Downloaded 42 times




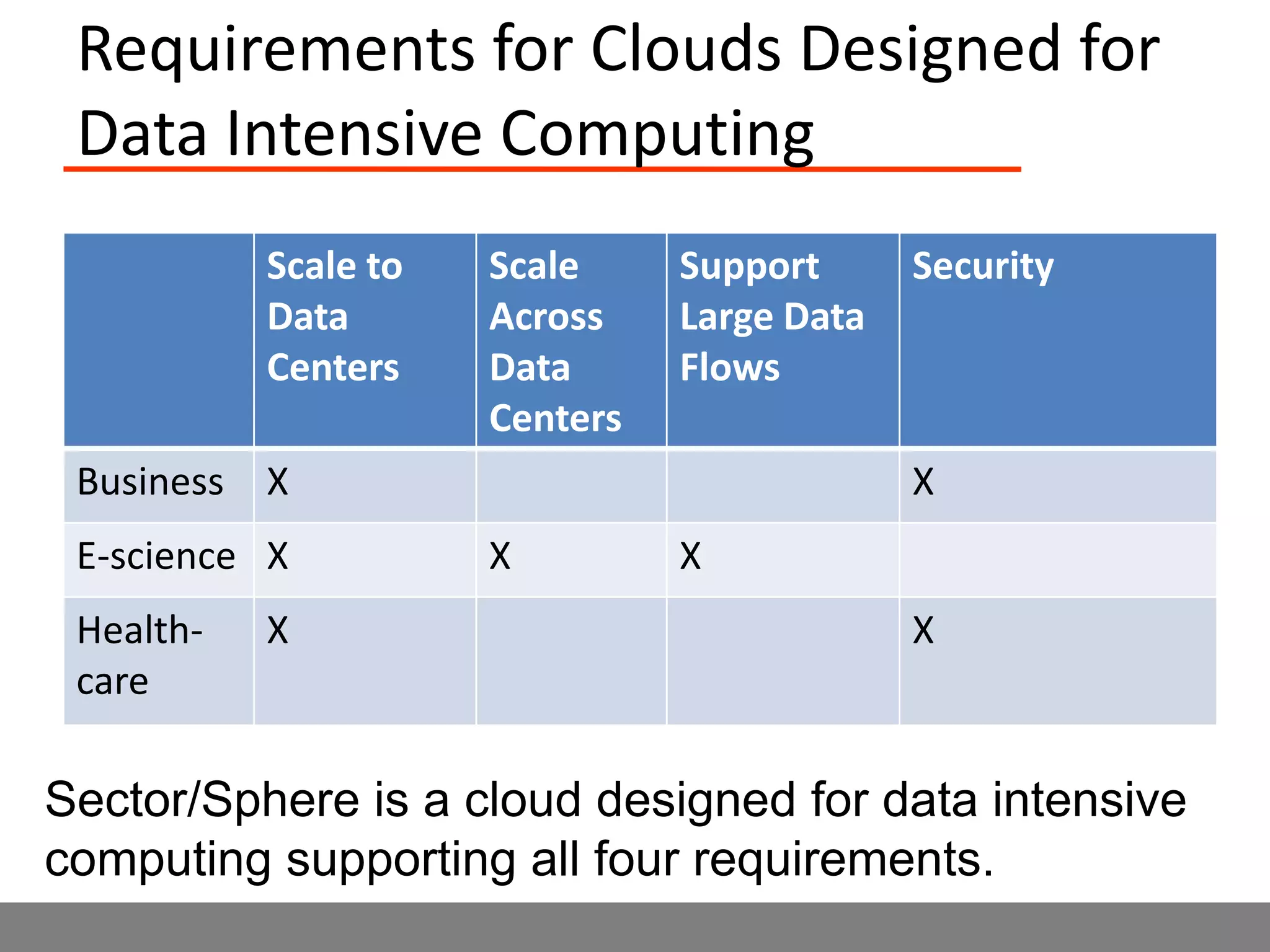

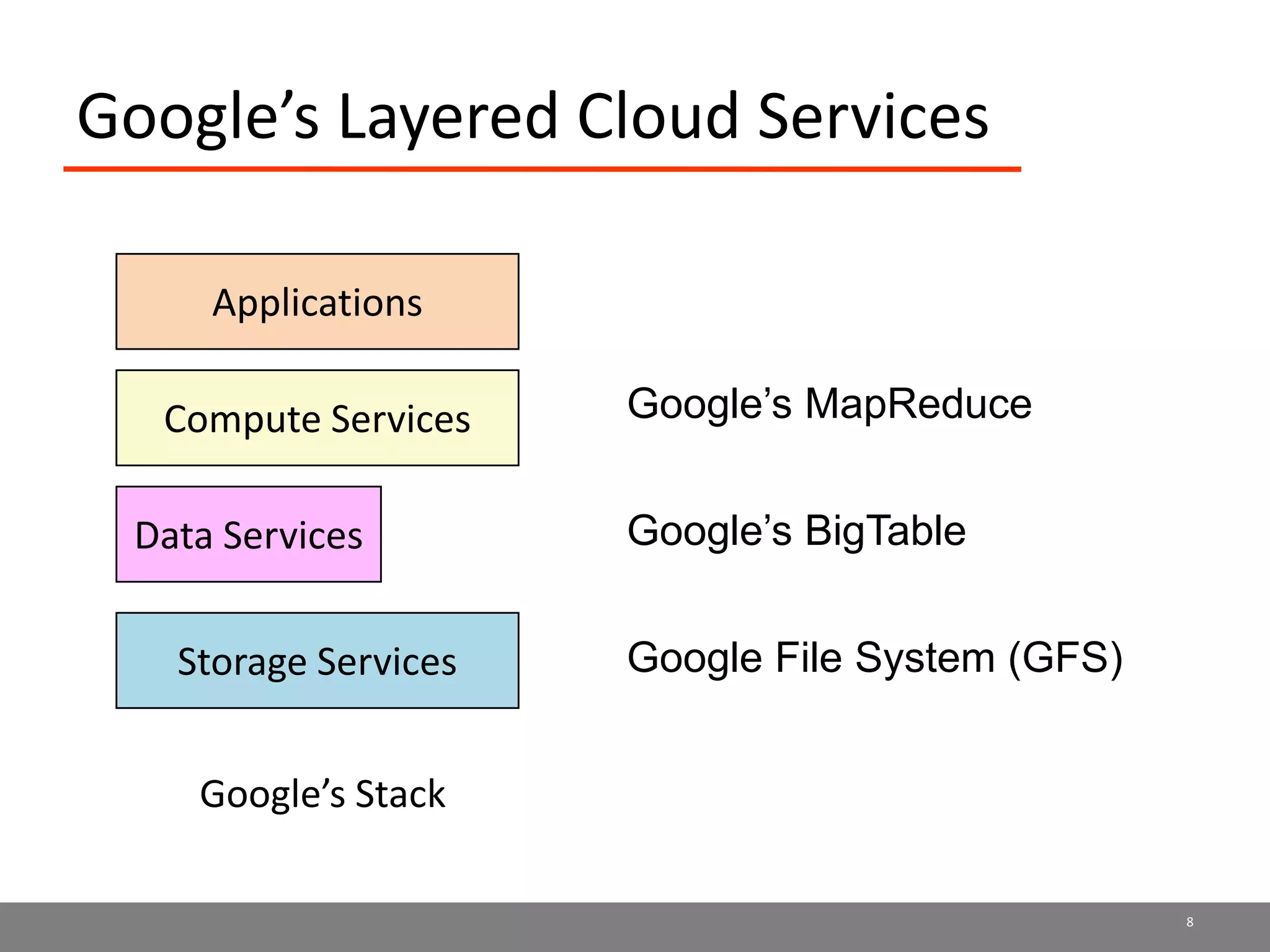
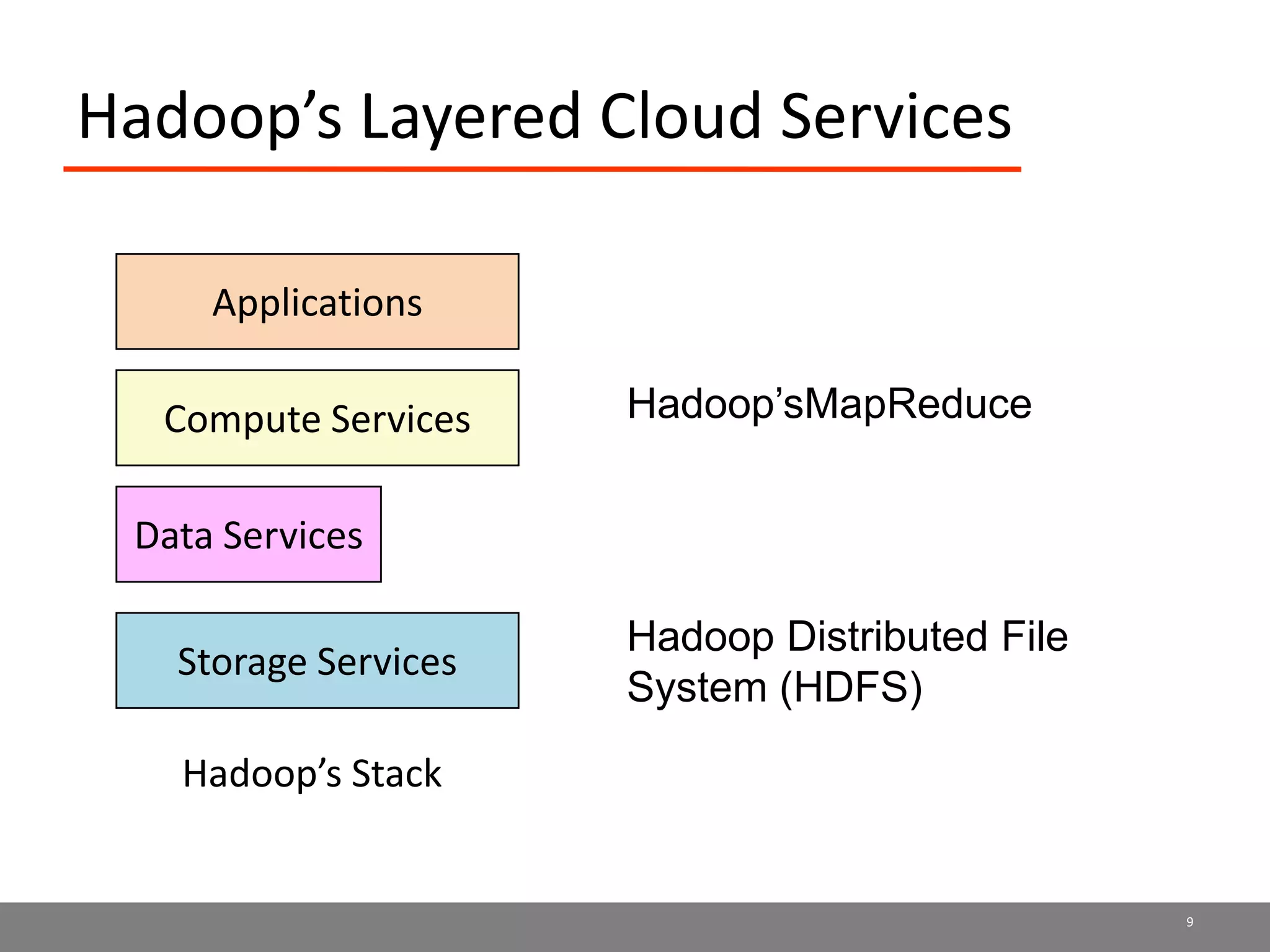
