

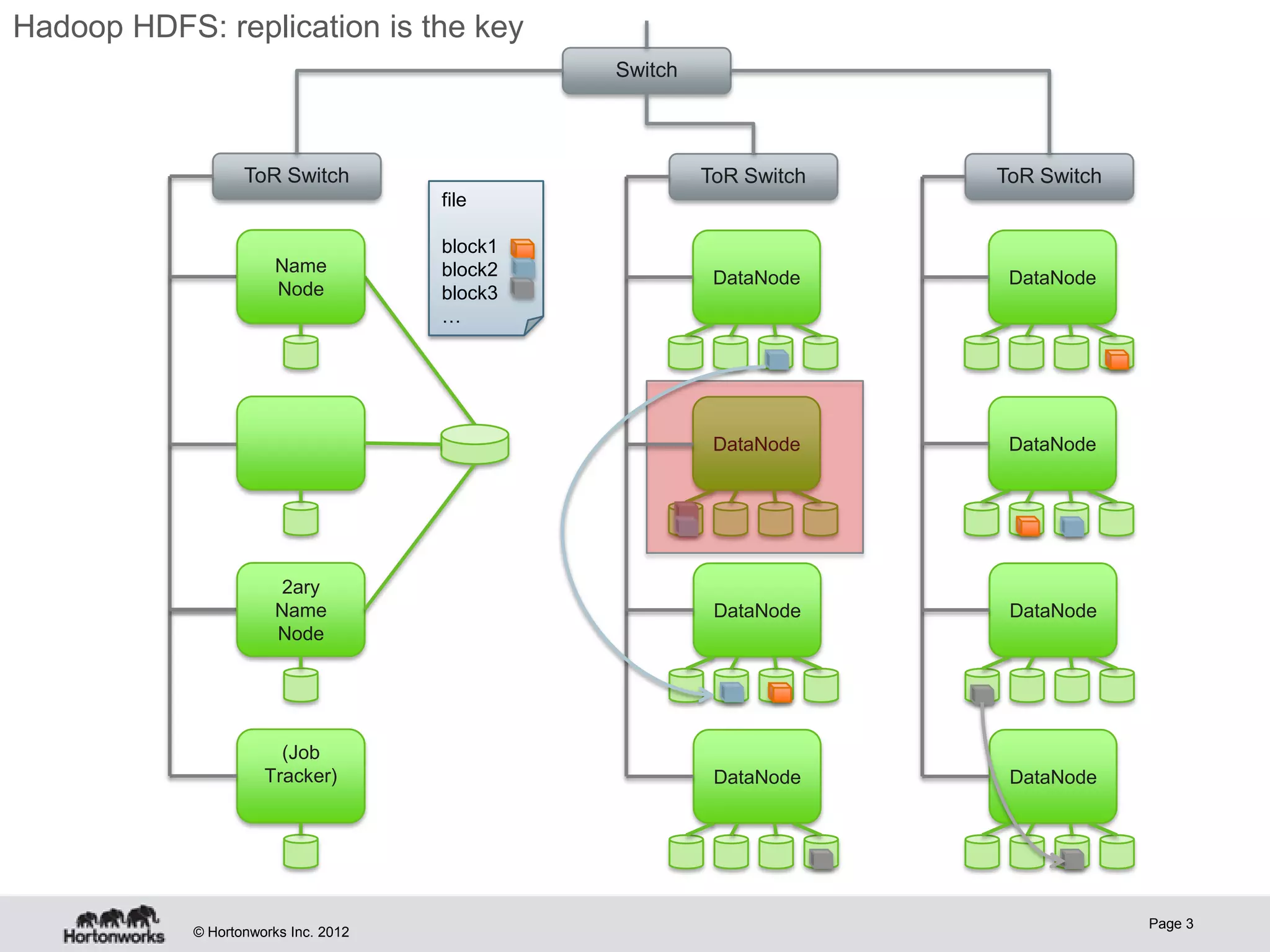

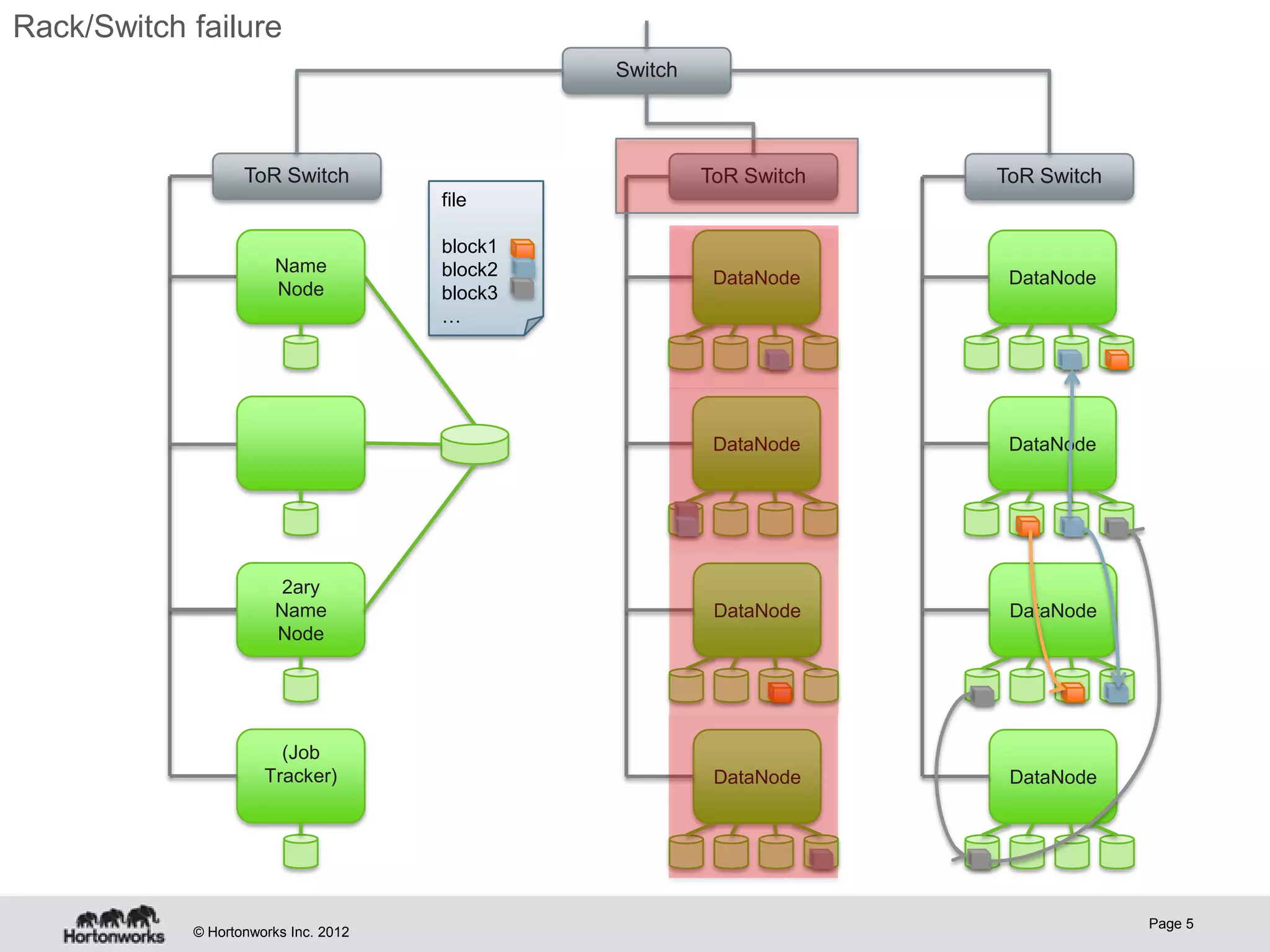

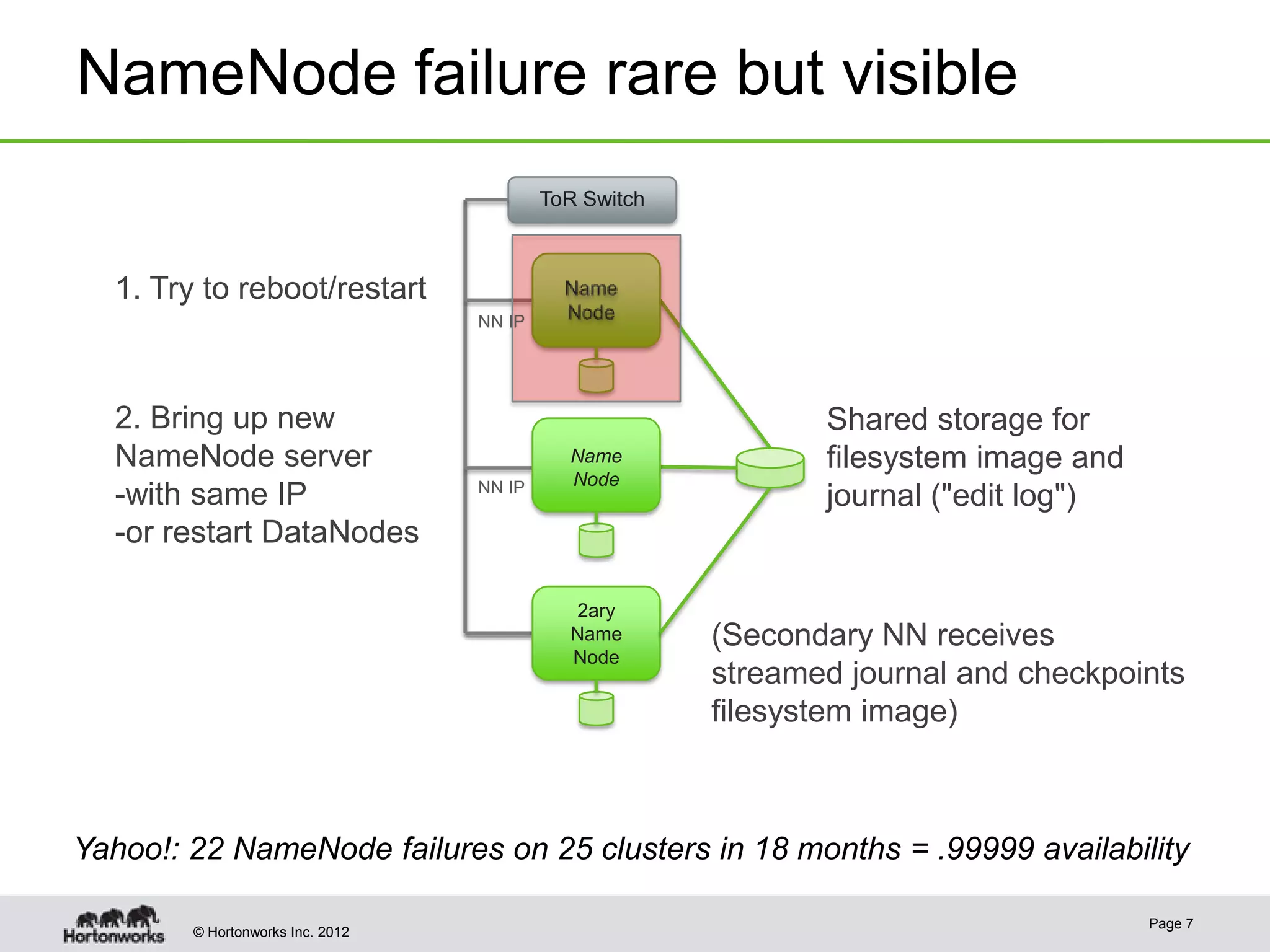



