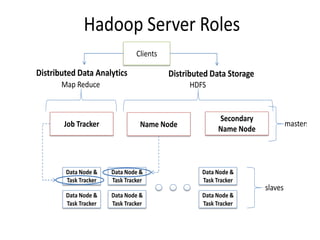
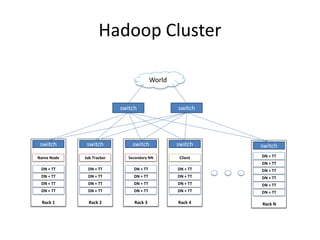
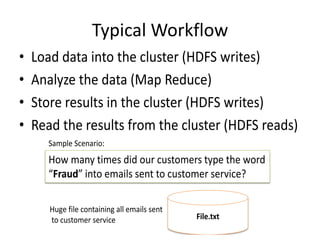
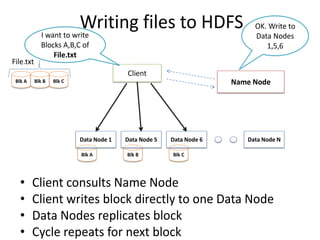
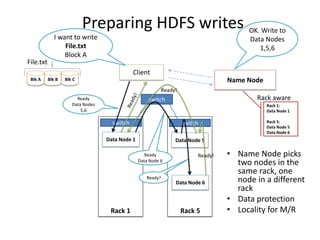
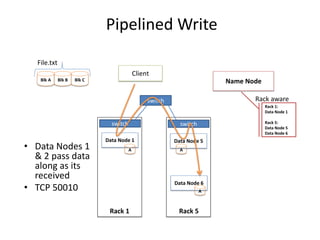
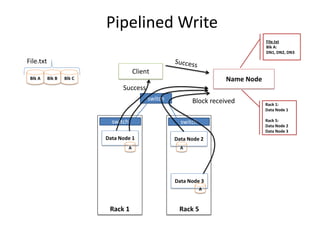
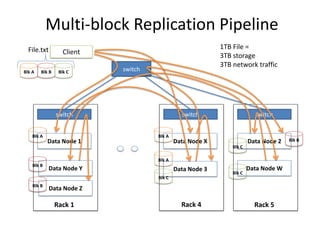
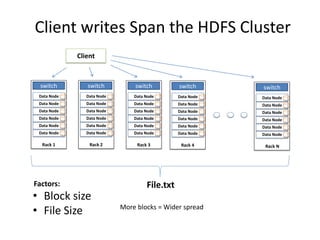
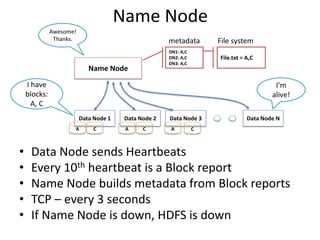
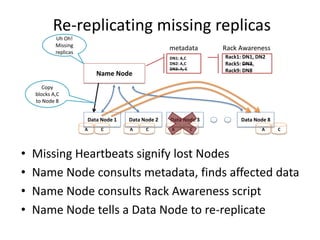
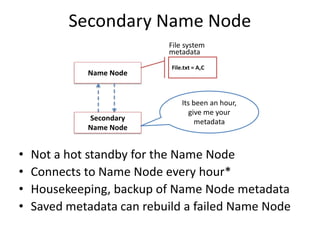
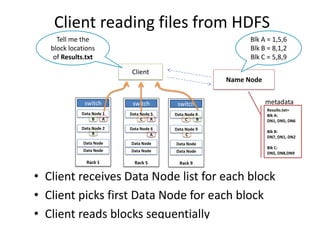
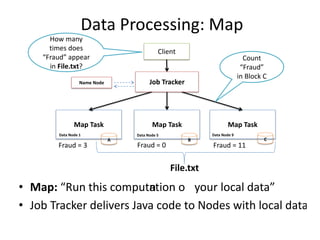
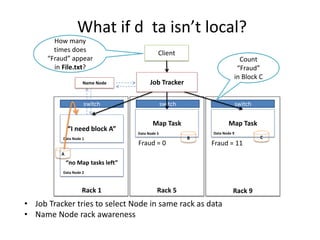
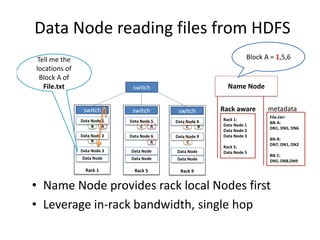
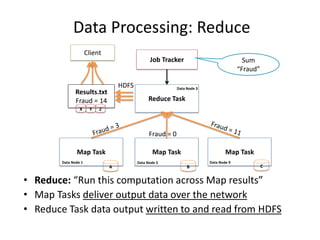
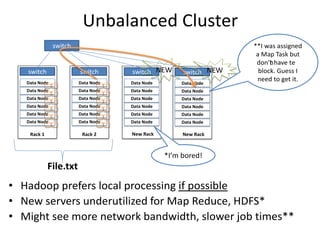
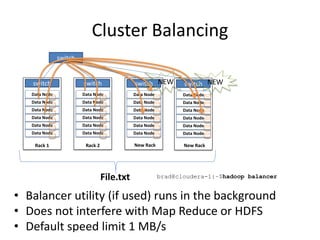
Hadoop is an open source framework for distributed storage and processing of large datasets across commodity hardware. It has two main components - the Hadoop Distributed File System (HDFS) for storage, and MapReduce for processing. HDFS stores data across clusters in a redundant and fault-tolerant manner. MapReduce allows distributed processing of large datasets in parallel using map and reduce functions. The architecture aims to provide reliable, scalable computing using commodity hardware.