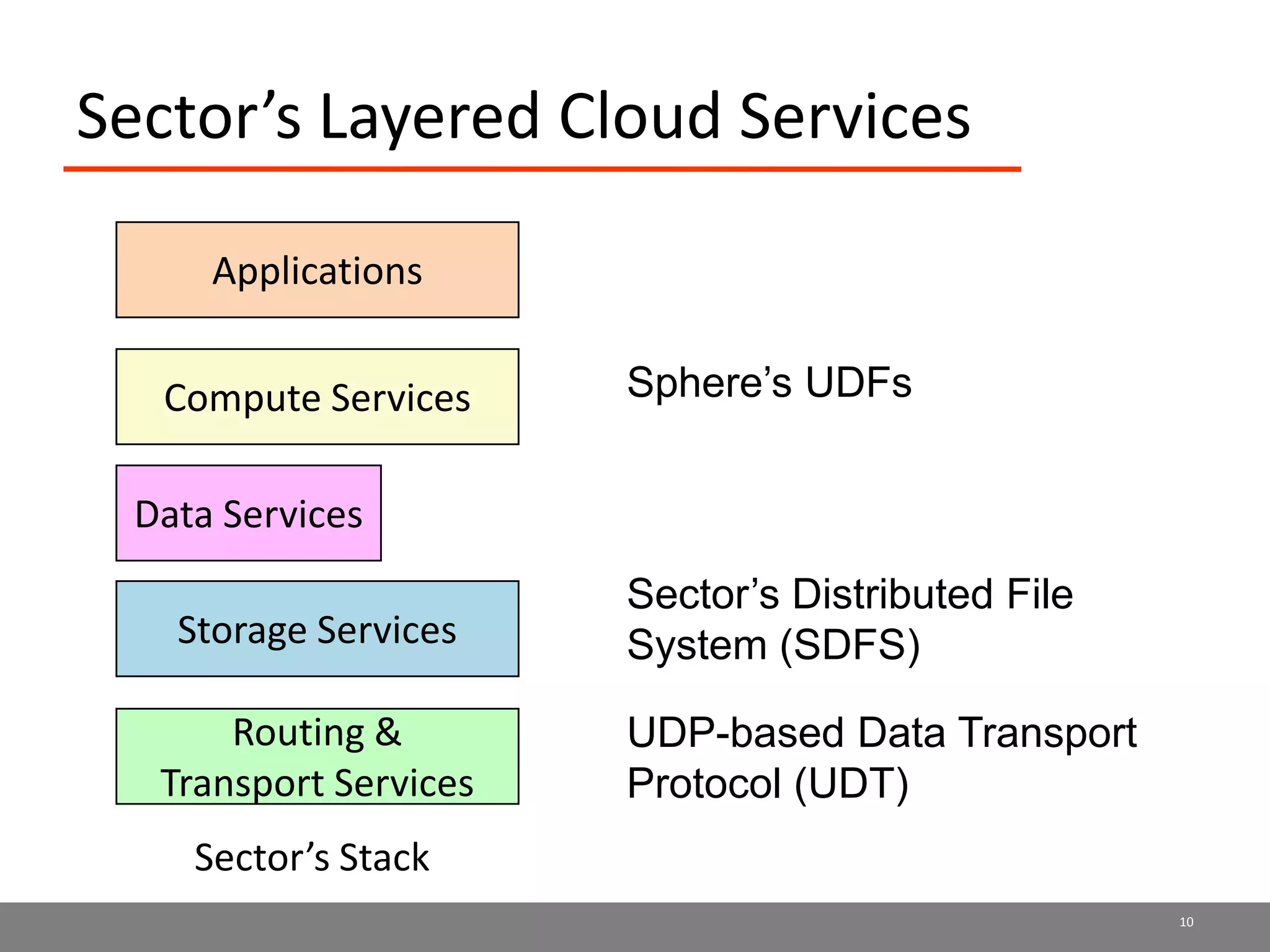
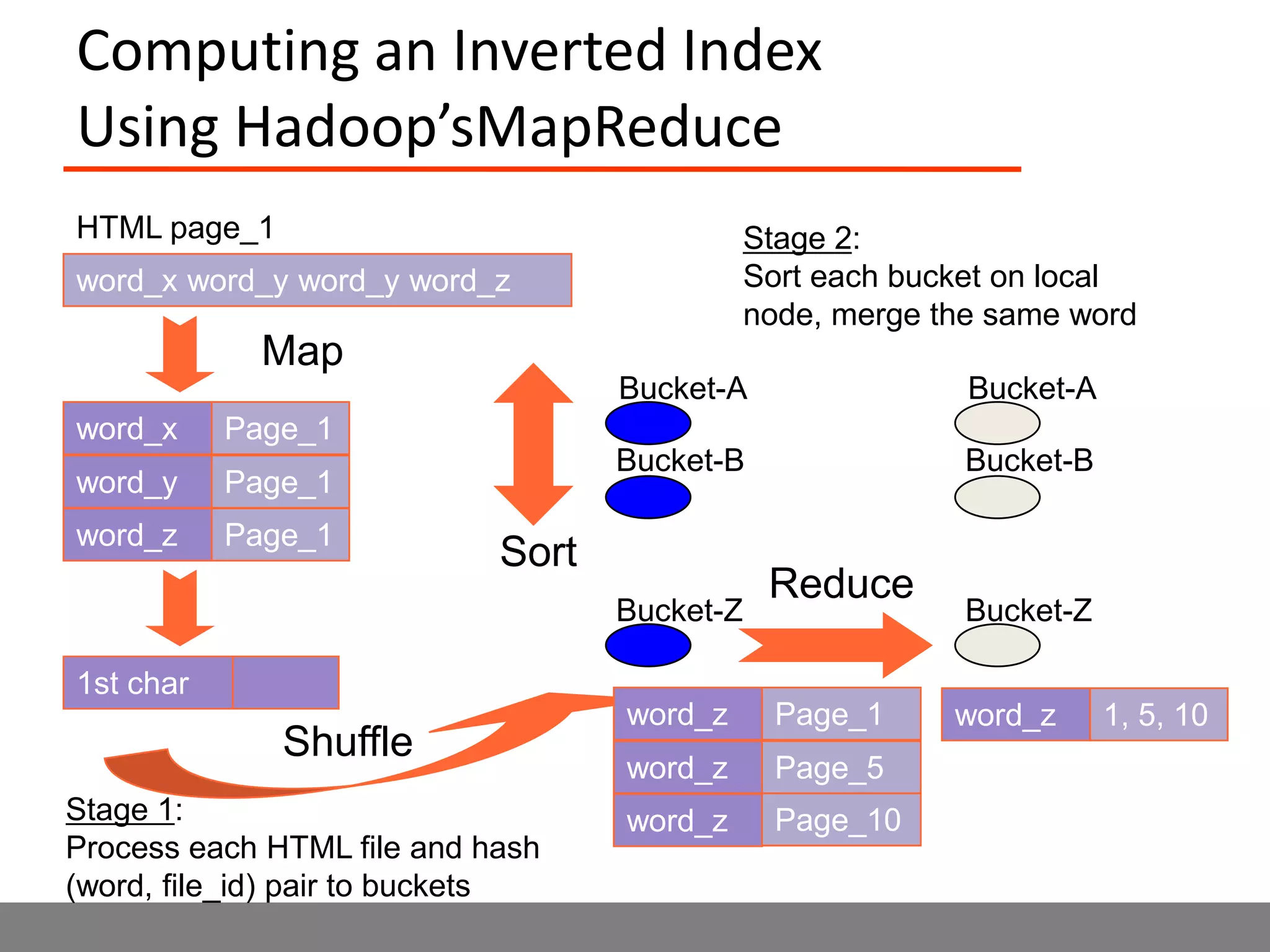

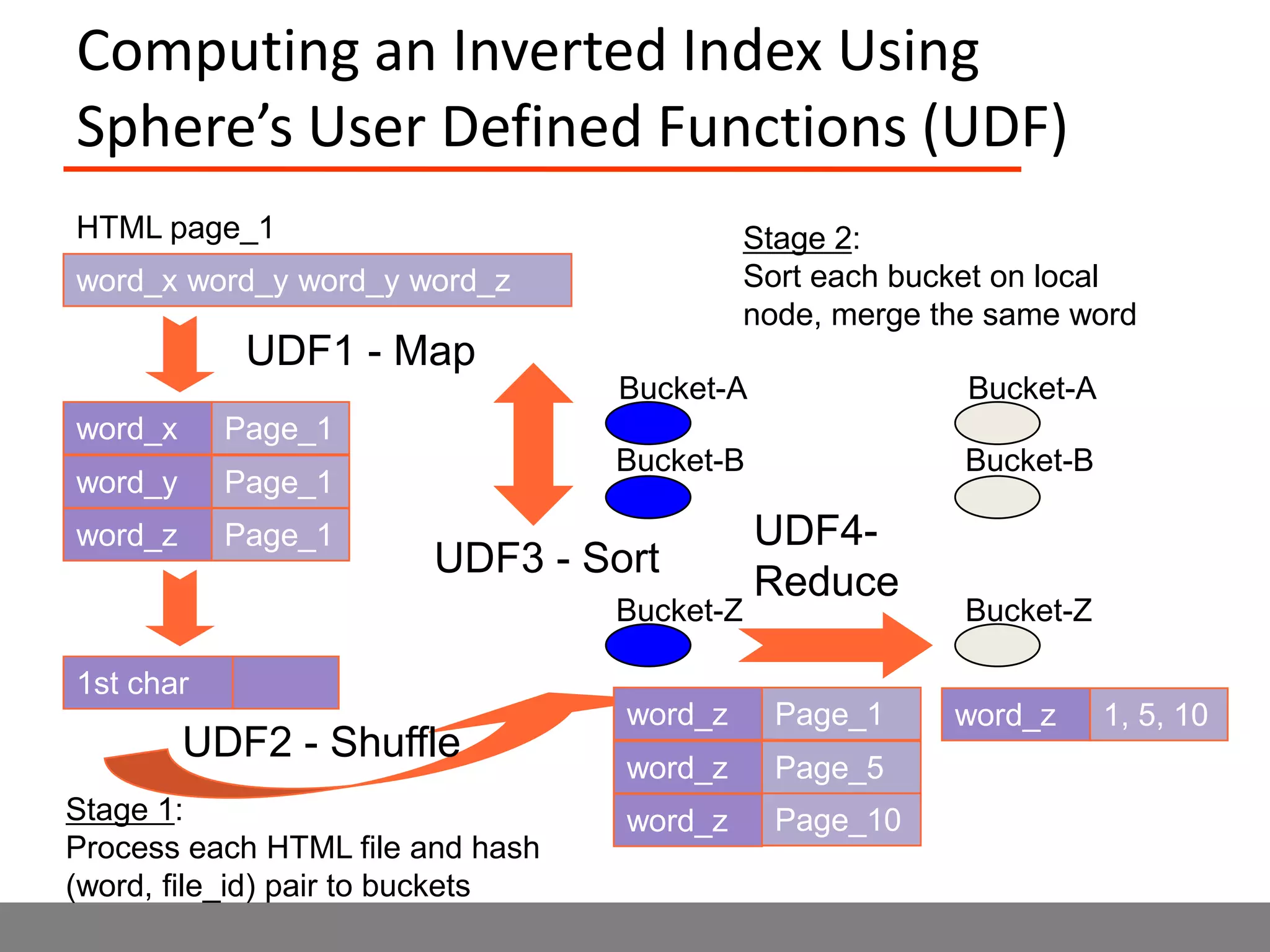
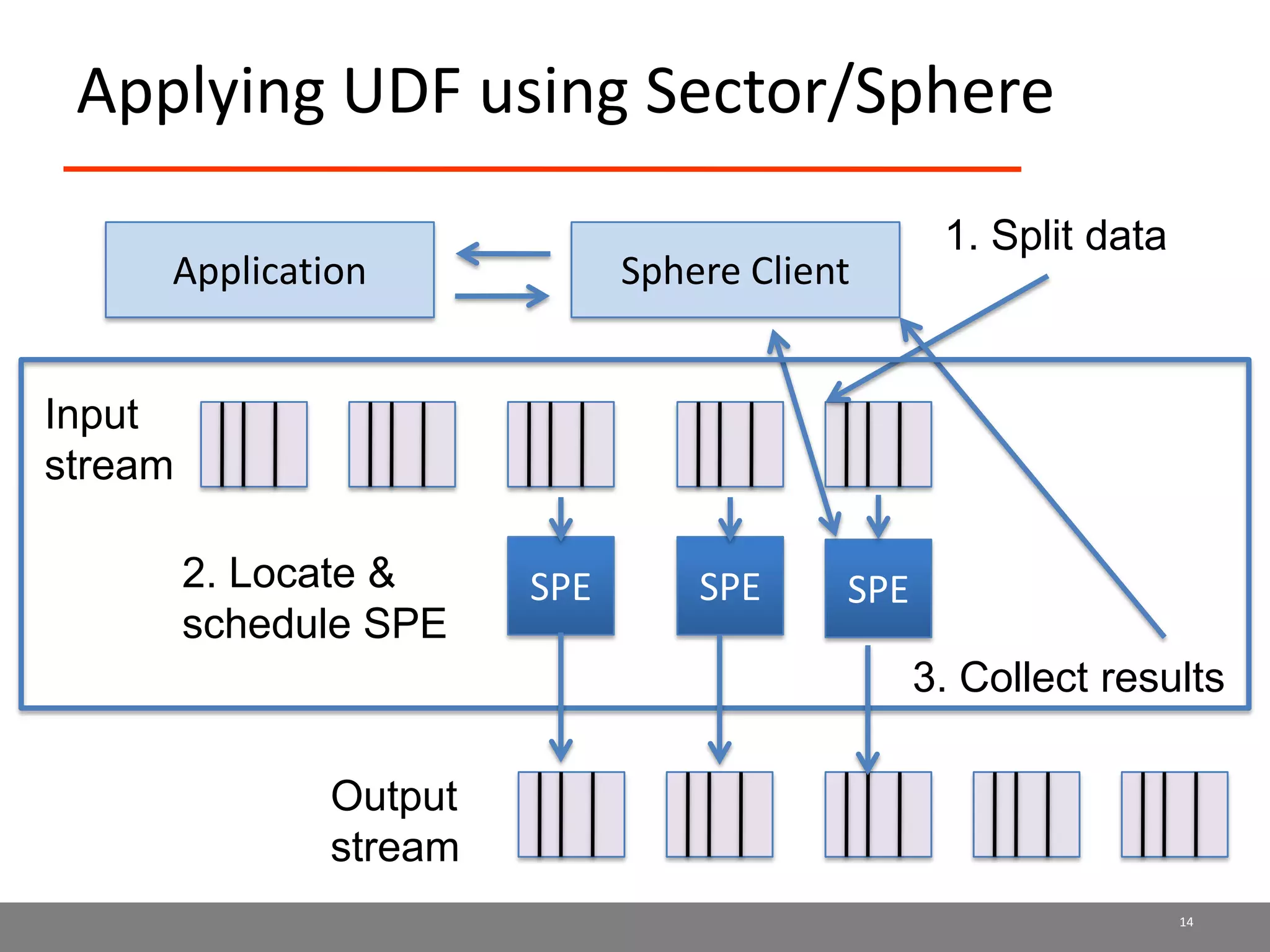