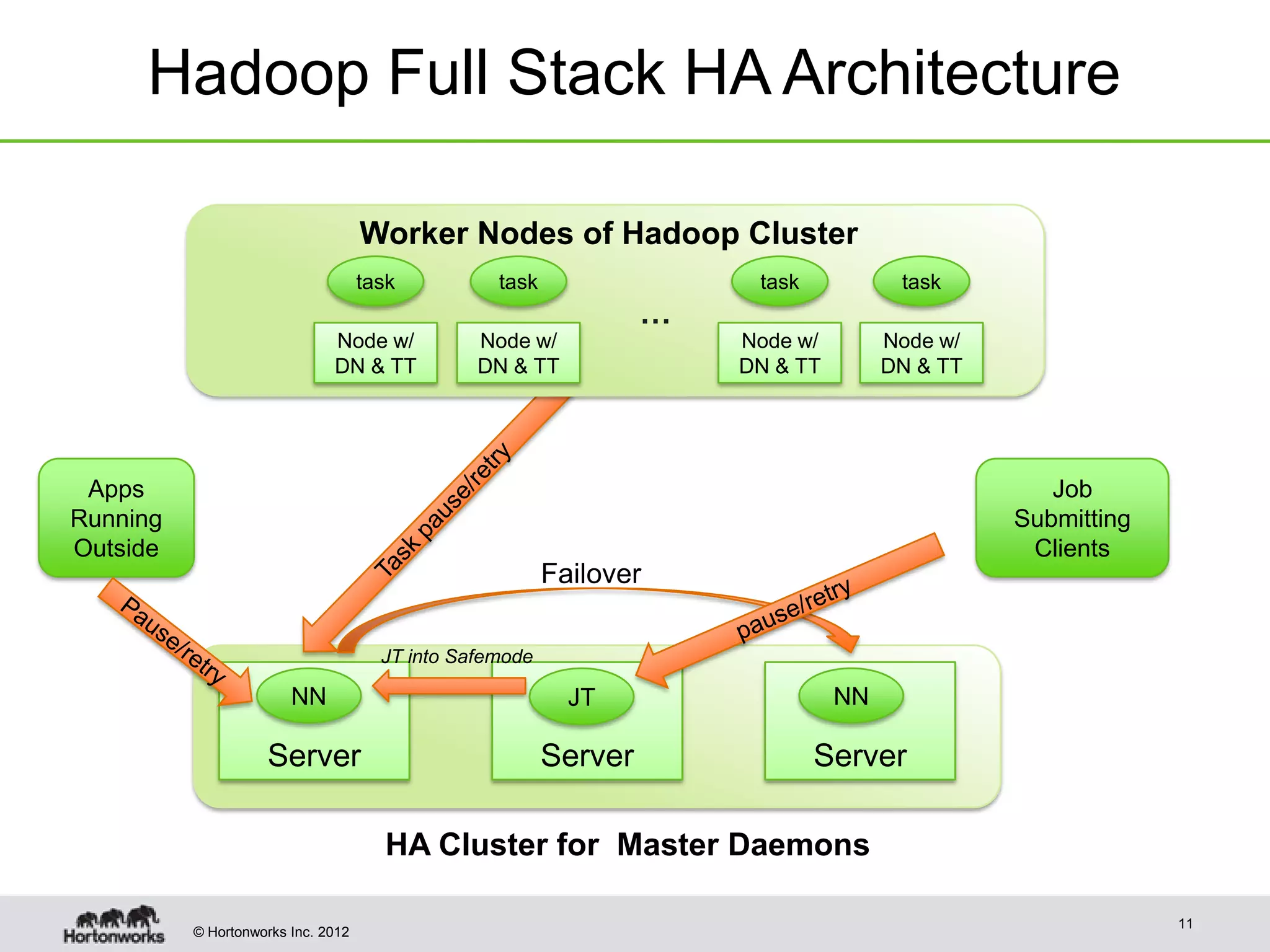

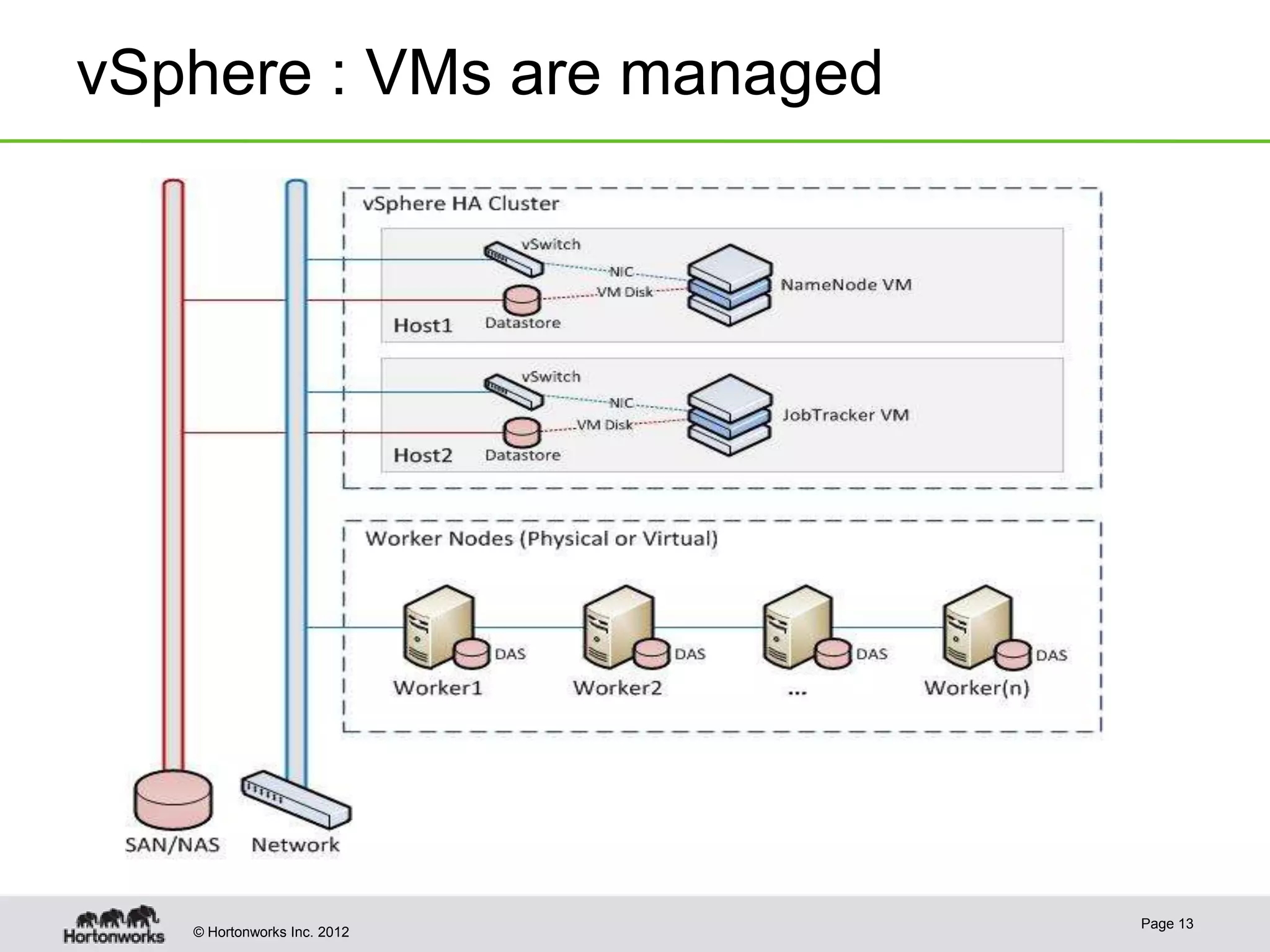


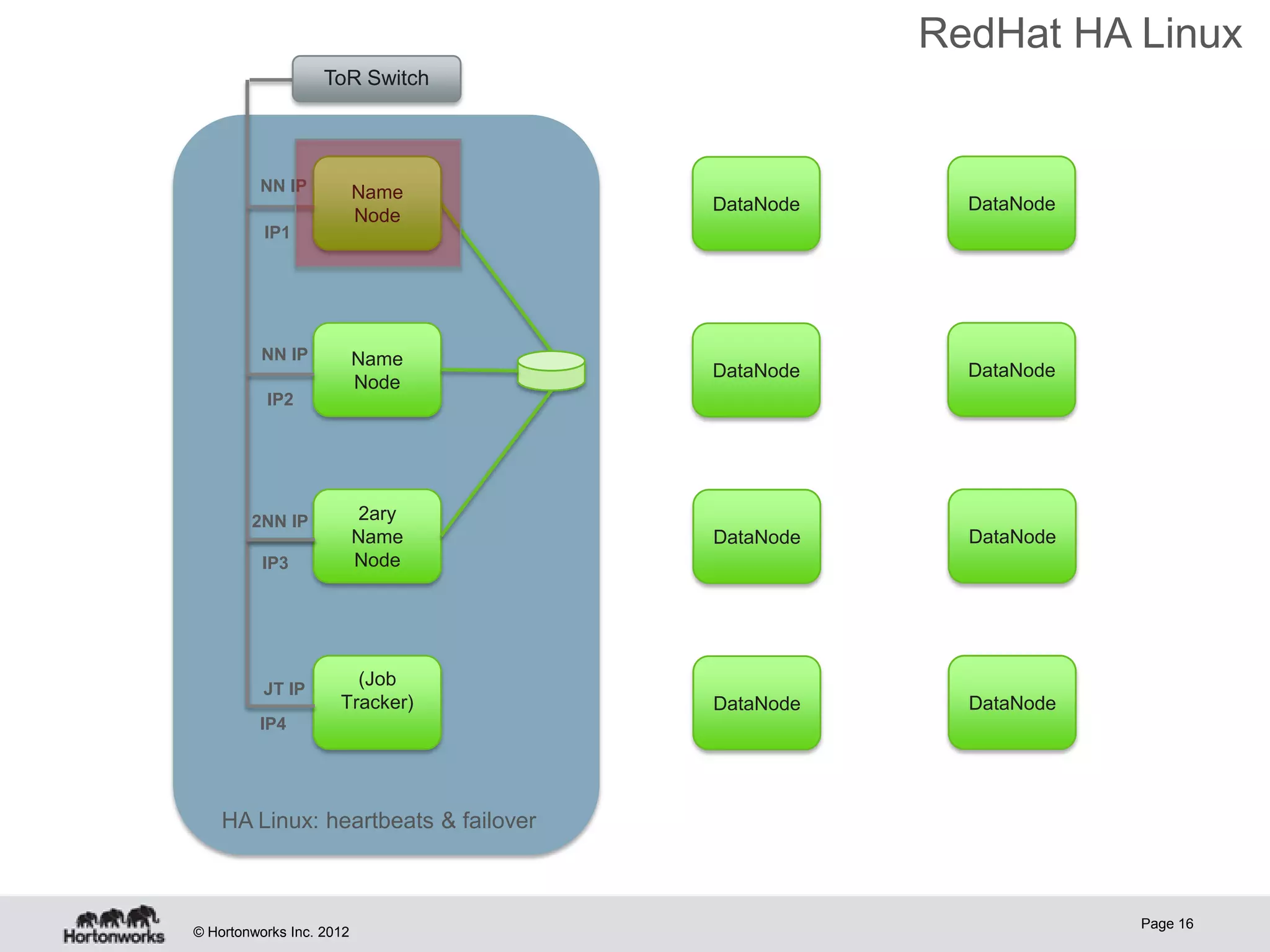






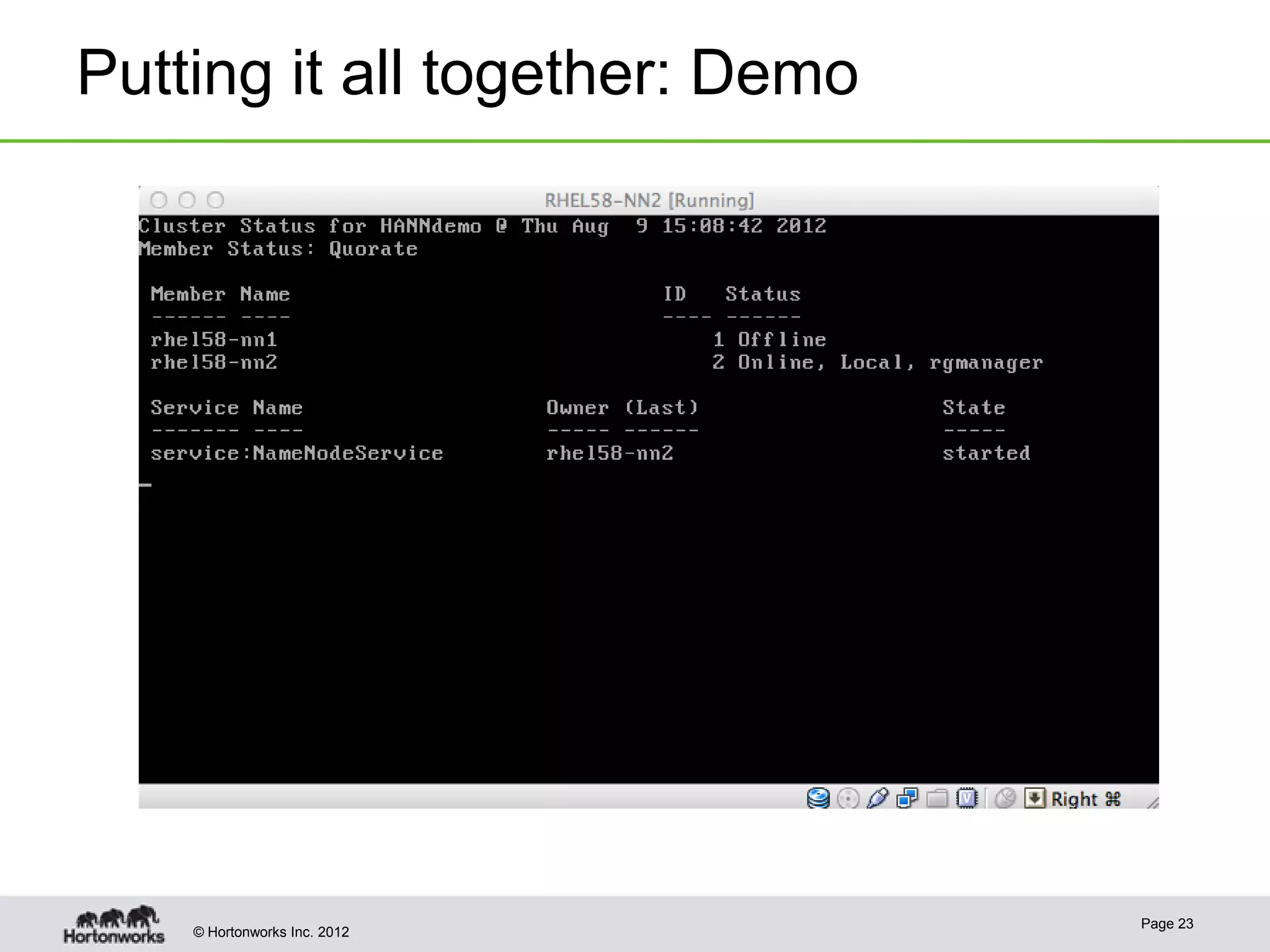

