WESEEK Tech Conferenceは、株式会社WESEEKが主催するエンジニア向けの勉強会です。
WESEEKに所属するエンジニアが、様々なテーマで定期的に発表を行う予定です。
第16回目のテーマは「激白!GROWI.cloudの可用性向上の取り組み」
顧客に何らかのサービスを提供する上で、日常的なサービス可用性の維持・向上に関する業務は必須となります。
本発表では、可用性維持・向上に必要な項目を挙げつつ、弊社が実際に提供しているサービスである GROWI.cloud での実施例をご紹介いたします。
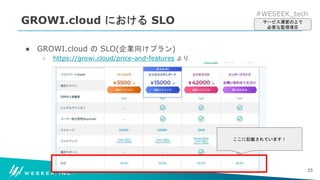
どのような形で SLO の策定に至ったのか
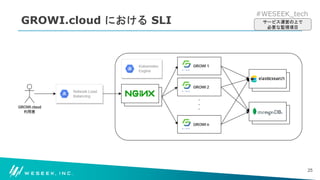
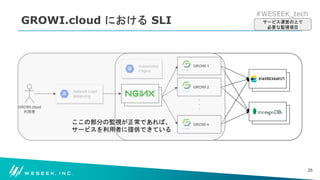
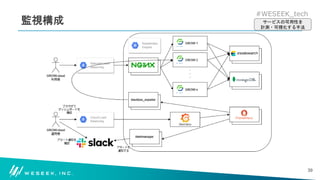
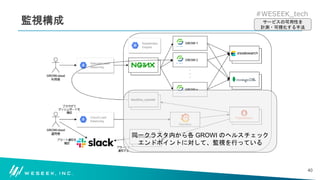
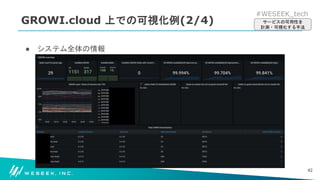
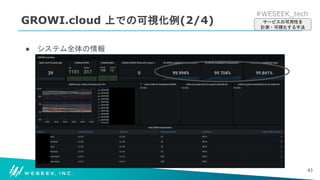
どのような構成で可用性を数値化しているのか
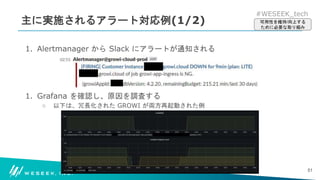
どのような業務を実施して、可用性の維持・向上を達成しているか









































































![S17_25 分でわかる!Windows 365 [Microsoft Japan Digital Days]](https://cdn.slidesharecdn.com/ss_thumbnails/s1725windows365-211028201849-thumbnail.jpg?width=640&height=640&fit=bounds)











![[AWS Summit 2012] クラウドデザインパターン#8 CDP アンチパターン編](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-08-121001111025-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