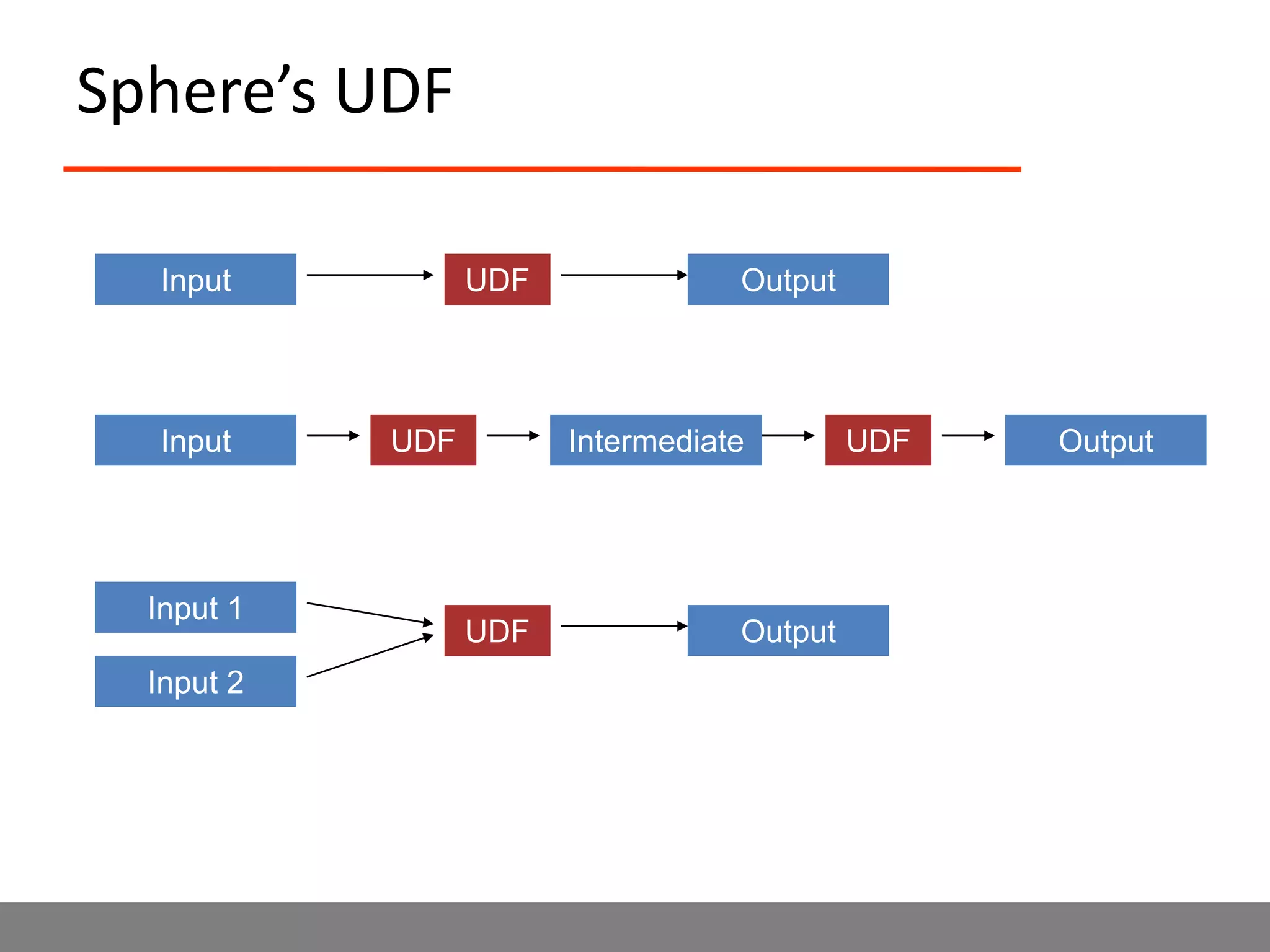

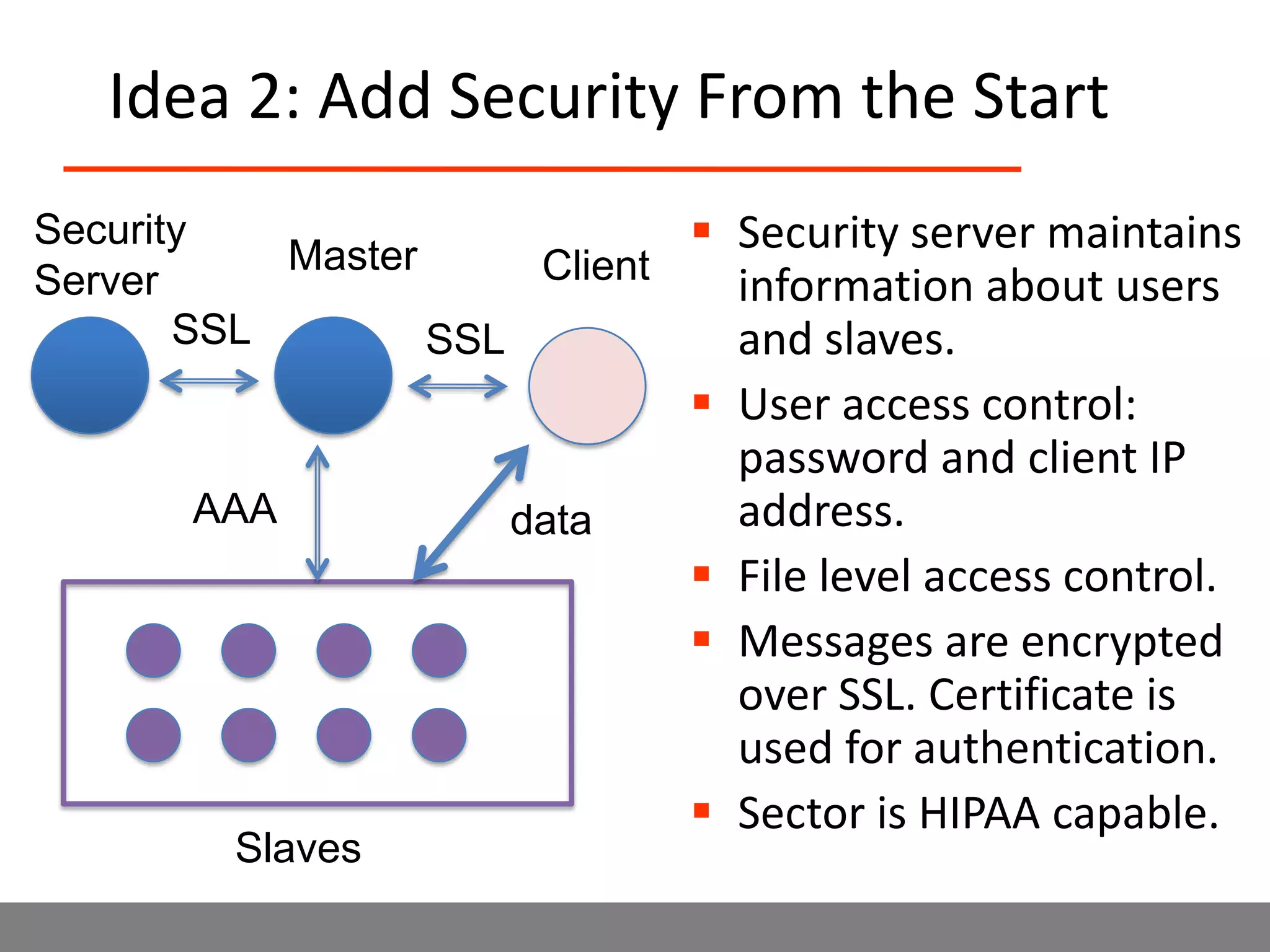
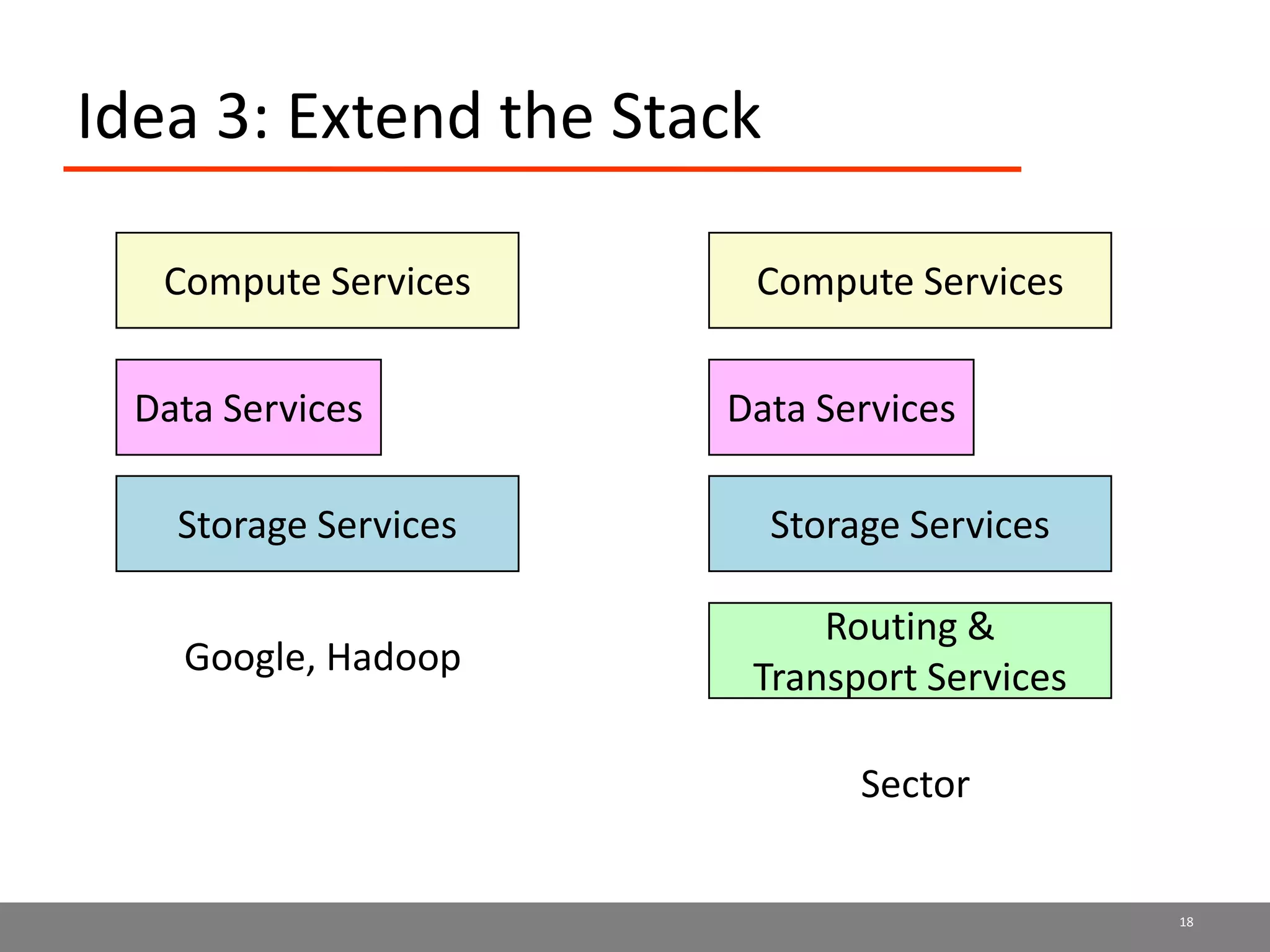

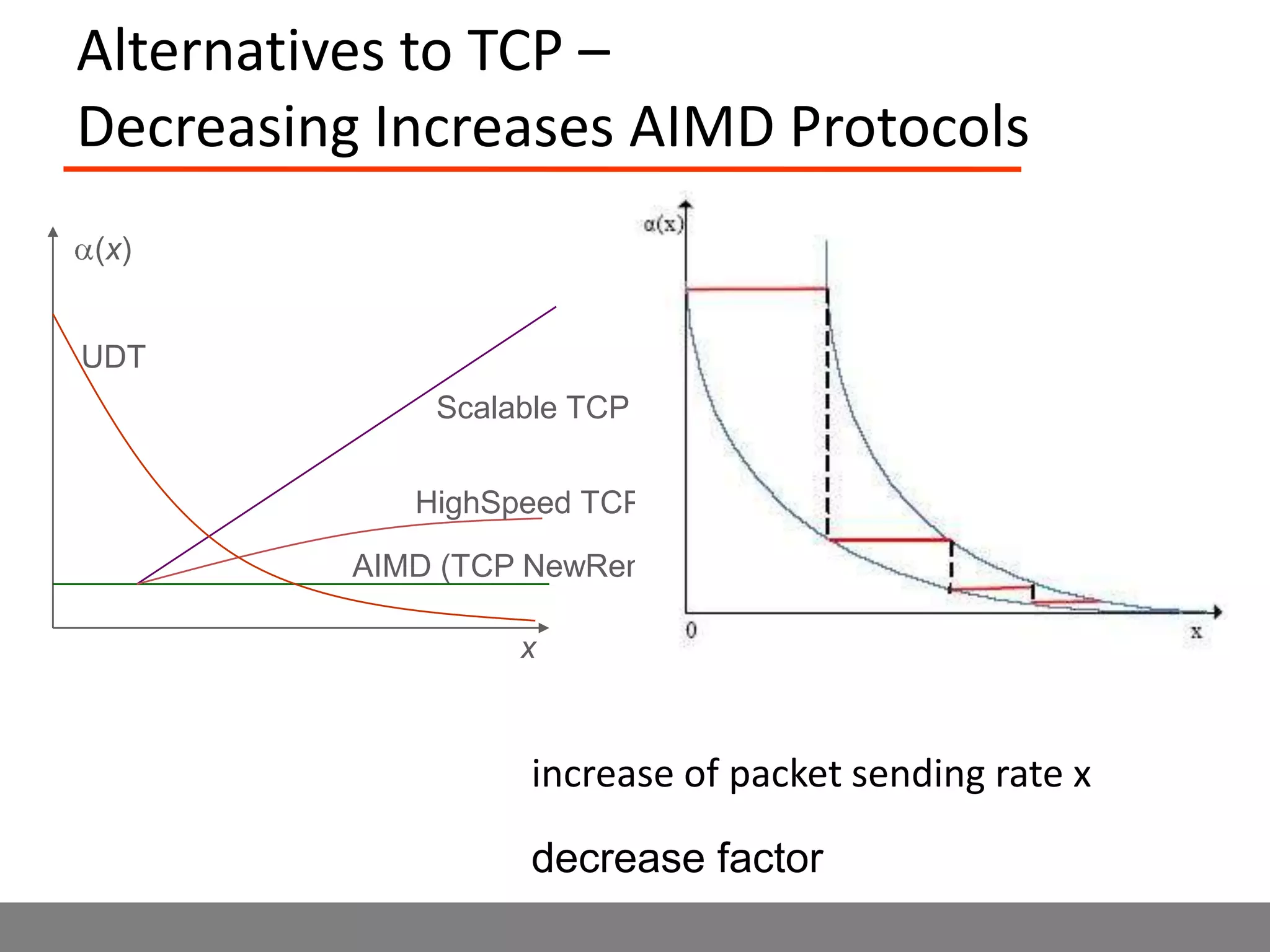
