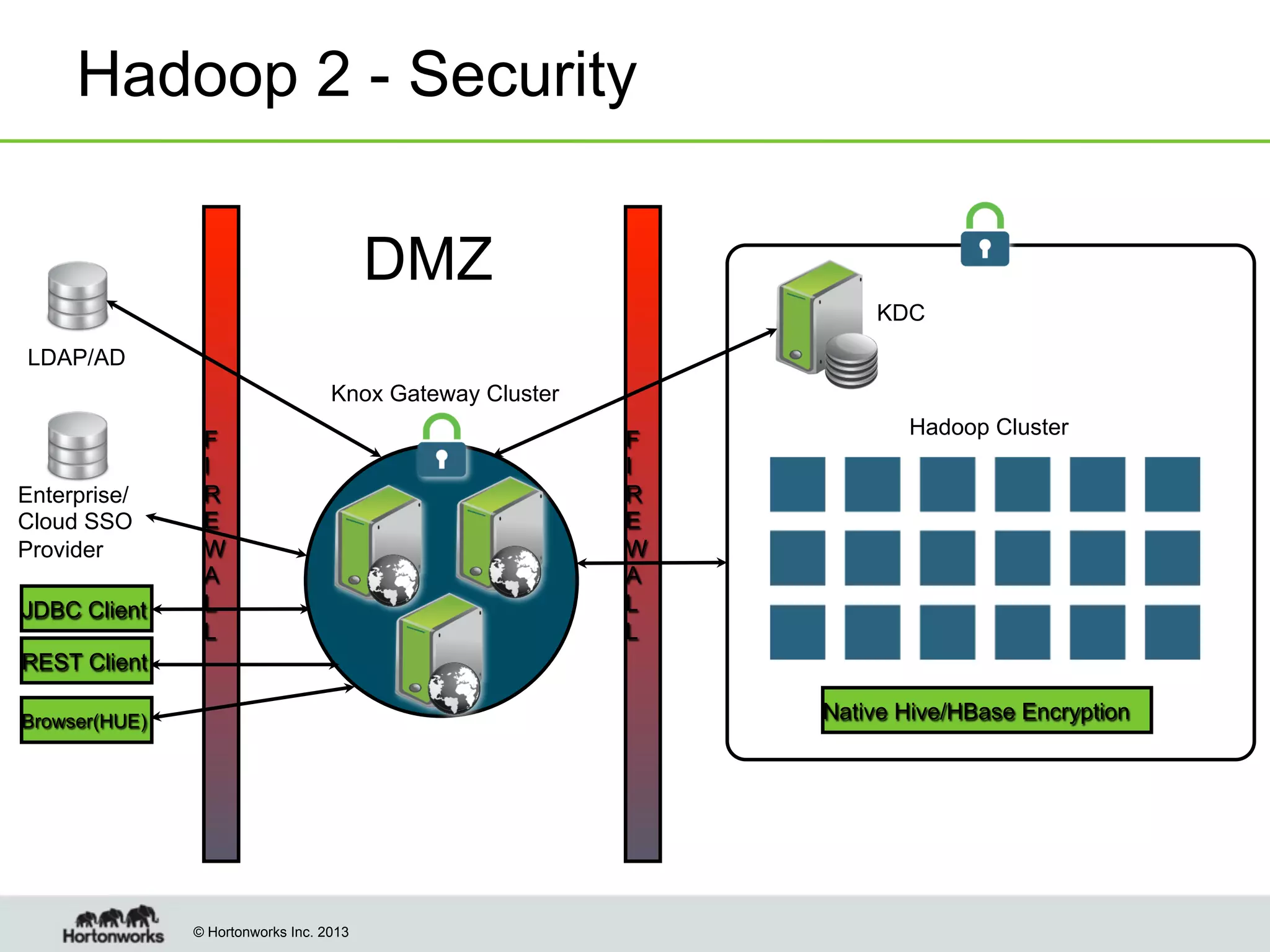



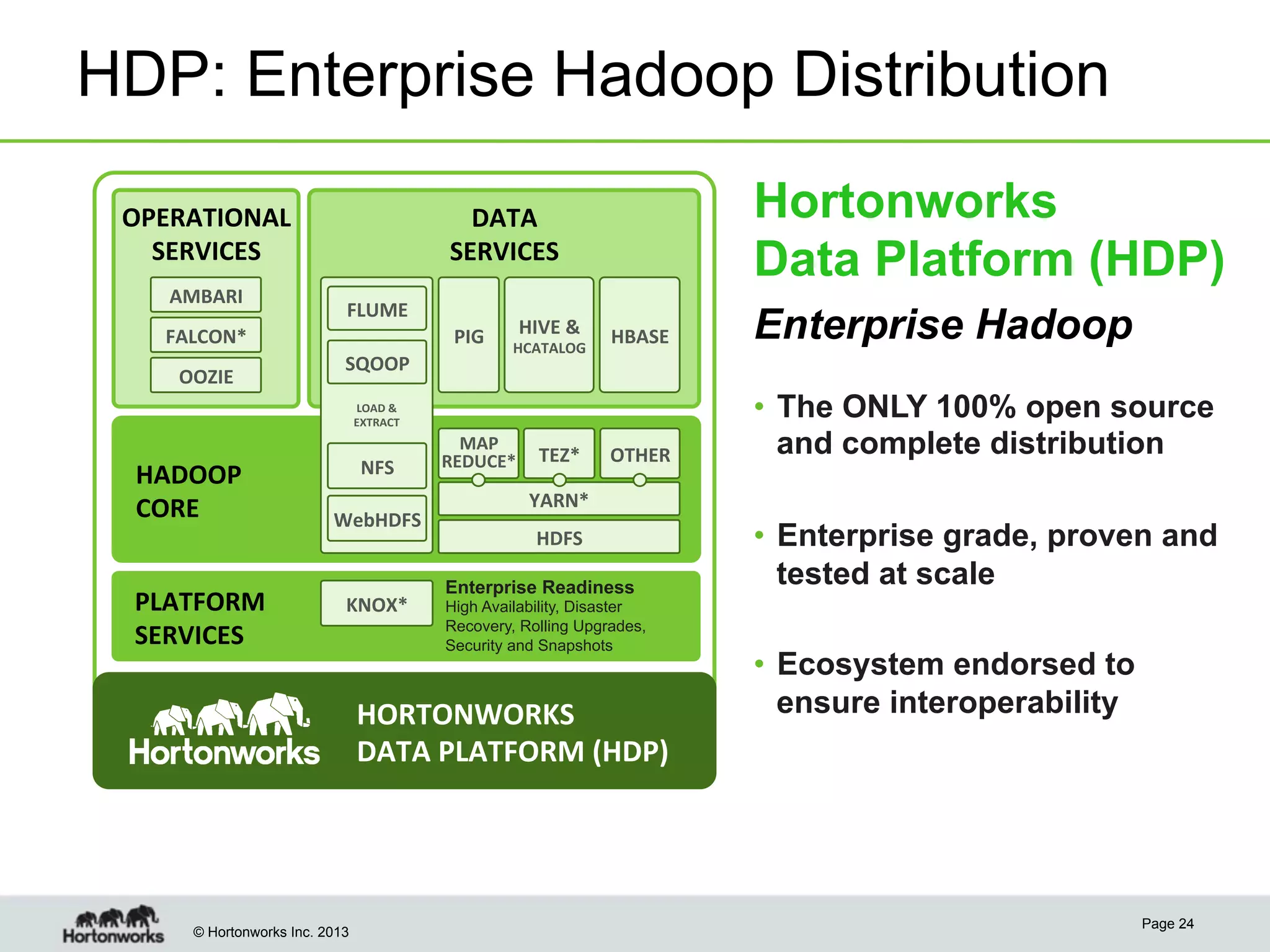


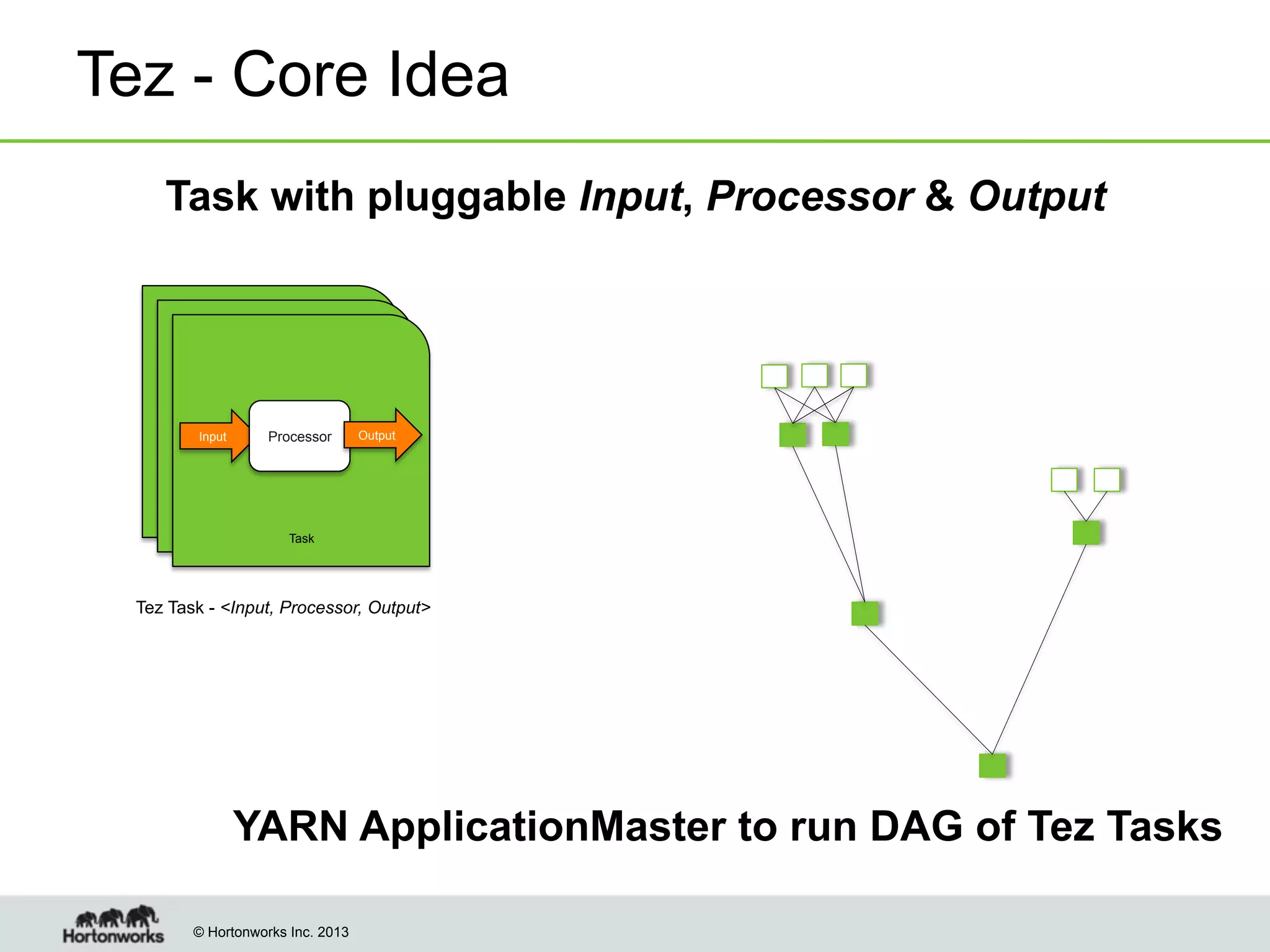