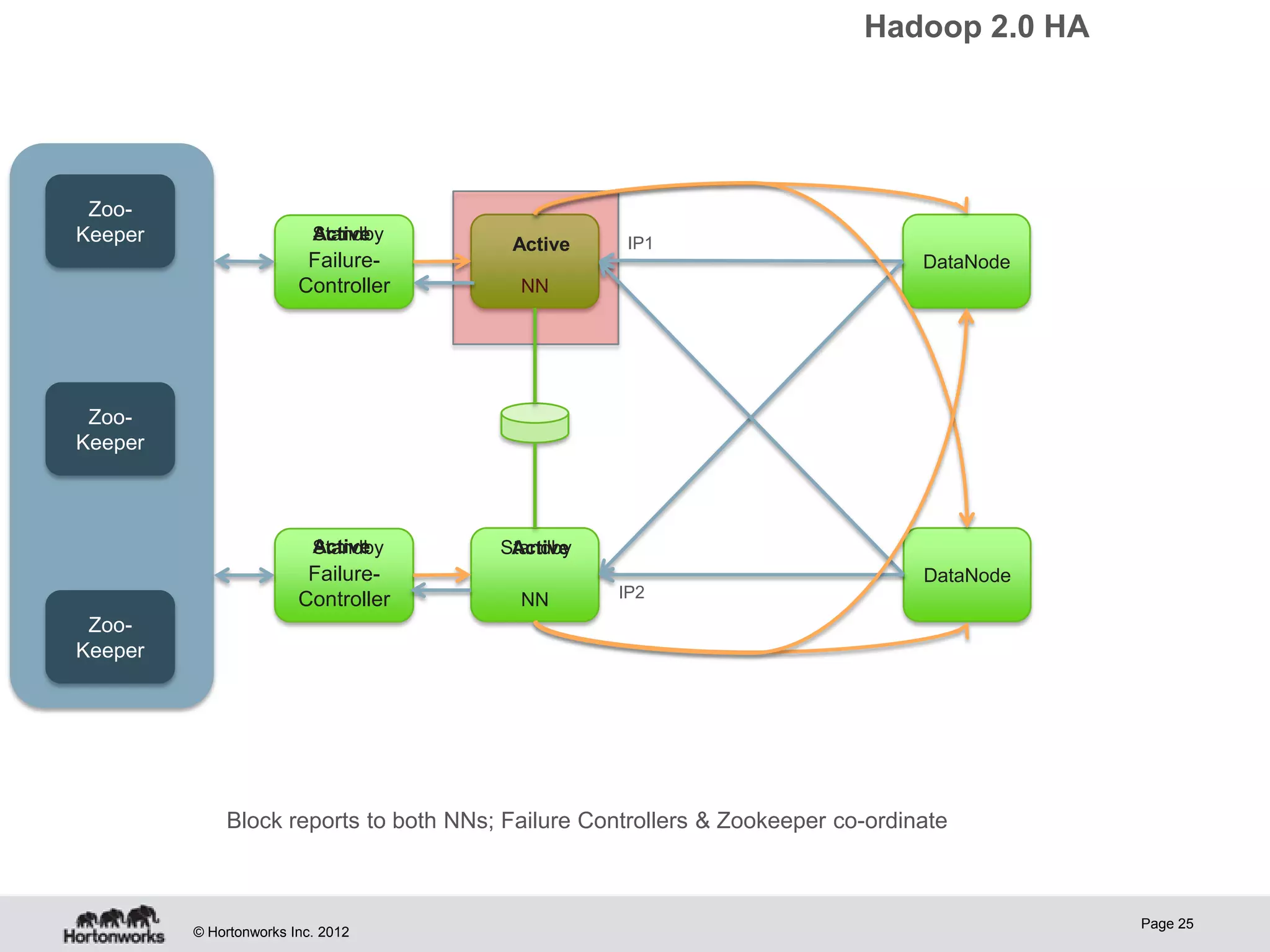
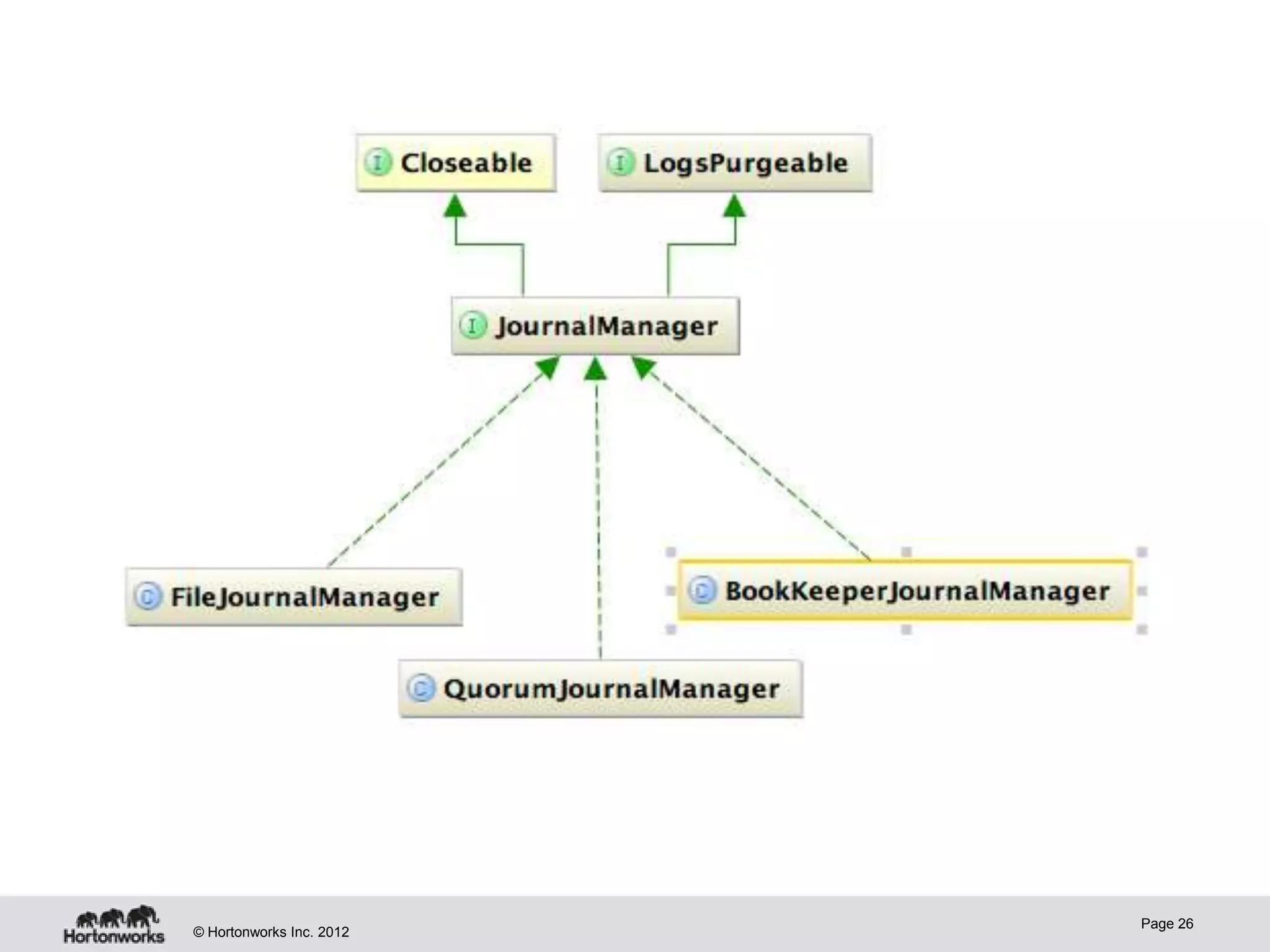
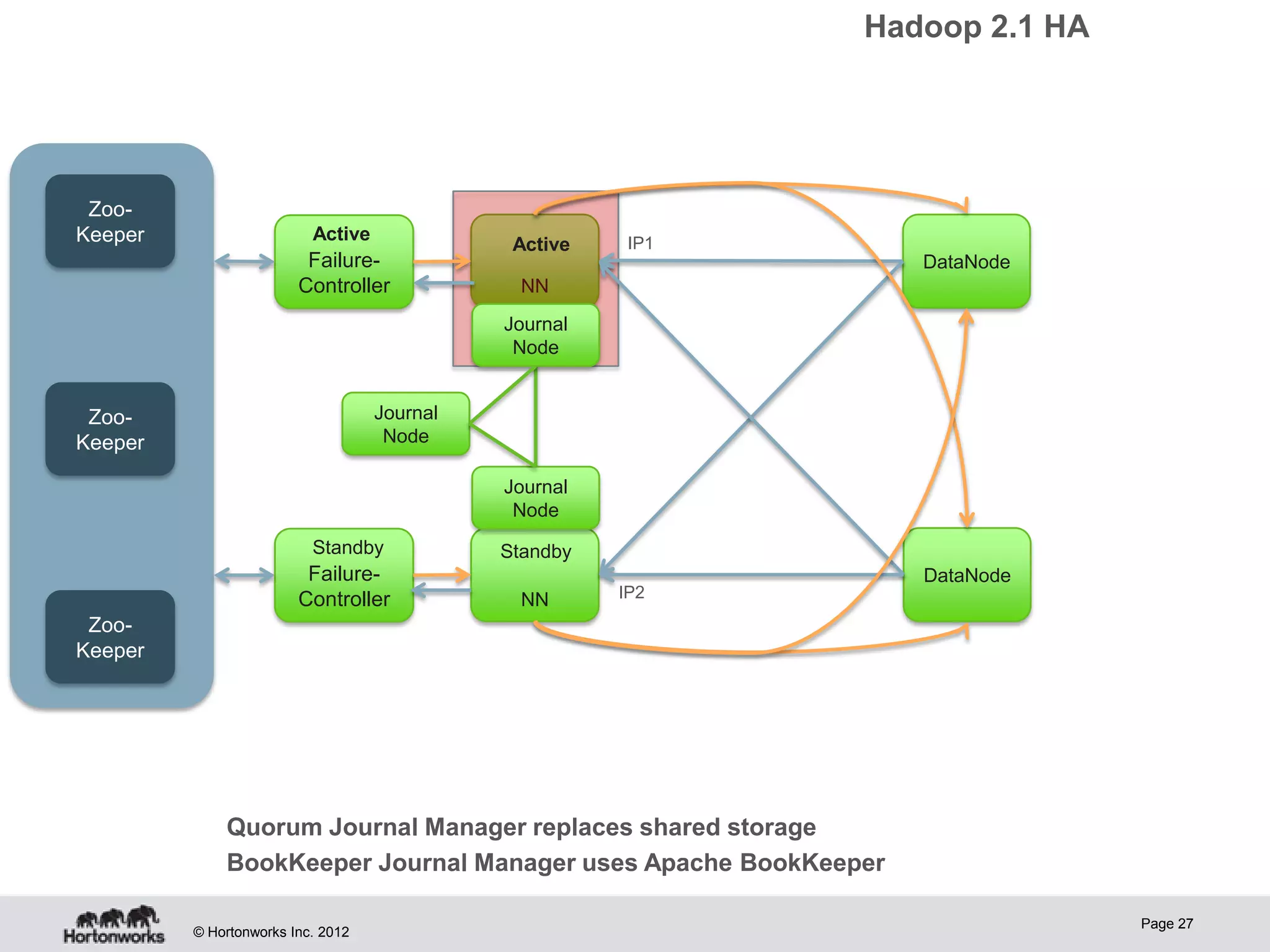