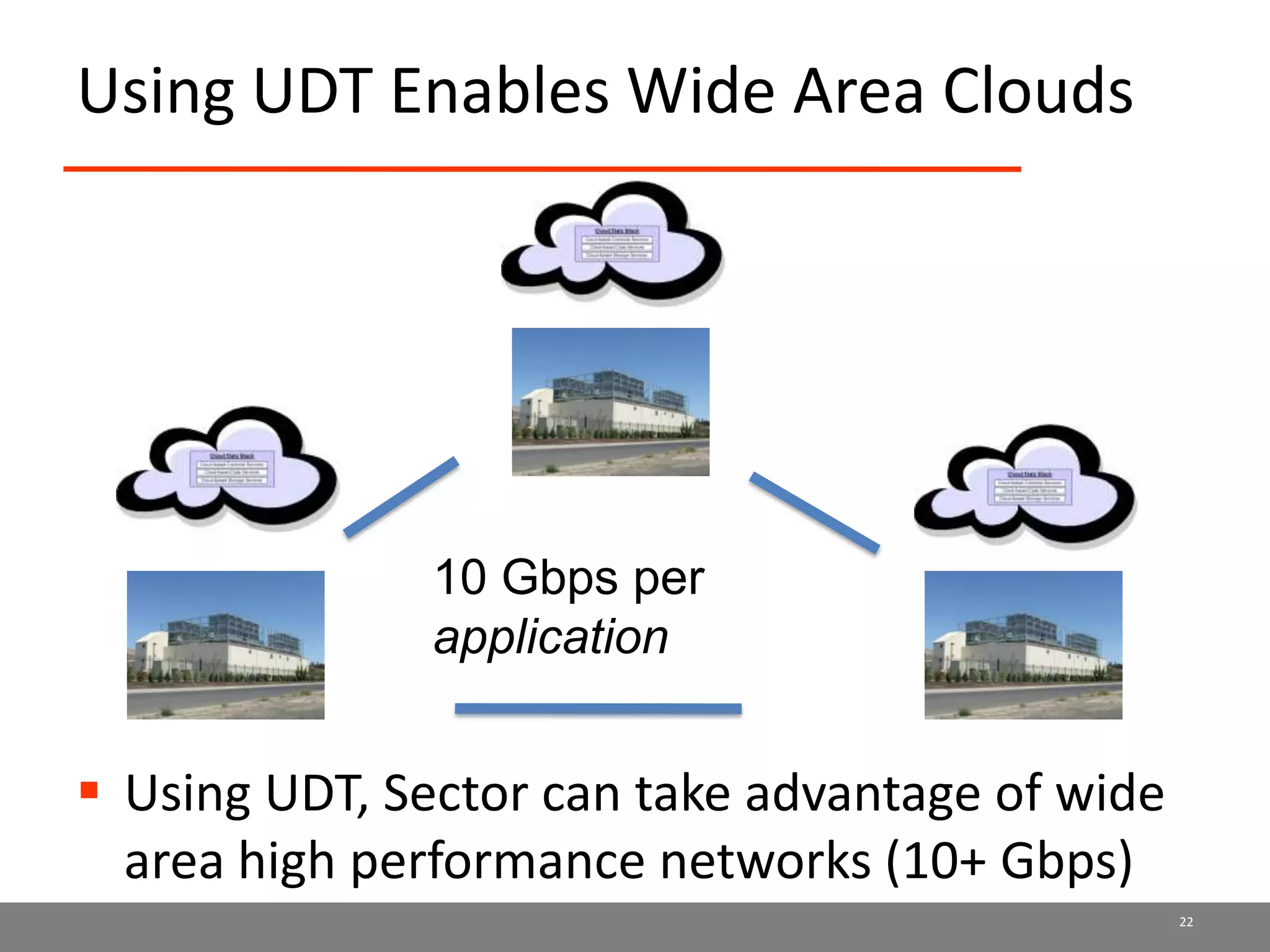




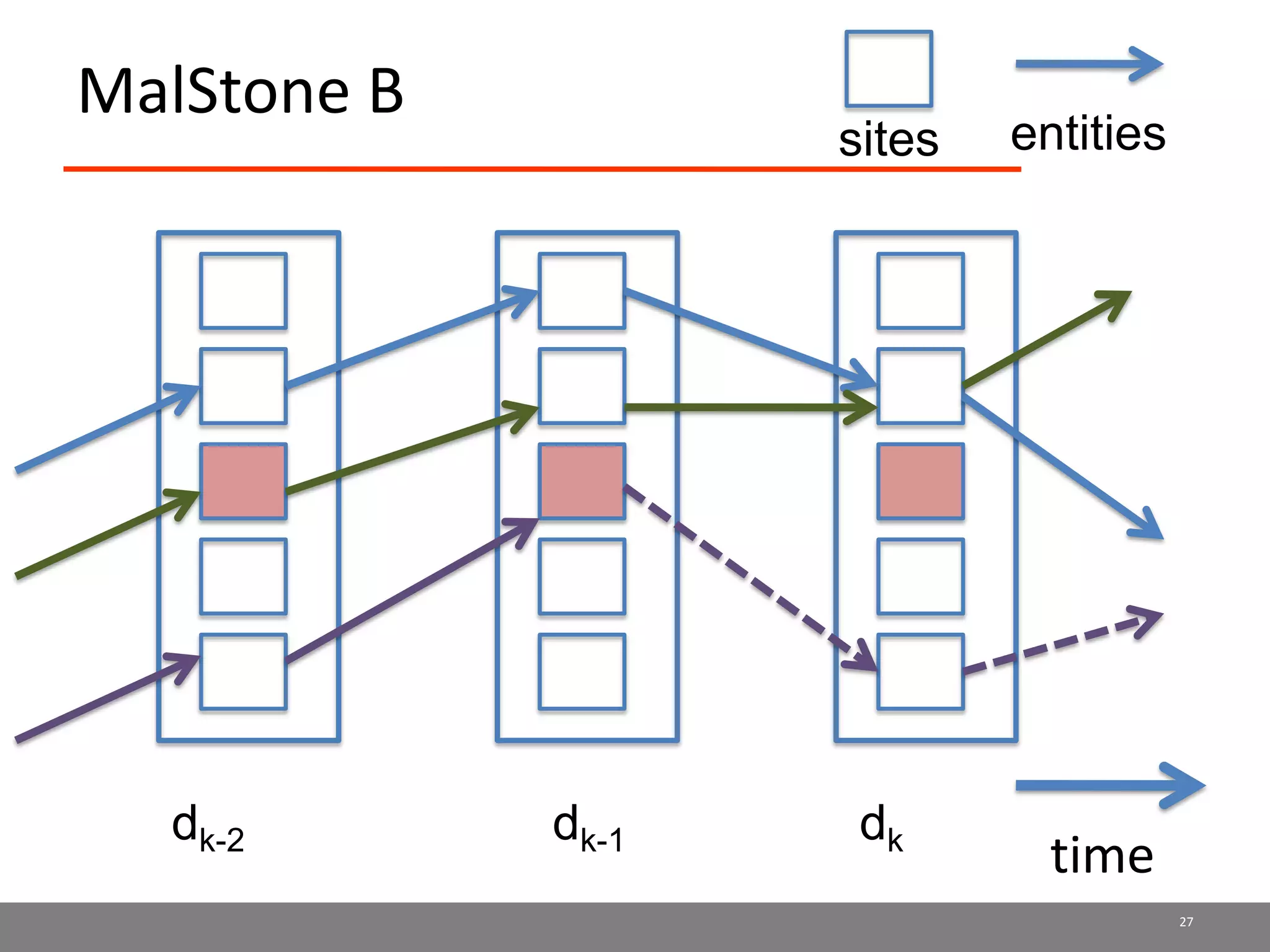
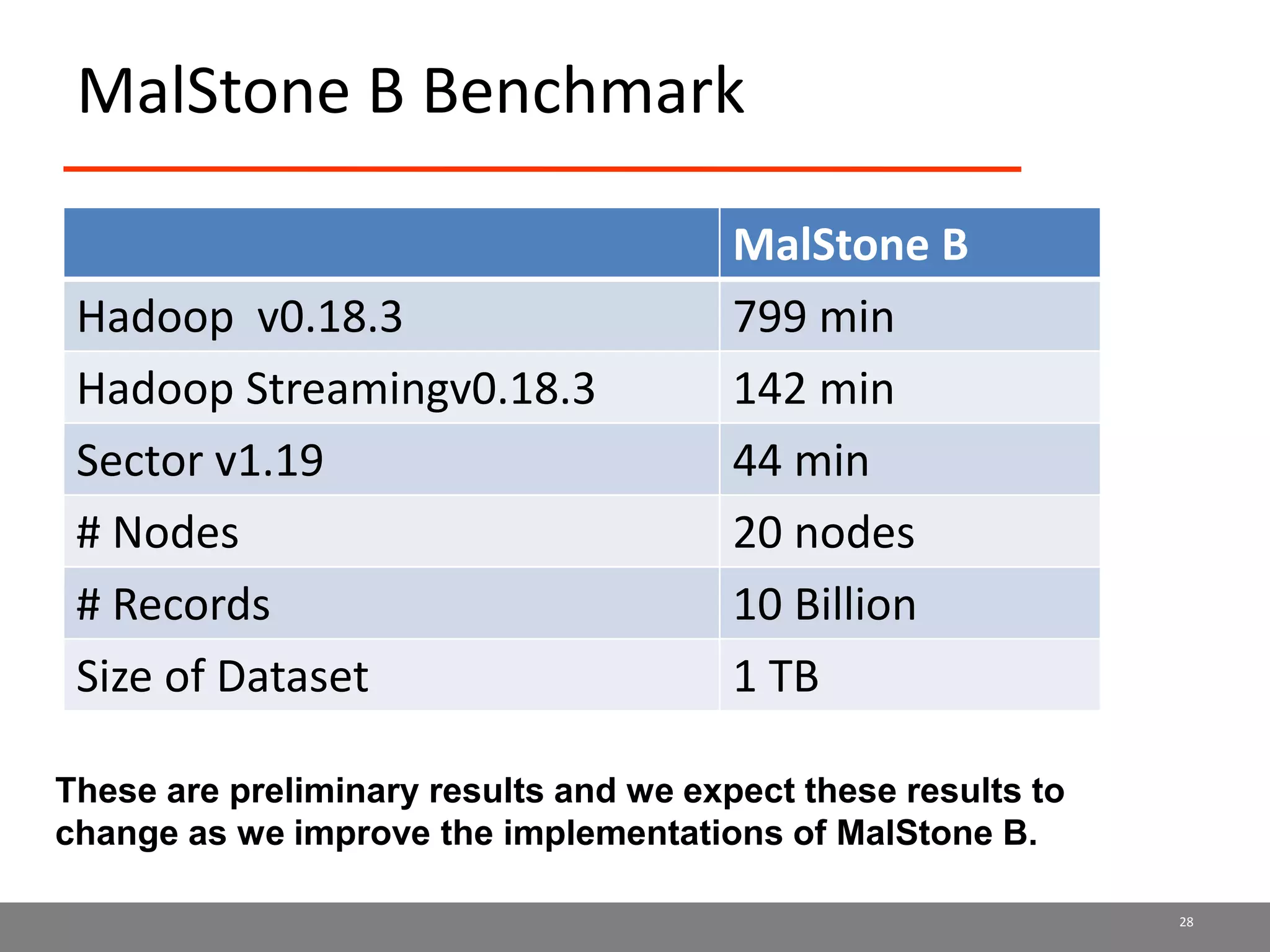
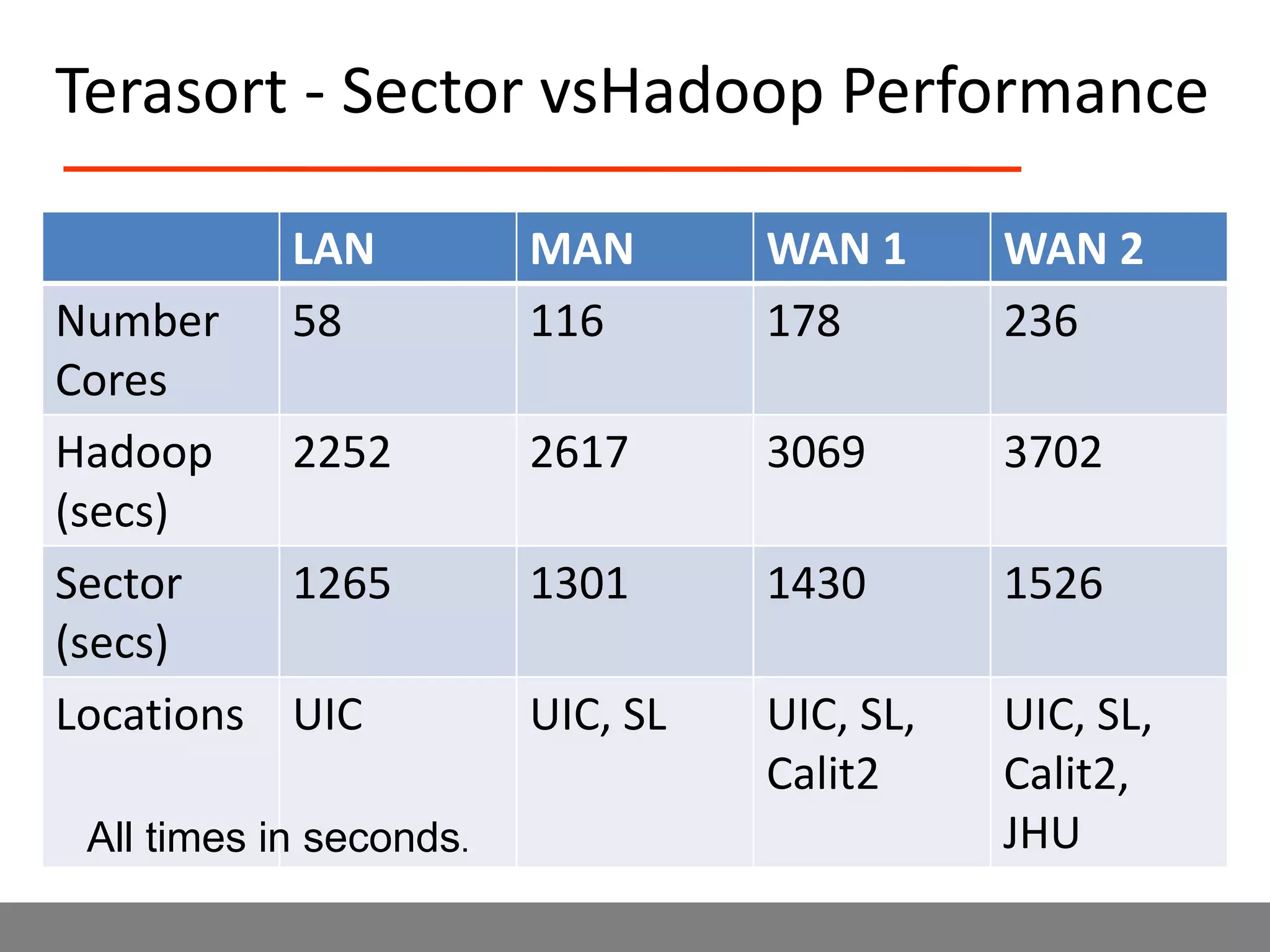





Sector is an open source cloud platform designed for data intensive computing. It provides several advantages over Hadoop such as being up to 2x faster, supporting user defined functions, and exploiting data locality and network topology. Sector uses a layered architecture with user defined functions, a distributed file system, and a UDP-based transport protocol. Experimental results show Sector outperforms Hadoop on benchmarks and has less than a 5% performance penalty compared to a local cluster when run on distributed wide area clusters connected by 10Gbps networks.




















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