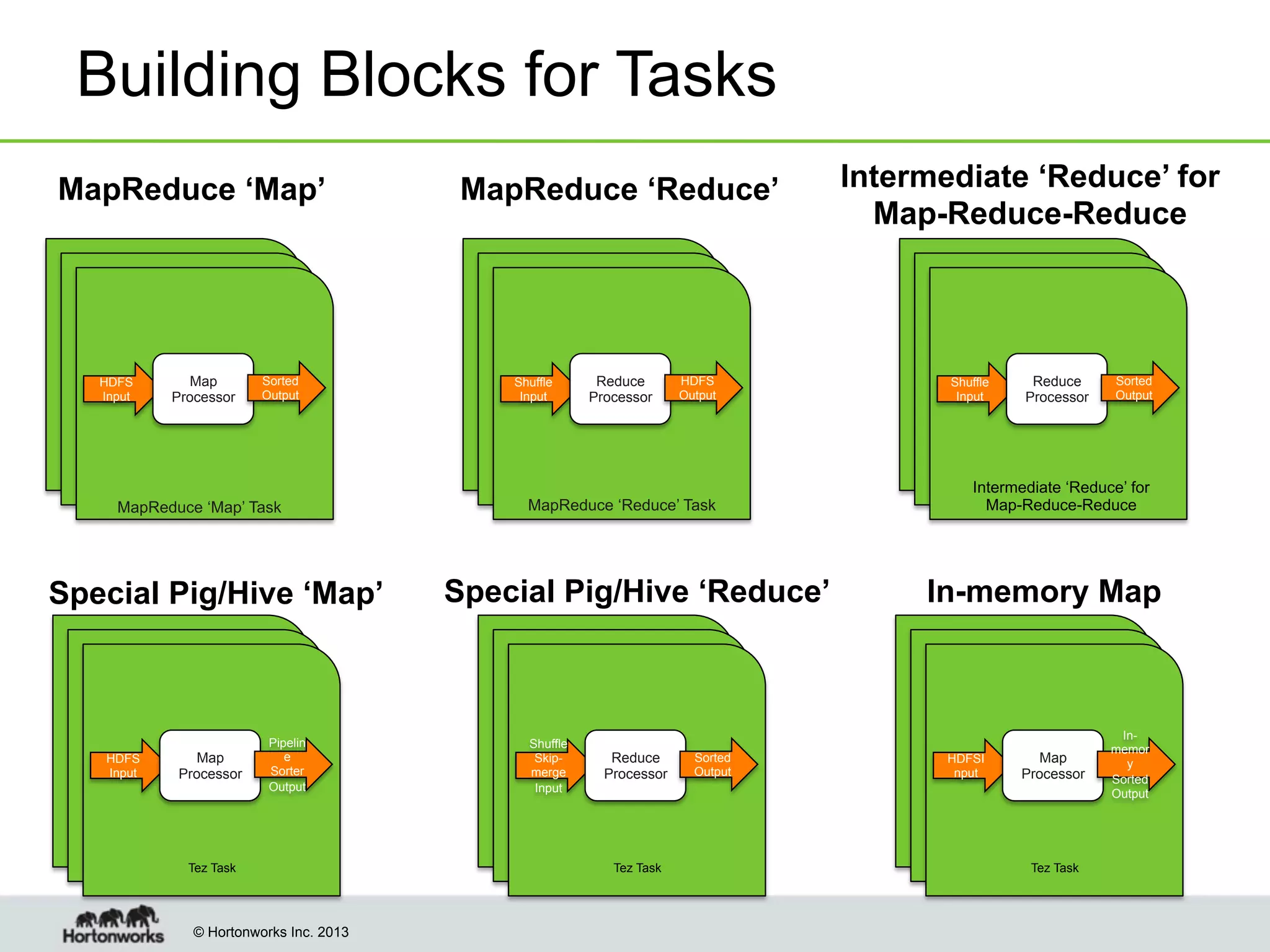
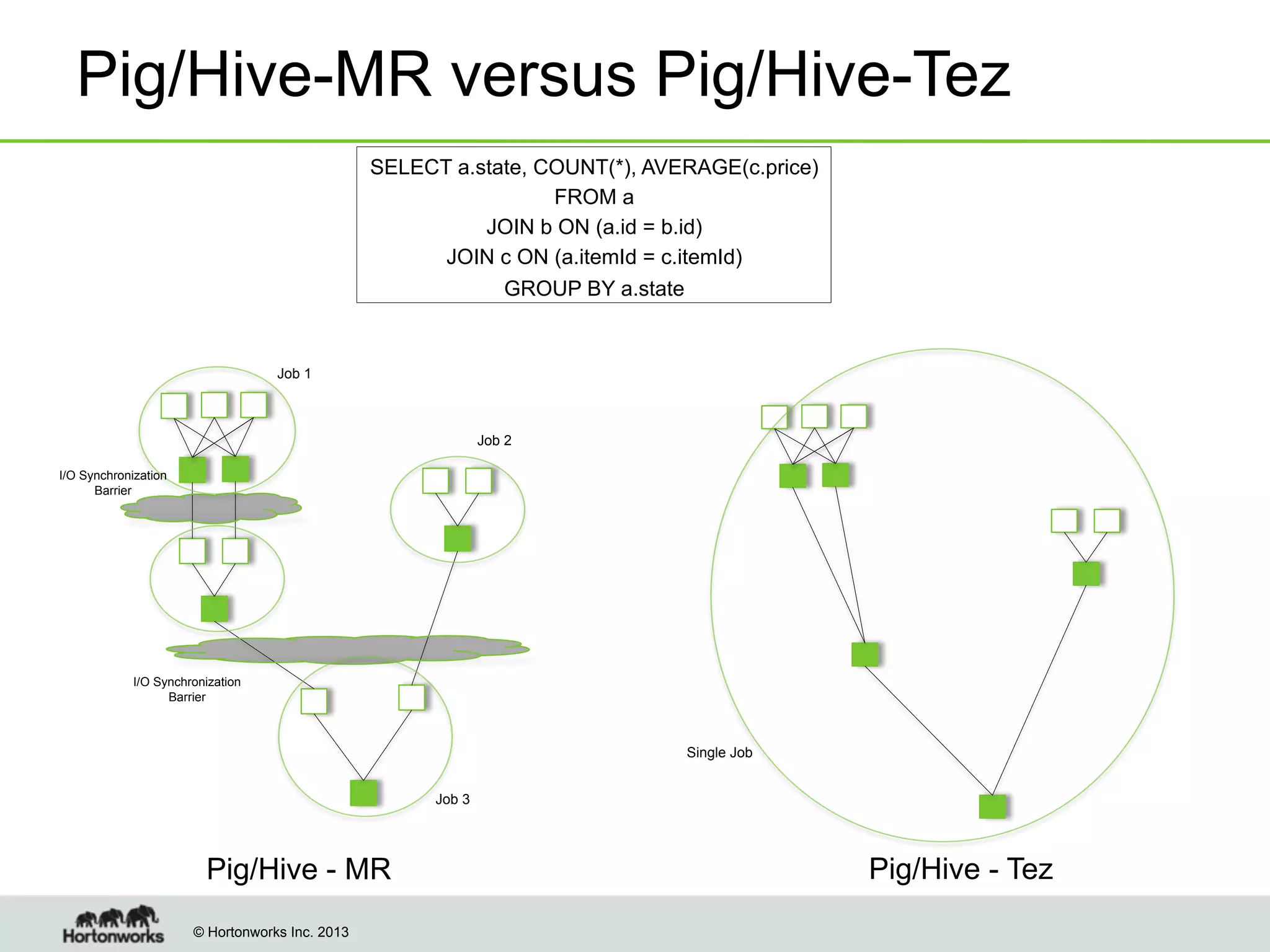
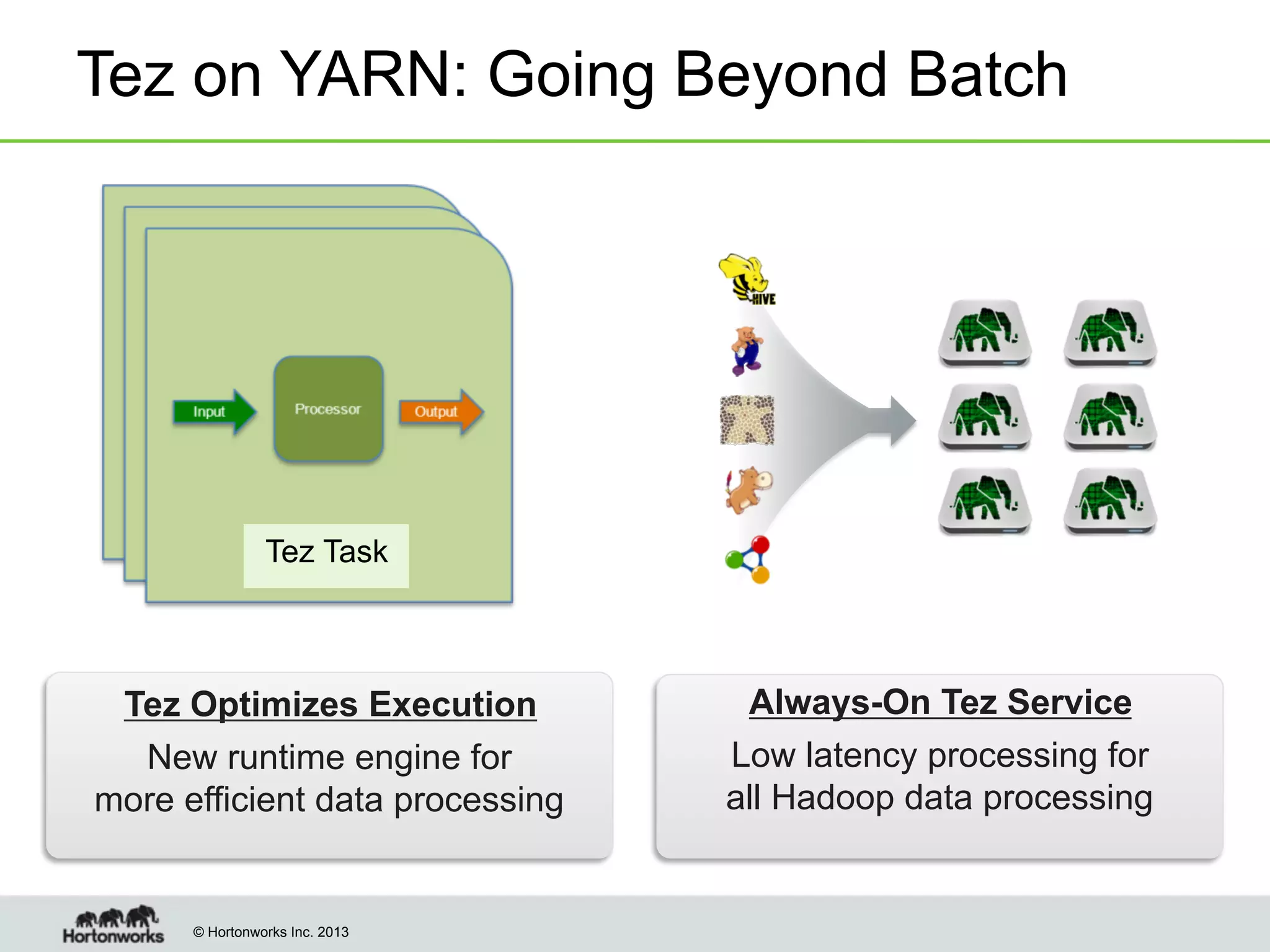

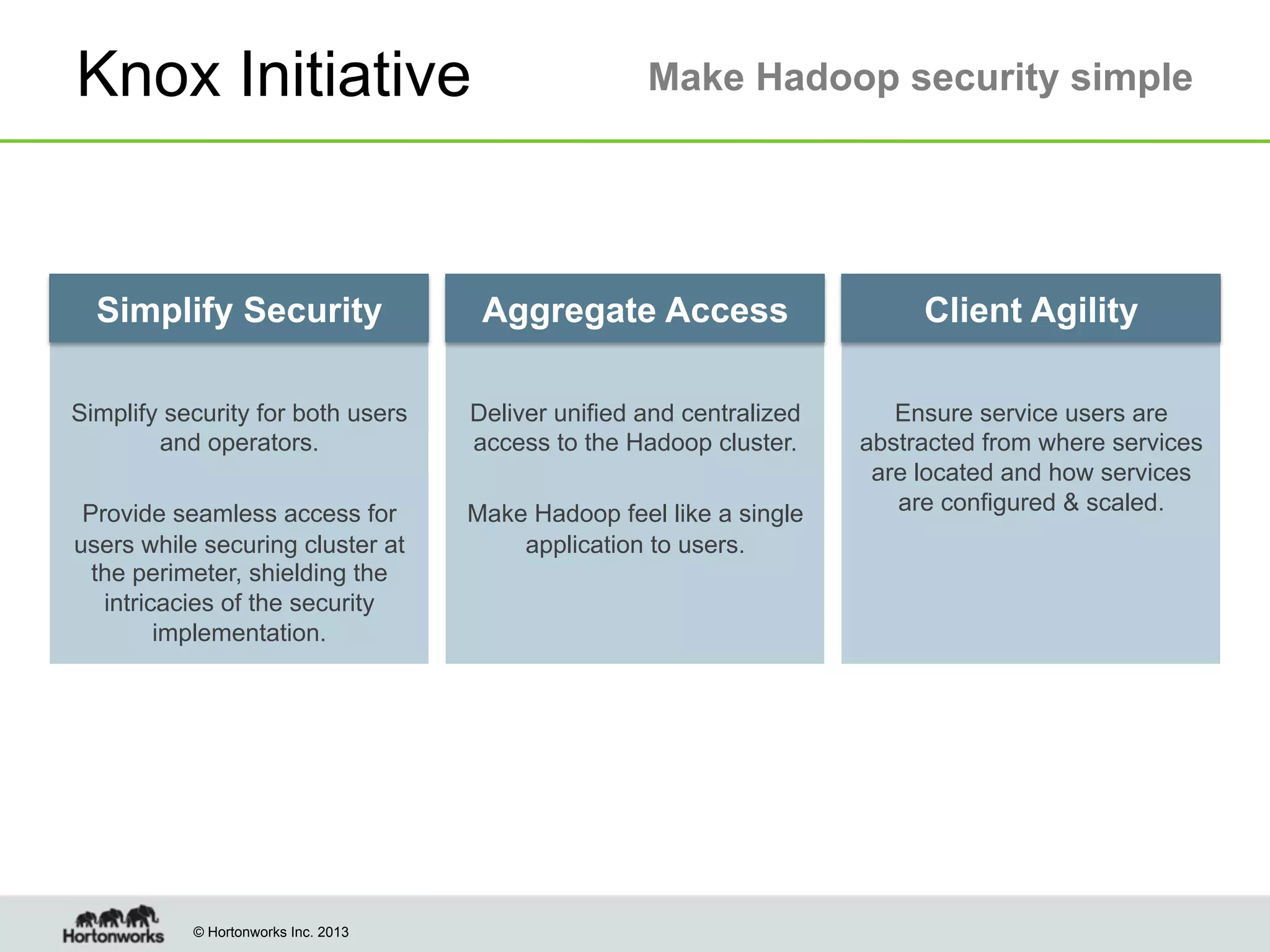