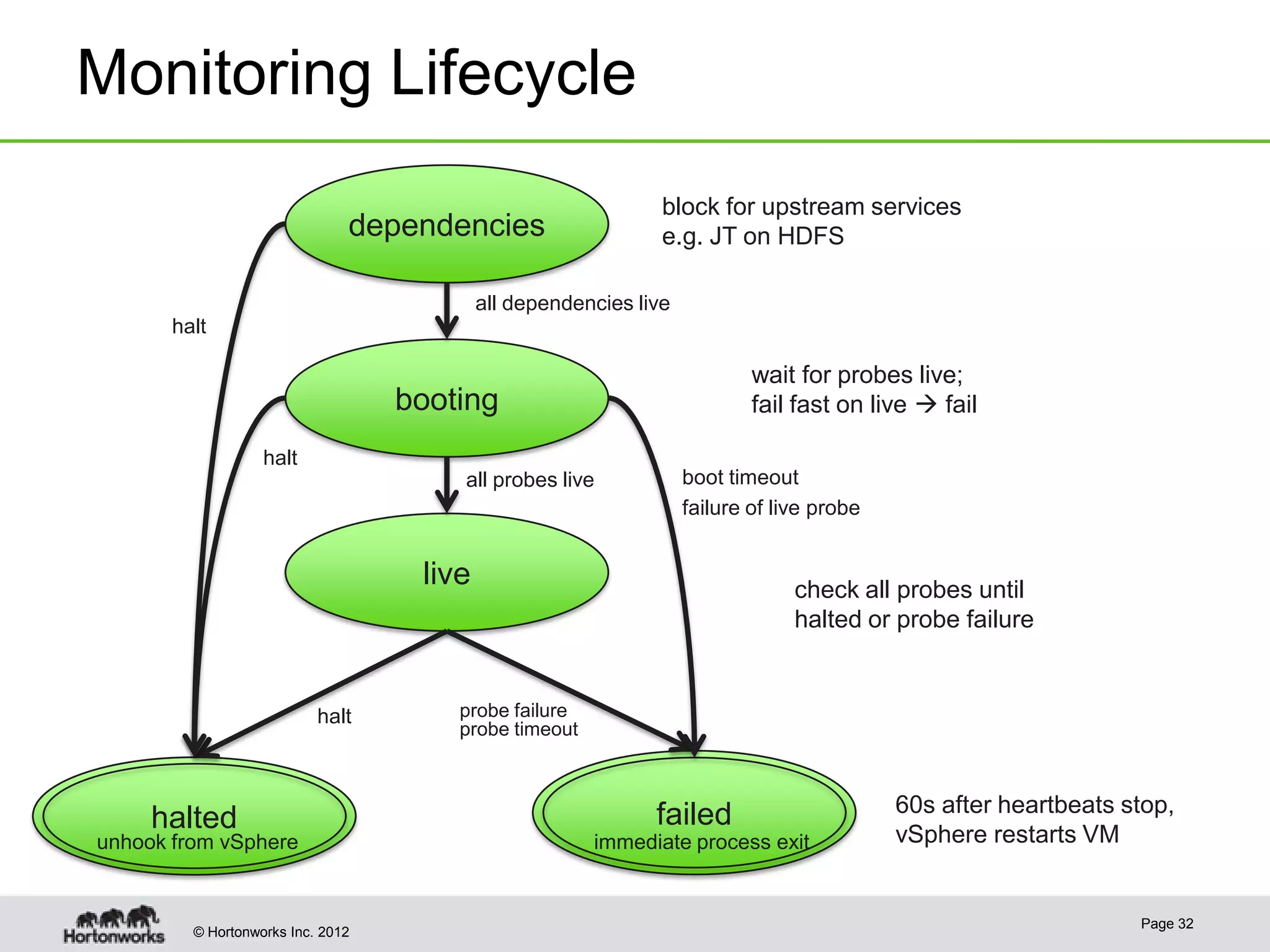


Hadoop provides high availability through replication of data across multiple nodes. Replication handles data integrity through checksums and automatic re-replication of corrupt blocks. Rack failures are reduced by dual networking and more replication bandwidth. NameNode failures are rare but cause downtime, so Hadoop 1 adds cold failover of Namenodes using VMware HA or RedHat HA. Hadoop 2 introduces live failover of Namenodes using a quorum journal manager to eliminate single points of failure. Full stack high availability adds monitoring and restart of all services.

























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