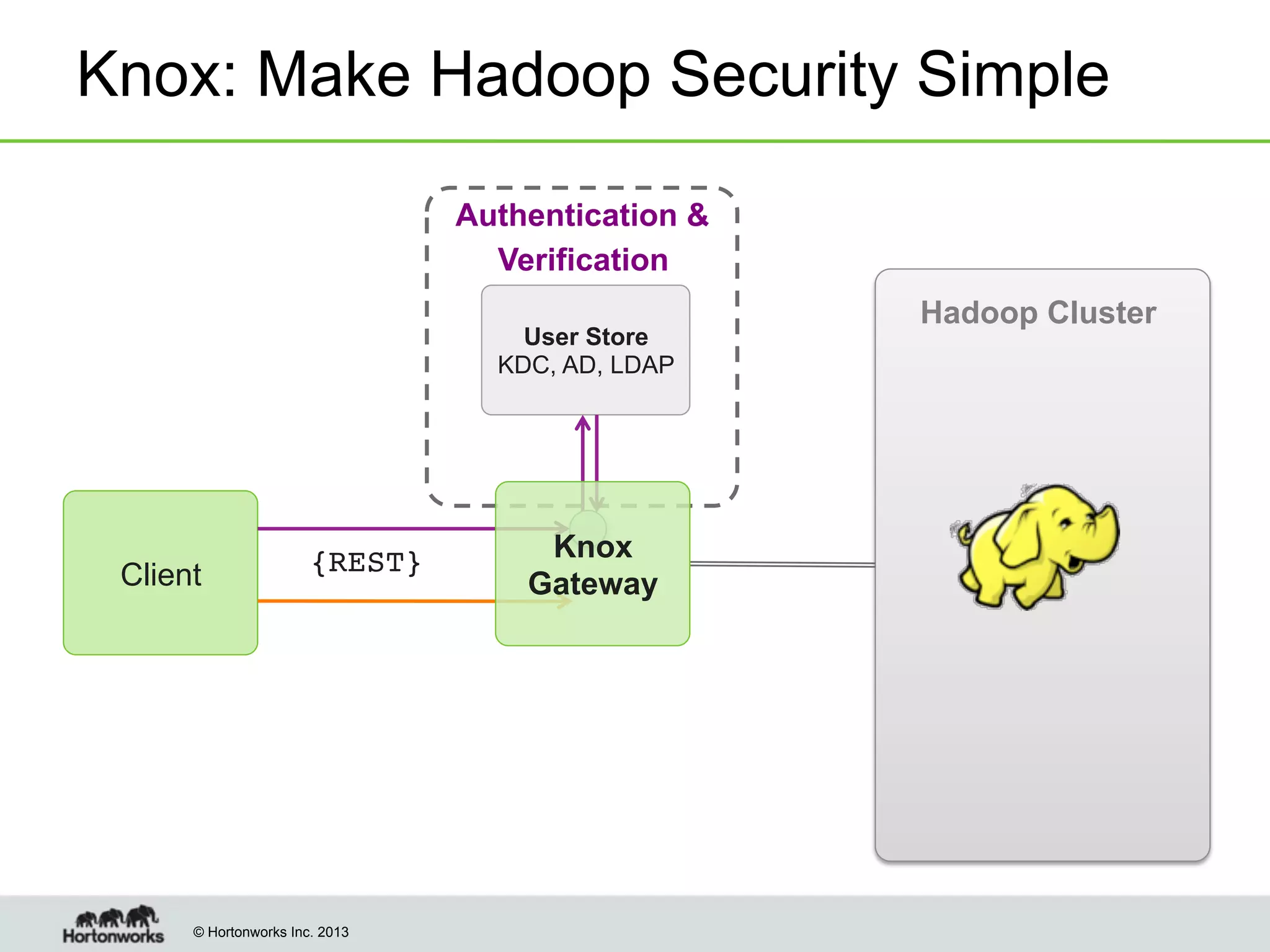
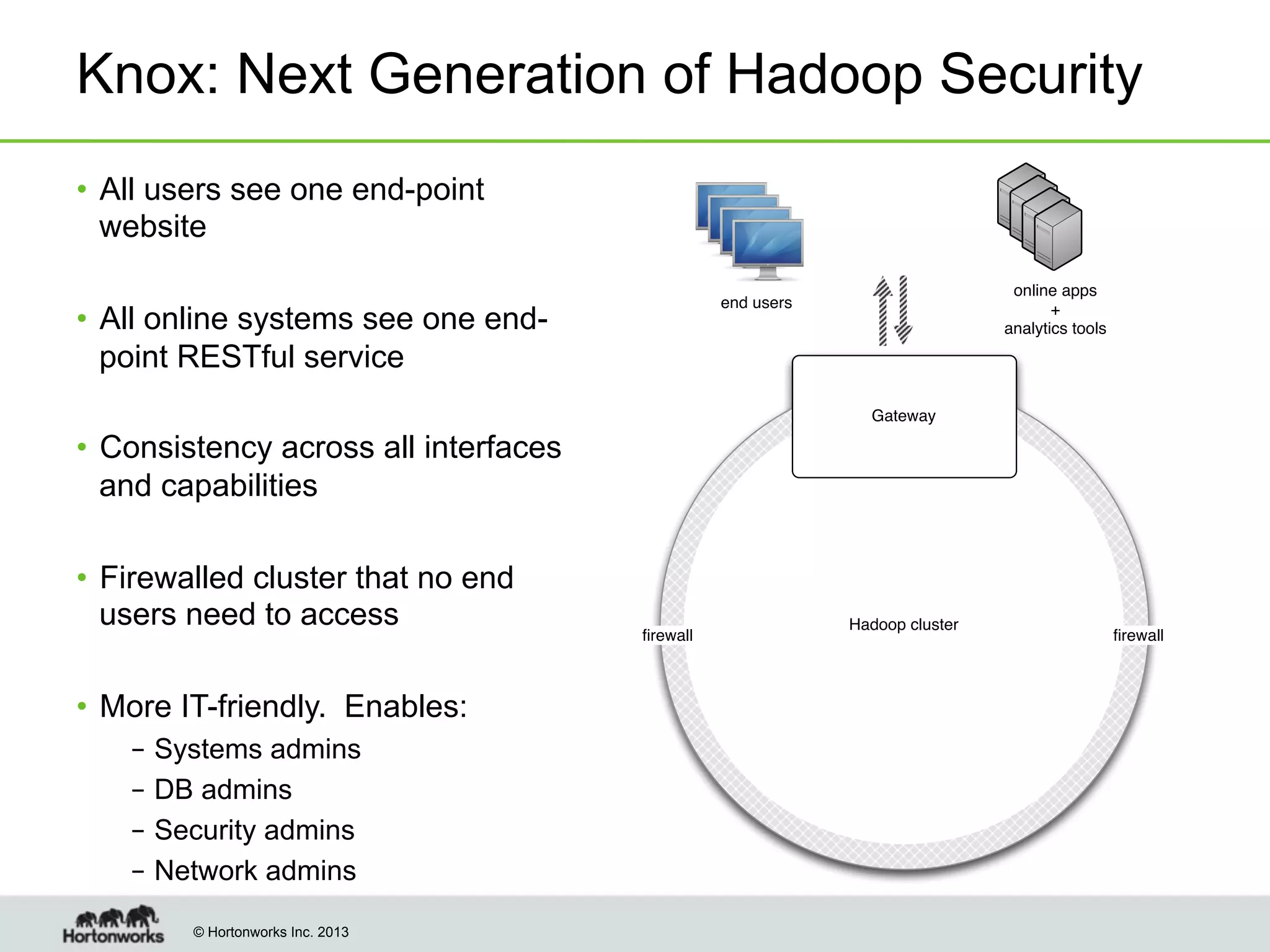



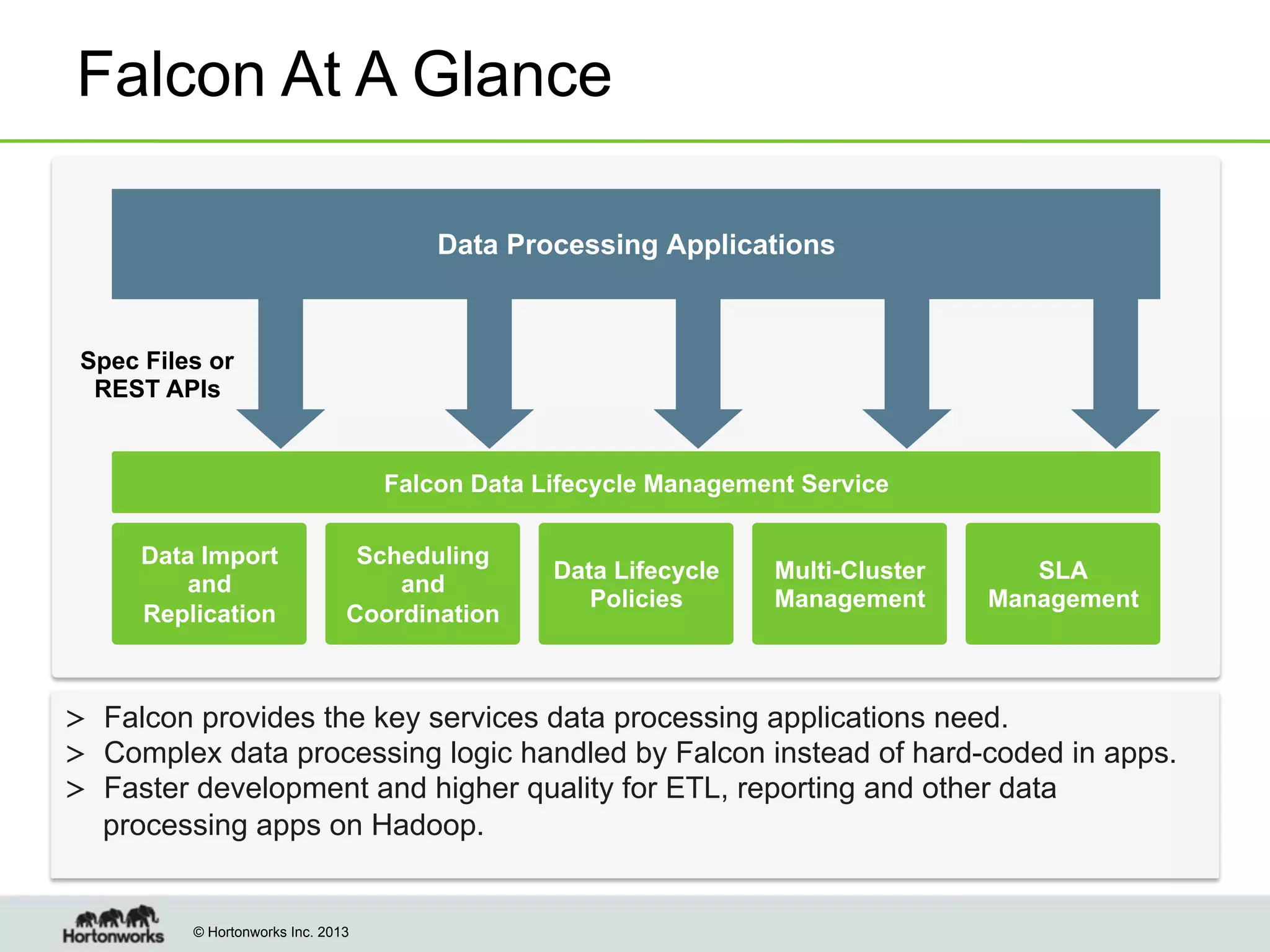

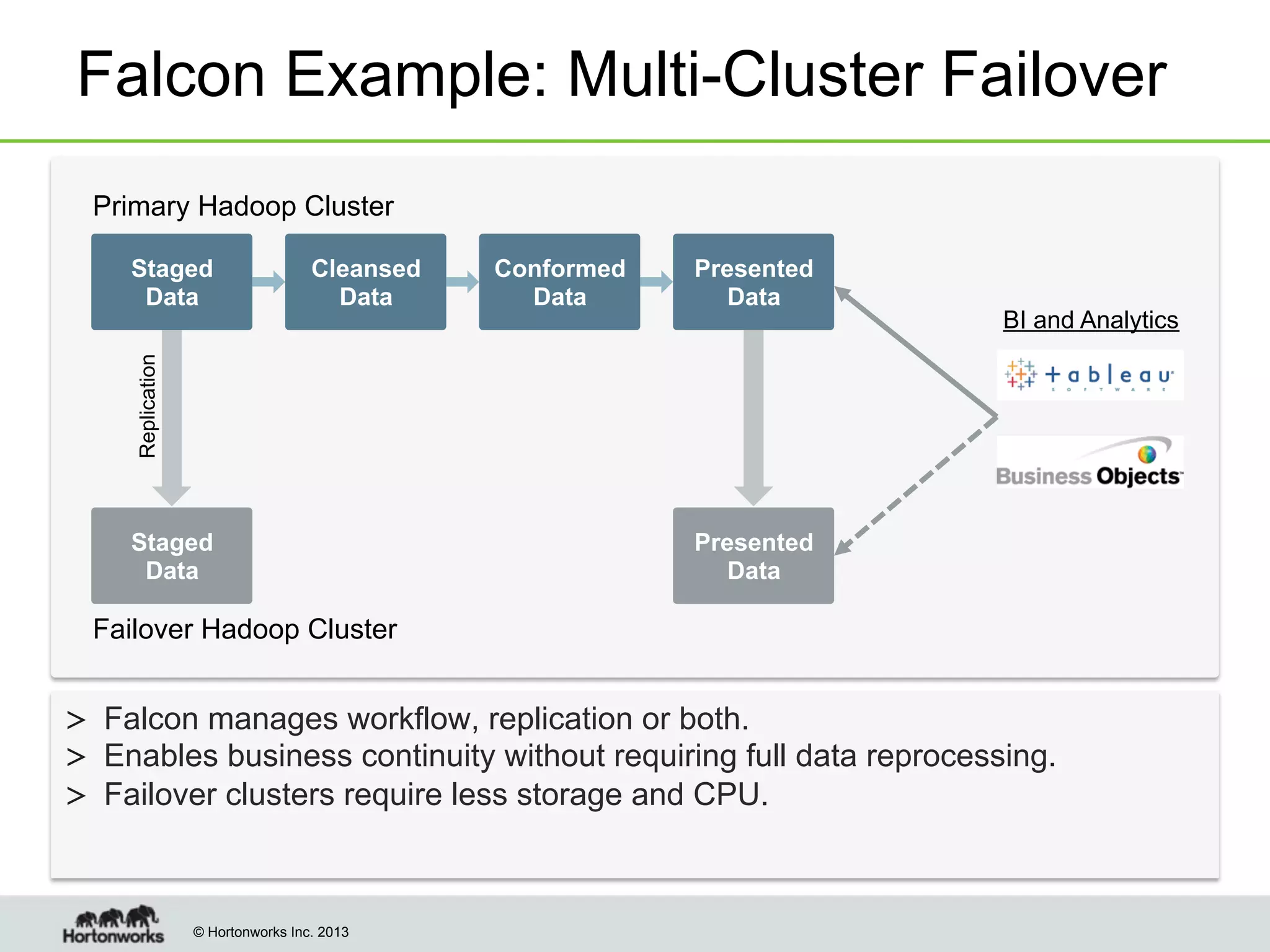
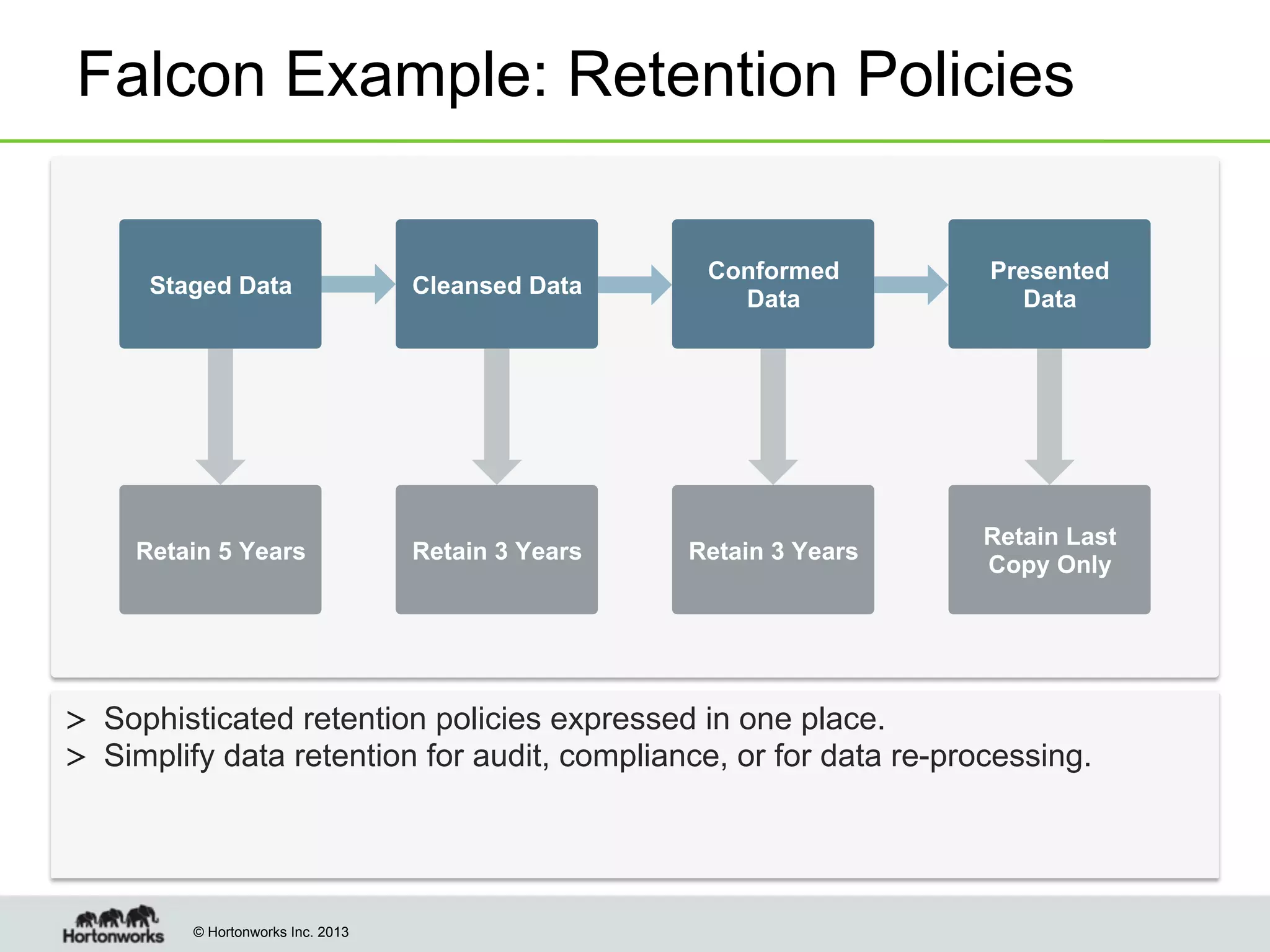
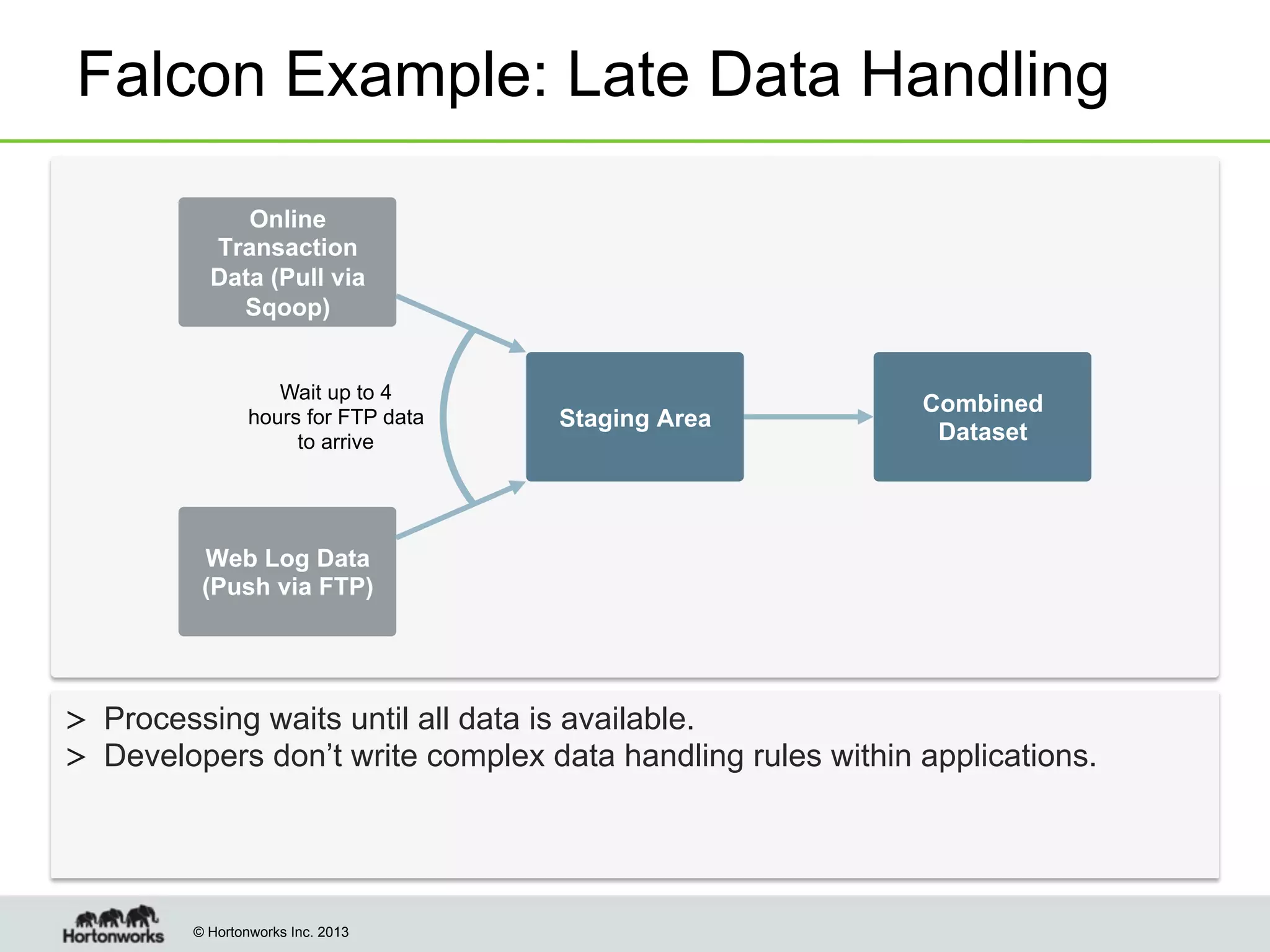



The document outlines the history, current capabilities, and future developments of Apache Hadoop, detailing its evolution from Hadoop 1 to Hadoop 2, which supports larger clusters and improved resource management through YARN. Key features and tools, such as Apache Tez for efficient processing, the Knox security framework, and Falcon for data lifecycle management, are highlighted. It emphasizes Hadoop's role in enterprise data solutions and its community-driven enhancements.




























































































